Narrator
1.0.0
==========================================================
このAPIとサービスは、コンテンツクリエイターがAIが生成されたシーンや画像の聴覚記述を、視力障害のある人がコンテンツをよりアクセスしやすくするのを支援することを目的として作成されました。
ナレーターAPIは、Pytorchで開発された2つのCNN-RNNニューラルネットワークを使用して、提供された画像とビデオのオーディオ説明を生成します。ビデオ説明ネットワークをさらに使用して、ビデオでシーンごとの説明を生成できます。
ナレーターの全体的なアンチテクチャはここで見ることができます: 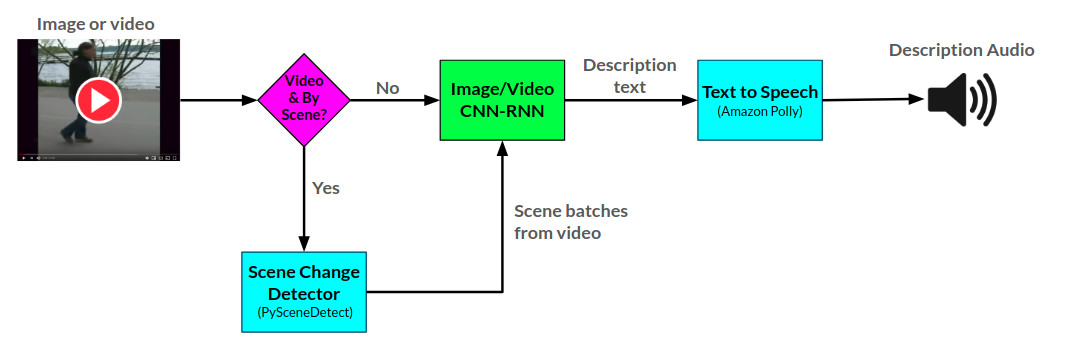
画像説明モデルアーキテクチャはここで見ることができます: 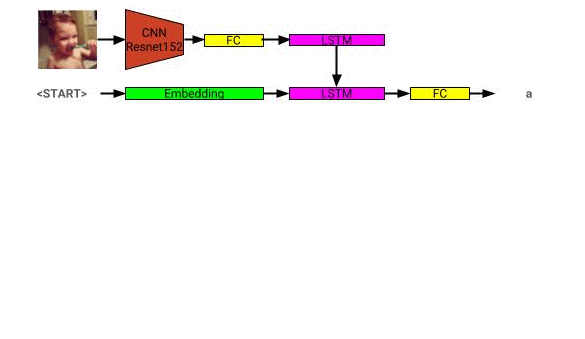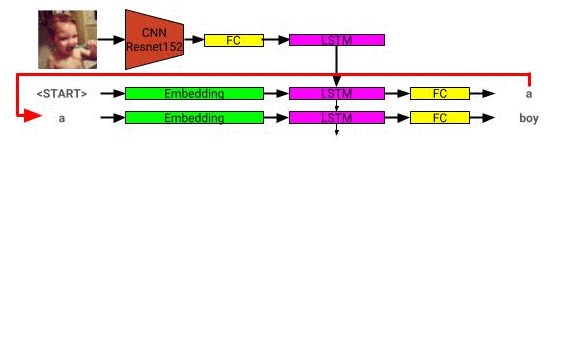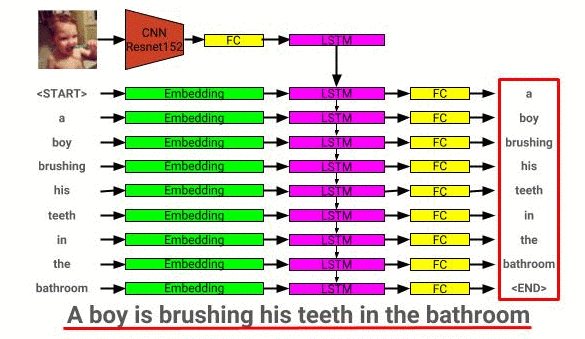
ビデオ説明モデルアーキテクチャはここで見ることができます: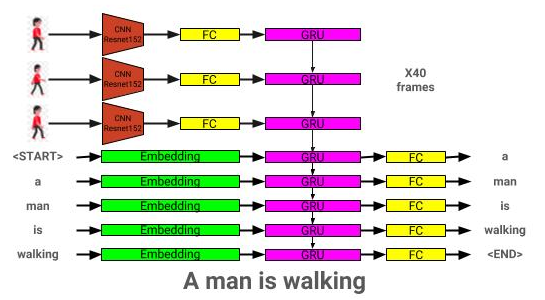
ナレーターは現在、2つの方法で提供されています。1)現在AWSでホストされており、ウェブサイトを介して提供されているフラスコのWebアプリ、および2)スタンドアロンAPI:natrator.py。 Webサイトの使用例はWebサイトで見ることができ、APIを使用する例は、ノートブック/ナレーターの使用例で見ることができます。Ipynb。
ナレーターAPIは、Amazon Pollyを使用してテキストからオーディオ説明を生成し、ビデオ内のシーンの変更を検出するためにPySceneTeCtectを生成します。
画像説明ネットワークは、COCO 2014データセットを使用してトレーニングされています。
ビデオ説明ネットワークは、MSR-VTTデータセットを使用してトレーニングされています。
現在の最高の事前に訓練された画像説明モデルは、こちらからダウンロードできます。
現在の最高の事前に訓練されたビデオ説明モデルは、こちらからダウンロードできます。
これらのモデルをモデルディレクトリに配置します。
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
依存関係は以下を使用してダウンロードできます。
pip install -r requirements.txt
| 建築 | CNN | 初期化 | よく深い | ビーム= 3 |
|---|---|---|---|---|
| LSTM(埋め込み:256) | ResNet152 | ランダム | 0.123 | 0.132 |
| Gru(埋め込み:256) | ResNet152 | ランダム | 0.122 | 0.131 |
| LSTM(埋め込み:256) | VGG16 | ランダム | 0.108 | 0.117 |
| 建築 | CNN | 初期化 | よく深い | ビーム= 3 |
|---|---|---|---|---|
| Gru(埋め込み:256) | ResNet152 | ランダム | 0.317 | 0.351 |
| LSTM(埋め込み:256) | ResNet152 | ランダム | 0.305 | 0.320 |
| LSTM(埋め込み:256) | VGG16 | ランダム | 0.283 | 0.318 |
| LSTM(埋め込み:512) | ResNet152 | ランダム | 0.270 | 0.317 |
| LSTM(埋め込み:256) | ResNet152 | 事前に訓練されたココ | 0.278 | 0.310 |
このセクションでは、独自の画像説明モデルをトレーニングする方法を示します。
まず、COCOデータセットの画像とキャプションをトレーニングに前処理する必要があります。
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-COCO_PATH:Cocoapi Pathへのパス(こちらからダウンロードできます)
-interm_results_path:暫定結果を保存するためのパス(デフォルト:データ/暫定/)
-results_path:最終結果を保存するパス(デフォルト:データ/処理済み/)
これにより、<coco_path>/annotations/coco_captions.csvに複合キャプションデータセットが保存されます。
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-COCO_PATH:Cocoapi Pathへのパス(こちらからダウンロードできます)
