Narrator
1.0.0
======================================================
API dan layanan ini dibuat dengan maksud membantu pembuat konten mendapatkan deskripsi pendengaran AI yang dihasilkan dari adegan dan gambar yang dapat mereka gunakan untuk membuat konten mereka lebih mudah diakses oleh orang -orang dengan gangguan penglihatan.
API narator menghasilkan deskripsi audio untuk gambar dan video yang disediakan menggunakan dua jaringan saraf CNN-RNN yang dikembangkan di Pytorch: 1) Gambar ke jaringan deskripsi teks berdasarkan jaringan show-and-tell, dan 2) perpanjangan jaringan ini ke dalam deskripsi video ke teks. Jaringan deskripsi video juga dapat digunakan untuk menghasilkan deskripsi per adegan dalam video.
Arktitektur keseluruhan untuk narator dapat dilihat di sini: 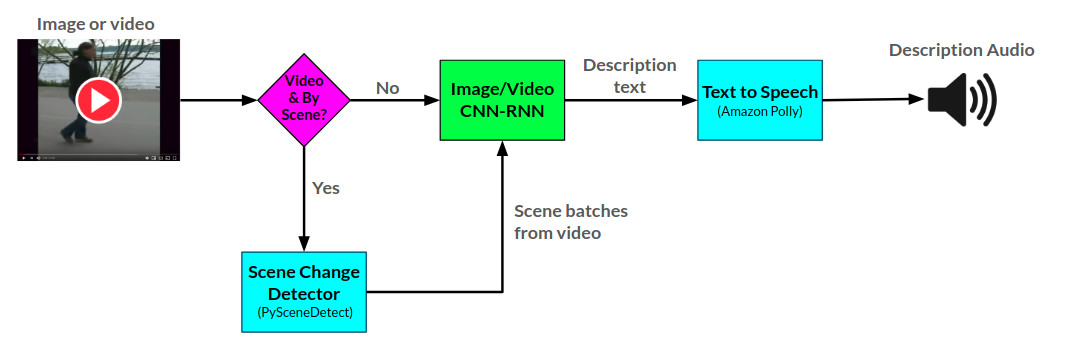
Arsitektur model deskripsi gambar dapat dilihat di sini: 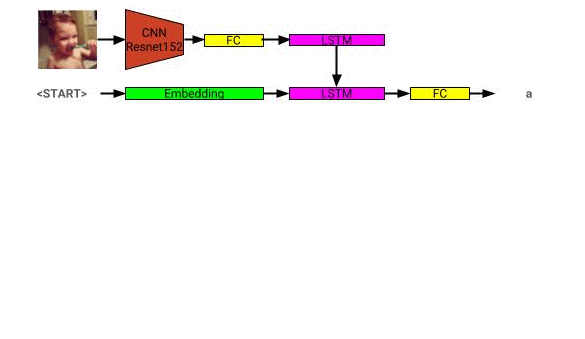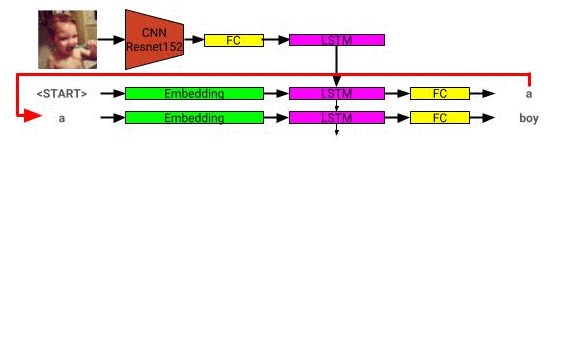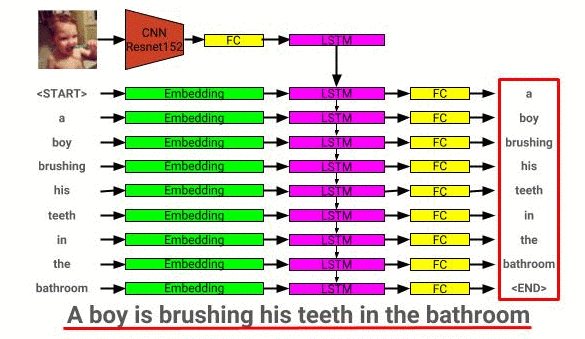
Arsitektur model deskripsi video dapat dilihat di sini: 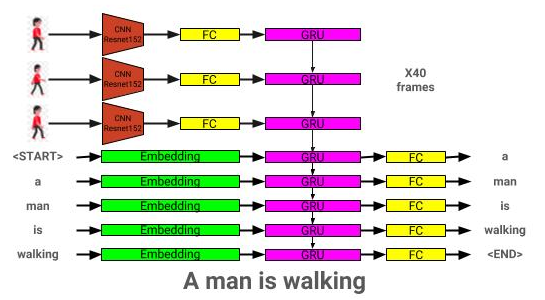
Narator saat ini dilayani dalam dua cara: 1) aplikasi web Flask yang saat ini di -host di AWS dan dilayani melalui situs web, dan 2) API mandiri: narator.py. Contoh penggunaan situs web dapat dilihat di situs web, dan contoh menggunakan API dapat dilihat di notebook/contoh penggunaan narator.ipynb.
