Narrator
1.0.0
-
API และบริการนี้ถูกสร้างขึ้นด้วยความตั้งใจที่จะช่วยให้ผู้สร้างเนื้อหาได้รับคำอธิบายการได้ยินของ AI ของฉากและรูปภาพที่พวกเขาสามารถใช้เพื่อให้เนื้อหาของพวกเขาเข้าถึงได้มากขึ้นสำหรับผู้ที่มีการมองเห็นการมองเห็น
ผู้บรรยาย API สร้างคำอธิบายเสียงสำหรับรูปภาพและวิดีโอที่ให้ไว้โดยใช้เครือข่ายประสาท CNN-RNN สองเครือข่ายที่พัฒนาขึ้นใน Pytorch: 1) ภาพไปยังเครือข่ายคำอธิบายข้อความตามเครือข่ายแสดงและขายและ 2) ส่วนขยายของเครือข่ายนี้เป็นวิดีโอไปยังคำอธิบายข้อความ เครือข่ายคำอธิบายวิดีโอสามารถใช้เพิ่มเติมเพื่อสร้างคำอธิบายต่อฉากในวิดีโอ
สามารถดู Arctitecture สำหรับผู้บรรยายได้ที่นี่: 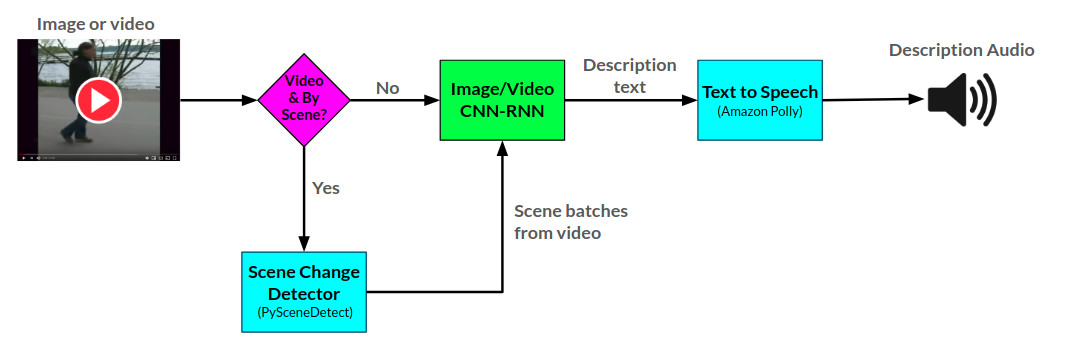
คำอธิบายภาพสถาปัตยกรรมแบบจำลองสามารถดูได้ที่นี่: 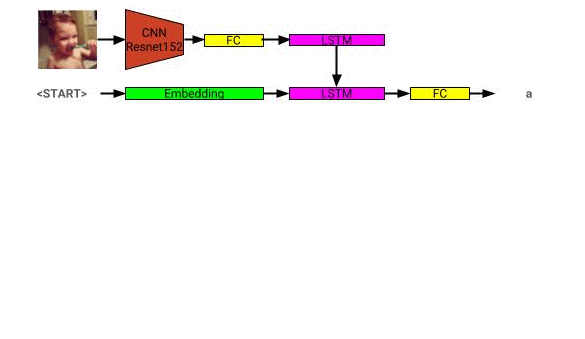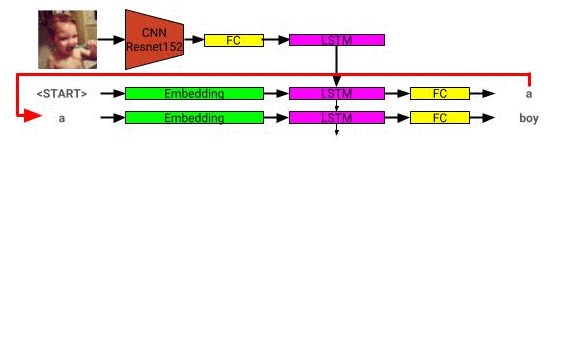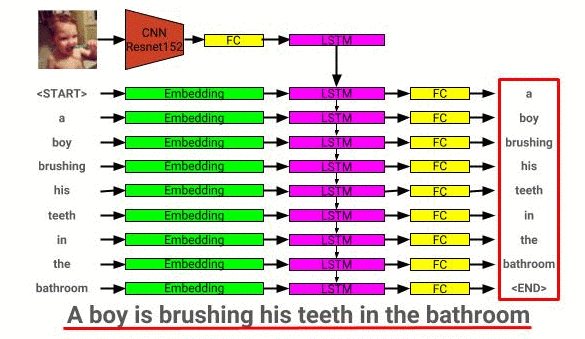
สามารถดูสถาปัตยกรรมโมเดลวิดีโอได้ที่นี่: 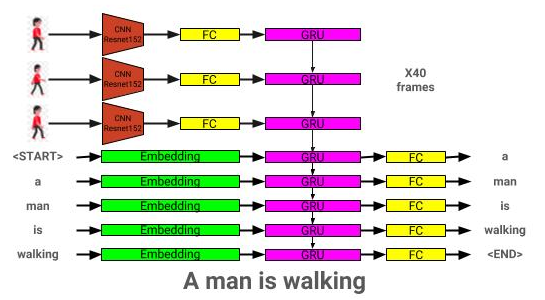
ขณะนี้ผู้บรรยายให้บริการในสองวิธี: 1) แอพพลิเคชั่นบนเว็บในปัจจุบันกำลังโฮสต์บน AWS และให้บริการผ่านเว็บไซต์และ 2) A API แบบสแตนด์อโลน: ผู้บรรยาย ตัวอย่างการใช้งานเว็บไซต์สามารถดูได้บนเว็บไซต์และตัวอย่างของการใช้ API สามารถดูได้ในตัวอย่างการใช้โน้ตบุ๊ก/ผู้บรรยาย
API ผู้บรรยายใช้ Amazon Polly เพื่อสร้างคำอธิบายเสียงจากข้อความและ Pyscenedetect สำหรับการตรวจจับการเปลี่ยนแปลงฉากภายในวิดีโอ
เครือข่ายคำอธิบายภาพได้รับการฝึกฝนโดยใช้ชุดข้อมูล Coco 2014
เครือข่ายคำอธิบายวิดีโอได้รับการฝึกฝนโดยใช้ชุดข้อมูล MSR-VTT
รูปแบบคำอธิบายภาพที่ผ่านการฝึกอบรมล่วงหน้าที่ดีที่สุดในปัจจุบันสามารถดาวน์โหลดได้จากที่นี่
โมเดลคำอธิบายวิดีโอที่ได้รับการฝึกอบรมล่วงหน้าที่ดีที่สุดในปัจจุบันสามารถดาวน์โหลดได้จากที่นี่
วางโมเดลเหล่านี้ไว้ในไดเรกทอรีโมเดล
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
การพึ่งพาสามารถดาวน์โหลดได้โดยใช้:
pip install -r requirements.txt
| สถาปัตยกรรม | ซีเอ็นเอ็น | การเริ่มต้น | โลภ | ลำแสง = 3 |
|---|---|---|---|---|
| LSTM (ฝัง: 256) | Resnet152 | แบบสุ่ม | 0.123 | 0.132 |
| GRU (ฝัง: 256) | Resnet152 | แบบสุ่ม | 0.122 | 0.131 |
| LSTM (ฝัง: 256) | VGG16 | แบบสุ่ม | 0.108 | 0.117 |