-vocab_path:coco vocabularyを保存するパス(デフォルトはデータ/processed/coco_vocab.pklにデフォルト)
-Threshold:語彙に追加される最小単語の発生(デフォルト:5)
- セット:ココセットは語彙建設に含める(デフォルト: 'train2014'、 'train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
- モデル:前処理に使用するベースCNNモデル(オプション:['resnet18' '、' resnet50 '、' resnet152 '、' vgg11 '、' vgg11_bn '、' vgg16 '、' vgg16_bn '、' vgg19 '、' vgg19_bn '' sqeezenet0 ''、 'figezenet0'、 'densenet121'、 'densenet201'、 'Inception'])
-DIR:選択したモデルを使用してエンコードするココ画像へのパス
-Continue_Processing:ディレクトリ内の残りの画像をエンコードします
エンコードされたファイルはdirに配置されます。
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path:最終モデルを保存するパス(デフォルト:モデル/)
-beam_size:検証用のビームサイズ(デフォルト:3)
-vocab_path:coco vocabへのパス(デフォルト:data/processed/coco_vocab.pkl)
-CAPTIONS_PATH:COCOキャプションへのパス(デフォルト:OS.ENVIRON ['HOME'] + '/Programs/cocoapi/Annotations/coco_captions.csv')
-images_path:coco iamgesへのパス(デフォルト:os.environ ['home'] + '/database/coco/images/')
-LR:使用する学習率(デフォルト:0.001)
-val_interval:検証エポック周波数(デフォルト:10)
-save_interval:チェックポイントエポック周波数を保存(デフォルト:10)
-NUM_EPOCHS:トレーニングするエポックの数(デフォルト:1000)
-initial_checkpoint_file:トレーニングを開始するためのチェックポイント(デフォルト:なし)
- バージョン:モデルバージョン番号(デフォルト:11)
-batch_size:バッチサイズ(デフォルト:64)
-COCO_SET:TRAIN(デフォルト:2014)を訓練するココデータセット
-load_features:画像埋め込みをロードまたは構築するオプション(デフォルト:true)
-load_captions:キャプション埋め込みをロードまたは構築するオプション(デフォルト:true)
-PRELOAD:トレーニング前にデータをシステムメモリにプリロードするオプション(デフォルト:TRUE)
-base_model:前処理に使用するベースCNNモデル(オプション:['resnet18'、 'resnet50'、 'resnet152'、 'vgg11'、 'vgg11_bn'、 'vgg16'、 'vgg16_bn'、 'vgg19'、 'vgg19_bn'、 'figezenet0'、 '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' feezezenet0 '、 'densenet121'、 'densenet201'、 'Inception'])
-embedding_size:画像埋め込みのサイズ(デフォルト:2048)
-embed_size:RNN入力のサイズ(デフォルト:256)
-hidden_size:RNN隠されたレイヤーのサイズ(デフォルト:512)
-RNN_TYPE:RNNタイプ(デフォルト: 'LSTM')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path:訓練されたICモデルへのパス
-beam_size:検証用のビームサイズ
-vocab_path:coco vocabへのパス(デフォルト:data/processed/coco_vocab.pkl)
-CAPTIONS_PATH:COCOキャプションへのパス(デフォルト:OS.ENVIRON ['HOME'] + '/Programs/cocoapi/Annotations/coco_captions.csv')