API narator menggunakan Amazon Polly untuk menghasilkan deskripsi audio dari teks, dan pyscenedetect untuk mendeteksi perubahan adegan dalam video.
Jaringan deskripsi gambar dilatih menggunakan dataset Coco 2014.
Jaringan deskripsi video dilatih menggunakan dataset MSR-VTT.
Model deskripsi gambar pra-terlatih terbaik saat ini dapat diunduh dari sini.
Model deskripsi video pra-terlatih terbaik saat ini dapat diunduh dari sini.
Tempatkan model -model ini di direktori model.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
Ketergantungan dapat diunduh menggunakan:
pip install -r requirements.txt
| Arsitektur | CNN | Inisialisasi | Tamak | Balok = 3 |
|---|---|---|---|---|
| LSTM (Embed: 256) | Resnet152 | Acak | 0.123 | 0.132 |
| Gru (Embed: 256) | Resnet152 | Acak | 0.122 | 0.131 |
| LSTM (Embed: 256) | VGG16 | Acak | 0.108 | 0.117 |
| Arsitektur | CNN | Inisialisasi | Tamak | Balok = 3 |
|---|---|---|---|---|
| Gru (Embed: 256) | Resnet152 | Acak | 0.317 | 0.351 |
| LSTM (Embed: 256) | Resnet152 | Acak | 0.305 | 0.320 |
| LSTM (Embed: 256) | VGG16 | Acak | 0.283 | 0.318 |
| LSTM (Embed: 512) | Resnet152 | Acak | 0.270 | 0.317 |
| LSTM (Embed: 256) | Resnet152 | Coco pra-terlatih | 0.278 | 0.310 |
Bagian ini akan menunjukkan bagaimana seseorang dapat melatih model deskripsi gambar mereka sendiri.