| สถาปัตยกรรม | ซีเอ็นเอ็น | การเริ่มต้น | โลภ | ลำแสง = 3 |
|---|---|---|---|---|
| GRU (ฝัง: 256) | Resnet152 | แบบสุ่ม | 0.317 | 0.351 |
| LSTM (ฝัง: 256) | Resnet152 | แบบสุ่ม | 0.305 | 0.320 |
| LSTM (ฝัง: 256) | VGG16 | แบบสุ่ม | 0.283 | 0.318 |
| LSTM (ฝัง: 512) | Resnet152 | แบบสุ่ม | 0.270 | 0.317 |
| LSTM (ฝัง: 256) | Resnet152 | Coco ที่ผ่านการฝึกอบรมมาก่อน | 0.278 | 0.310 |
ส่วนนี้จะแสดงให้เห็นว่าเราสามารถฝึกอบรมรูปแบบคำอธิบายภาพของตนเองได้อย่างไร
ก่อนอื่นต้องมีการประมวลผลภาพชุดข้อมูล COCO สำหรับการฝึกอบรมล่วงหน้า
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-COCO_PATH: PATH TO COCOAPI PATH (สามารถดาวน์โหลดได้จากที่นี่)
-interm_results_path: พา ธ ไปเก็บผลลัพธ์ระหว่างกาล (ค่าเริ่มต้น: ข้อมูล/ระหว่างกาล/)
-results_path: เส้นทางไปเก็บผลลัพธ์สุดท้าย (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/)
นอกจากนี้ยังเก็บชุดข้อมูลคำอธิบายภาพรวมใน <Coco_Path> /annotations/coco_captions.csv
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-COCO_PATH: PATH TO COCOAPI PATH (สามารถดาวน์โหลดได้จากที่นี่)
-vocab_path: Path to Store Coco Vocabulary (ค่าเริ่มต้นเป็นข้อมูล/ประมวลผล/coco_vocab.pkl)
-threshold: การเพิ่มคำพูดในคำศัพท์ (ค่าเริ่มต้น: 5)
-ชุด: ชุด Coco ที่จะรวมในการก่อสร้างคำศัพท์ (ค่าเริ่มต้น: 'Train2014', 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-โมเดล: รุ่น CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn' 'Densenet121', 'Densenet201', 'Inception'])))
--dir: Path to Coco Images เพื่อเข้ารหัสโดยใช้รุ่นที่เลือก
--continue_processing: เข้ารหัสภาพที่เหลืออยู่ในไดเรกทอรี
ไฟล์ที่เข้ารหัสจะถูกวางไว้ใน DIR
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-MODELS_PATH: PATH to Store Model สุดท้าย (ค่าเริ่มต้น: Models/)
-beam_size: ขนาดลำแสงสำหรับการตรวจสอบ (ค่าเริ่มต้น: 3)
-vocab_path: Path to Coco Vocab (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/coco_vocab.pkl)
--captions_path: Path to Coco Captions (ค่าเริ่มต้น: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-Images_path: Path to Coco Iamges (ค่าเริ่มต้น: OS.environ ['Home'] + '/ฐานข้อมูล/Coco/Images/')