-images_path:coco画像へのパス(デフォルト:os.environ ['home'] + '/database/coco/images/')
-batch_size:バッチサイズ(デフォルト:64)
-COCO_SET:TRAIN(デフォルト:2014)を訓練するココデータセット
-load_features:画像埋め込みをロードまたは構築するオプション(デフォルト:true)
-load_captions:キャプション埋め込みをロードまたは構築するオプション(デフォルト:true)
-PRELOAD:トレーニング前にデータをシステムメモリにプリロードするオプション(デフォルト:TRUE)
-base_model:前処理に使用するベースCNNモデル(オプション:['resnet18'、 'resnet50'、 'resnet152'、 'vgg11'、 'vgg11_bn'、 'vgg16'、 'vgg16_bn'、 'vgg19'、 'vgg19_bn'、 'figezenet0'、 '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' feezezenet0 '、 'densenet121'、 'densenet201'、 'Inception'])
-embedding_size:画像埋め込みのサイズ(デフォルト:2048)
-embed_size:RNN入力のサイズ(デフォルト:256)
-hidden_size:RNN隠されたレイヤーのサイズ(デフォルト:512)
-RNN_TYPE:RNNタイプ(デフォルト: 'LSTM')
このセクションでは、自分のビデオ説明モデルをトレーニングする方法を示します。
まず、MSR-VTTデータセットのビデオとキャプションをトレーニング用に前処理する必要があります。
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
-RAW_DATA_PATH:RAW MSRVTTデータファイルへのパス(デフォルト: 'data/raw/videodatainfo_2017_ustc.json')
-interim_data_path:暫定結果を保存するためのパス(デフォルト: 'data/interim/')
--final_data_path:最終結果を保存するパス(デフォルト: 'data/processed/')
--Continue_Converting:MSR-VTTデータセットの変換を続けるパス(デフォルト:true)
-train_pct:トレーニングに使用するデータセットの割合(デフォルト:0.8)
-DEV_PCT:開発に使用するデータセットの割合(デフォルト:0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path: make_msrvtt_dataset.pyによって生成されたmsr-vttキャプションへのパス(デフォルト: 'data/processed/msrvtt_captions.csv')
-vocab_path:msr-vtt語彙を保存するためのパス(デフォルトはdata/processed/msrvtt_vocab.pkl)
-Threshold:語彙に追加される最小単語の発生(デフォルト:5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
- モデル:前処理に使用するベースCNNモデル(オプション:['resnet18' '、' resnet50 '、' resnet152 '、' vgg11 '、' vgg11_bn '、' vgg16 '、' vgg16_bn '、' vgg19 '、' vgg19_bn '' sqeezenet0 ''、 'figezenet0'、 'densenet121'、 'densenet201'、 'Inception'])
-DIR:選択したモデルを使用してエンコードするMSR-VTTビデオへのパス(デフォルト:os.environ ['home'] + '/database/msr-vtt/train-video/')
--Continue_Processing:ディレクトリで残りのビデオをエンコードする(デフォルト:true)
- 分解:CNN入力解像度(デフォルト:224)
-num_frames:エンコードするフレーム数(デフォルト:40)
- frames_interval:フレーム間の間隔(デフォルト:1)
-embedding_size:CNN OUPUT Resolution(デフォルト:2048)
エンコードされたファイルはdirに配置されます。
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path:最終モデルを保存するパス(デフォルト:モデル/)