Pertama, gambar dan keterangan dataset Coco perlu diproses untuk pelatihan.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
--coco_path: Path to Cocoapi Path (dapat mengunduh dari sini)
--Interm_results_path: jalur untuk menyimpan hasil sementara (default: data/interim/)
---results_path: jalur untuk menyimpan hasil akhir (default: data/diproses/)
Ini juga menyimpan dataset teks gabungan di <coco_path> /notations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: Path to Cocoapi Path (dapat mengunduh dari sini)
--vocab_path: jalur untuk menyimpan kosakata coco (default ke data/olahan/coco_vocab.pkl)
--Threshold: Min Word Occurance yang akan ditambahkan ke kosa kata (default: 5)
--Sets: Coco Set untuk memasukkan dalam konstruksi kosa kata (default: 'train2014', 'train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-Model: Model CNN dasar untuk digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_bn','bn ',', ',' vgg19_bn ','bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg16,' vgg16, 'Densenet121', 'Densenet201', 'Inception'])
--DR: Path to Coco Images to Encode Menggunakan Model yang Dipilih
--continue_processing: encode gambar yang tersisa di direktori
File yang dikodekan akan ditempatkan di DIR.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--odels_path: jalur untuk menyimpan model akhir (default: model/)
-Beam_Size: Ukuran balok untuk validasi (default: 3)
--vocab_path: Path to Coco Vocab (default: data/olesed/coco_vocab.pkl)
--capsions_path: jalur ke coco captions (default: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: jalur ke coco iamges (default: os.environ ['home'] + '/database/coco/gambar/')
---lr: tingkat pembelajaran untuk digunakan (default: 0,001)
--val_interval: frekuensi zaman validasi (default: 10)
--Save_interval: Simpan frekuensi zaman pos pemeriksaan (default: 10)
---num_epochs: Jumlah zaman yang akan dilatih (default: 1000)
--initial_checkpoint_file: CHECKPOINT untuk memulai pelatihan dari (default: tidak ada)
--Version: Nomor Versi Model (Default: 11)
--Bot_Size: ukuran batch (default: 64)
--COCO_SET: Dataset Coco untuk dilatih dengan (default: 2014)
---load_features: Opsi untuk memuat atau membangun embeddings gambar (default: true)
---load_captions: Opsi untuk memuat atau membangun embeddings keterangan (default: true)
--Preload: Opsi untuk memuat data ke memori sistem sebelum pelatihan (default: true)
--BASE_MODEL: Model CNN dasar yang akan digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_', 'vgg16_bn', 'vgg19', 'vgg16_bn', 'vgg16_bn', 'vgg16_bn', 'vgg16,' vgg16, 'vgg16,' vgg16, 'vgg16,' vgg11 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: ukuran embedding gambar (default: 2048)
--EMBED_SIZE: Ukuran input RNN (default: 256)
--sembah_size: ukuran lapisan tersembunyi RNN (default: 512)
--RNN_TYPE: RNN TYPE (default: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--odel_path: jalur ke model IC terlatih
-Beam_Size: Ukuran balok untuk validasi
--vocab_path: Path to Coco Vocab (default: data/olesed/coco_vocab.pkl)
--capsions_path: jalur ke coco captions (default: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: jalur ke gambar coco (default: os.environ ['home'] + '/database/coco/gambar/')
--Bot_Size: ukuran batch (default: 64)
--COCO_SET: Dataset Coco untuk dilatih dengan (default: 2014)
---load_features: Opsi untuk memuat atau membangun embeddings gambar (default: true)
---load_captions: Opsi untuk memuat atau membangun embeddings keterangan (default: true)
--Preload: Opsi untuk memuat data ke memori sistem sebelum pelatihan (default: true)
--BASE_MODEL: Model CNN dasar yang akan digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_', 'vgg16_bn', 'vgg19', 'vgg16_bn', 'vgg16_bn', 'vgg16_bn', 'vgg16,' vgg16, 'vgg16,' vgg16, 'vgg16,' vgg11 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: ukuran embedding gambar (default: 2048)
--EMBED_SIZE: Ukuran input RNN (default: 256)
--sembah_size: ukuran lapisan tersembunyi RNN (default: 512)
--RNN_TYPE: RNN TYPE (default: 'lstm')
Bagian ini akan menunjukkan bagaimana seseorang dapat melatih model deskripsi video mereka sendiri.