-LR: อัตราการเรียนรู้ที่จะใช้ (ค่าเริ่มต้น: 0.001)
-VAL_INTERVAL: การตรวจสอบความถี่ EPOCH (ค่าเริ่มต้น: 10)
-SAVE_INTERVAL: บันทึกความถี่ EPOCH POCTION POINTION (ค่าเริ่มต้น: 10)
-NUM_EPOCHS: จำนวนยุคที่จะฝึกอบรม (ค่าเริ่มต้น: 1000)
-initial_checkpoint_file: จุดตรวจเพื่อเริ่มการฝึกอบรมจาก (ค่าเริ่มต้น: ไม่มี)
-Version: หมายเลขรุ่นรุ่น (ค่าเริ่มต้น: 11)
--batch_size: ขนาดแบทช์ (ค่าเริ่มต้น: 64)
-COCO_SET: ชุดข้อมูล Coco เพื่อฝึกด้วย (ค่าเริ่มต้น: 2014)
-load_features: ตัวเลือกในการโหลดหรือสร้าง image embeddings (ค่าเริ่มต้น: จริง)
-LOAD_CAPTIONS: ตัวเลือกในการโหลดหรือสร้างคำอธิบายภาพฝังตัว (ค่าเริ่มต้น: จริง)
-PRELOAD: ตัวเลือกในการโหลดข้อมูลล่วงหน้าไปยังหน่วยความจำระบบก่อนการฝึกอบรม (ค่าเริ่มต้น: จริง)
--base_model: โมเดล CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19_bn 'Densenet121', 'Densenet201', 'Inception'])))
-embedding_size: ขนาดของการฝังภาพ (ค่าเริ่มต้น: 2048)
-EMBED_SIZE: ขนาดของอินพุต RNN (ค่าเริ่มต้น: 256)
-hidden_size: ขนาดของเลเยอร์ที่ซ่อน RNN (ค่าเริ่มต้น: 512)
-rnn_type: ประเภท rnn (ค่าเริ่มต้น: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-MODEL_PATH: PATH ไปยังแบบจำลอง IC ที่ผ่านการฝึกอบรม
-beam_size: ขนาดลำแสงสำหรับการตรวจสอบ
-vocab_path: Path to Coco Vocab (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/coco_vocab.pkl)
--captions_path: Path to Coco Captions (ค่าเริ่มต้น: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-Images_path: Path to Coco Images (ค่าเริ่มต้น: OS.environ ['Home'] + '/Database/Coco/Images/')
--batch_size: ขนาดแบทช์ (ค่าเริ่มต้น: 64)
-COCO_SET: ชุดข้อมูล Coco เพื่อฝึกด้วย (ค่าเริ่มต้น: 2014)
-load_features: ตัวเลือกในการโหลดหรือสร้าง image embeddings (ค่าเริ่มต้น: จริง)
-LOAD_CAPTIONS: ตัวเลือกในการโหลดหรือสร้างคำอธิบายภาพฝังตัว (ค่าเริ่มต้น: จริง)
-PRELOAD: ตัวเลือกในการโหลดข้อมูลล่วงหน้าไปยังหน่วยความจำระบบก่อนการฝึกอบรม (ค่าเริ่มต้น: จริง)