-beam_size:検証用のビームサイズ(デフォルト:3)
-vocab_path:msr-vtt vocabへのパス(デフォルト:data/processed/msrvtt_vocab.pkl)
-CAPTIONS_PATH:MSR-VTTキャプションへのパス(デフォルト:data/processed/msrvtt_captions.csv)
-videos_path:msr-vttビデオへのパス(デフォルト:os.environ ['home'] + '/database/msr-vtt/train-video/')
-LR:使用する学習率(デフォルト:0.001)
-val_interval:検証エポック周波数(デフォルト:10)
-save_interval:チェックポイントエポック周波数を保存(デフォルト:10)
-NUM_EPOCHS:トレーニングするエポックの数(デフォルト:1000)
-initial_checkpoint_file:トレーニングを開始するためのチェックポイント(デフォルト:なし)
- バージョン:モデルバージョン番号(デフォルト:11)
-batch_size:バッチサイズ(デフォルト:64)
-load_features:ビデオ埋め込みをロードまたは構築するオプション(デフォルト:true)
-load_captions:キャプション埋め込みをロードまたは構築するオプション(デフォルト:true)
-PRELOAD:トレーニング前にデータをシステムメモリにプリロードするオプション(デフォルト:TRUE)
-base_model:前処理に使用するベースCNNモデル(オプション:['resnet18'、 'resnet50'、 'resnet152'、 'vgg11'、 'vgg11_bn'、 'vgg16'、 'vgg16_bn'、 'vgg19'、 'vgg19_bn'、 'figezenet0'、 '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' feezezenet0 '、 'densenet121'、 'densenet201'、 'Inception'])
-embedding_size:フレーム埋め込みのサイズ(デフォルト:2048)
-embed_size:RNN入力のサイズ(デフォルト:256)
-hidden_size:RNN隠されたレイヤーのサイズ(デフォルト:512)
-RNN_TYPE:RNNタイプ(デフォルト: 'LSTM')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--Model_Path:トレーニングされたビデオ説明モデルへのパス
-beam_size:検証用のビームサイズ
-vocab_path:msr-vtt vocabへのパス(デフォルト:data/processed/msrvtt_vocab.pkl)
-CAPTIONS_PATH:MSR-VTTキャプションへのパス(デフォルト:data/processed/msrvtt_captions.csv)
-videos_path:msr-vttビデオへのパス(デフォルト:os.environ ['home'] + '/database/msr-vtt/train-video/')
-batch_size:バッチサイズ(デフォルト:64)
-load_features:ビデオ埋め込みをロードまたは構築するオプション(デフォルト:true)
-load_captions:キャプション埋め込みをロードまたは構築するオプション(デフォルト:true)
-PRELOAD:トレーニング前にデータをシステムメモリにプリロードするオプション(デフォルト:TRUE)
-base_model:前処理に使用するベースCNNモデル(オプション:['resnet18'、 'resnet50'、 'resnet152'、 'vgg11'、 'vgg11_bn'、 'vgg16'、 'vgg16_bn'、 'vgg19'、 'vgg19_bn'、 'figezenet0'、 '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' '' feezezenet0 '、 'densenet121'、 'densenet201'、 'Inception'])
-embedding_size:フレーム埋め込みのサイズ(デフォルト:2048)
-embed_size:RNN入力のサイズ(デフォルト:256)
-hidden_size:RNN隠されたレイヤーのサイズ(デフォルト:512)
-RNN_TYPE:RNNタイプ(デフォルト: 'LSTM')