Pertama, video dan keterangan Dataset MSR-VTT perlu diproses untuk pelatihan.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
---raw_data_path: jalur ke file data msrvtt mentah (default: 'data/mentah/videodatainfo_2017_ustc.json')
--terterim_data_path: jalur untuk menyimpan hasil sementara (default: 'data/interim/')
--final_data_path: jalur untuk menyimpan hasil akhir (default: 'data/diproses/')
--continue_convertting: path untuk melanjutkan mengonversi dataset msr-vtt (default: true)
--TRAIN_PCT: Persentase dataset yang akan digunakan untuk pelatihan (default: 0.8)
--Dev_PCT: Persentase dataset yang akan digunakan untuk pengembangan (default: 0,15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: jalur ke keterangan msr-vtt yang dihasilkan oleh make_msrvtt_dataset.py (default: 'data/diproses/msrvtt_captions.csv')
--vocab_path: jalur untuk menyimpan kosa kata MSR-VTT (default ke data/olahan/msrvtt_vocab.pkl)
--Threshold: Min Word Occurance yang akan ditambahkan ke kosa kata (default: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-Model: Model CNN dasar untuk digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_bn','bn ',', ',' vgg19_bn ','bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg16,' vgg16, 'Densenet121', 'Densenet201', 'Inception'])
--DR: Path to MSR-VTT Video untuk mengkode menggunakan model yang dipilih (default: os.environ ['home'] + '/database/msr-vtt/train-video/')
--continue_processing: Encode video yang tersisa di direktori (default: true)
-Resolusi: Resolusi Input CNN (Default: 224)
---num_frames: Jumlah frame untuk dikodekan (default: 40)
--frames_interval: Interval antar frame (default: 1)
--EMBEDDING_SIZE: CNN ouput Resolution (default: 2048)
File yang dikodekan akan ditempatkan di DIR.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--odels_path: jalur untuk menyimpan model akhir (default: model/)
-Beam_Size: Ukuran balok untuk validasi (default: 3)
--vocab_path: jalur ke vocab msr-vtt (default: data/diproses/msrvtt_vocab.pkl)
--captions_path: Path to MSR-VTT Captions (default: data/diproses/msrvtt_captions.csv)
--videos_path: Path to MSR-VTT Video (default: os.environ ['home'] + '/database/msr-vtt/train-video/')
---lr: tingkat pembelajaran untuk digunakan (default: 0,001)
--val_interval: frekuensi zaman validasi (default: 10)
--Save_interval: Simpan frekuensi zaman pos pemeriksaan (default: 10)
---num_epochs: Jumlah zaman yang akan dilatih (default: 1000)
--initial_checkpoint_file: CHECKPOINT untuk memulai pelatihan dari (default: tidak ada)
--Version: Nomor Versi Model (Default: 11)
--Bot_Size: ukuran batch (default: 64)
---load_features: Opsi untuk memuat atau membangun embeddings video (default: true)
---load_captions: Opsi untuk memuat atau membangun embeddings keterangan (default: true)
--Preload: Opsi untuk memuat data ke memori sistem sebelum pelatihan (default: true)
--BASE_MODEL: Model CNN dasar yang akan digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_', 'vgg16_bn', 'vgg19', 'vgg16_bn', 'vgg16_bn', 'vgg16_bn', 'vgg16,' vgg16, 'vgg16,' vgg16, 'vgg16,' vgg11 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: ukuran embedding bingkai (default: 2048)
--EMBED_SIZE: Ukuran input RNN (default: 256)
--sembah_size: ukuran lapisan tersembunyi RNN (default: 512)
--RNN_TYPE: RNN TYPE (default: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
---podel_path: Path to To Latih Video Description Model
-Beam_Size: Ukuran balok untuk validasi
--vocab_path: jalur ke vocab msr-vtt (default: data/diproses/msrvtt_vocab.pkl)
--captions_path: Path to MSR-VTT Captions (default: data/diproses/msrvtt_captions.csv)
--videos_path: Path to MSR-VTT Video (default: os.environ ['home'] + '/database/msr-vtt/train-video/')
--Bot_Size: ukuran batch (default: 64)
---load_features: Opsi untuk memuat atau membangun embeddings video (default: true)
---load_captions: Opsi untuk memuat atau membangun embeddings keterangan (default: true)
--Preload: Opsi untuk memuat data ke memori sistem sebelum pelatihan (default: true)
--BASE_MODEL: Model CNN dasar yang akan digunakan untuk preprocessing (opsi: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19', 'vgg16_bn', 'vgg19', 'vgg19_', 'vgg16_bn', 'vgg19', 'vgg16_bn', 'vgg16_bn', 'vgg16_bn', 'vgg16,' vgg16, 'vgg16,' vgg16, 'vgg16,' vgg11 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: ukuran embedding bingkai (default: 2048)
--EMBED_SIZE: Ukuran input RNN (default: 256)
--sembah_size: ukuran lapisan tersembunyi RNN (default: 512)
--RNN_TYPE: RNN TYPE (default: 'lstm')