--base_model: โมเดล CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19_bn 'Densenet121', 'Densenet201', 'Inception'])))
-embedding_size: ขนาดของการฝังภาพ (ค่าเริ่มต้น: 2048)
-EMBED_SIZE: ขนาดของอินพุต RNN (ค่าเริ่มต้น: 256)
-hidden_size: ขนาดของเลเยอร์ที่ซ่อน RNN (ค่าเริ่มต้น: 512)
-rnn_type: ประเภท rnn (ค่าเริ่มต้น: 'lstm')
ส่วนนี้จะแสดงให้เห็นว่าเราสามารถฝึกอบรมโมเดลวิดีโอคำอธิบายของตัวเองได้อย่างไร
ขั้นแรกวิดีโอชุดข้อมูลและคำอธิบายภาพ MSR-VTT จำเป็นต้องได้รับการประมวลผลล่วงหน้าสำหรับการฝึกอบรม
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
-RAW_DATA_PATH: PATH ไปยังไฟล์ข้อมูล RAW MSRVTT (ค่าเริ่มต้น: 'data/RAW/VideodatainFO_2017_ustc.json')
-interim_data_path: Path to Storage ผลลัพธ์ระหว่างกาล (ค่าเริ่มต้น: 'data/interim/')
--final_data_path: Path to Story ผลลัพธ์สุดท้าย (ค่าเริ่มต้น: 'data/processed/')
-CONTINUE_CONVERTING: PATH เพื่อดำเนินการแปลงชุดข้อมูล MSR-VTT ต่อไป (ค่าเริ่มต้น: จริง)
-TRAIN_PCT: เปอร์เซ็นต์ของชุดข้อมูลที่จะใช้สำหรับการฝึกอบรม (ค่าเริ่มต้น: 0.8)
-Dev_pct: เปอร์เซ็นต์ของชุดข้อมูลที่จะใช้สำหรับการพัฒนา (ค่าเริ่มต้น: 0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-COCO_Path: PATH ไปยังคำอธิบายภาพ MSR-VTT ที่สร้างโดย make_msrvtt_dataset.py (ค่าเริ่มต้น: 'ข้อมูล/ประมวลผล/MSRVTT_CAPTIONS.CSV')
-VOCAB_PATH: PATH to Store MSR-VTT คำศัพท์ (ค่าเริ่มต้นเป็นข้อมูล/ประมวลผล/MSRVTT_VOCAB.PKL)
-threshold: การเพิ่มคำพูดในคำศัพท์ (ค่าเริ่มต้น: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-โมเดล: รุ่น CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn' 'Densenet121', 'Densenet201', 'Inception'])))
--dir: พา ธ ไปยังวิดีโอ MSR-VTT เพื่อเข้ารหัสโดยใช้โมเดลที่เลือก (ค่าเริ่มต้น: os.environ ['home'] + '/database/msr-vtt/train-video/')
-CONTINUE_PROCESSING: เข้ารหัสวิดีโอที่เหลืออยู่ในไดเรกทอรี (ค่าเริ่มต้น: จริง)
-ความละเอียด: ความละเอียดอินพุต CNN (ค่าเริ่มต้น: 224)
-NUM_FRAMES: จำนวนเฟรมที่จะเข้ารหัส (ค่าเริ่มต้น: 40)
-frames_interval: ช่วงเวลาระหว่างเฟรม (ค่าเริ่มต้น: 1)
-embedding_size: ความละเอียด CNN ouput (ค่าเริ่มต้น: 2048)
ไฟล์ที่เข้ารหัสจะถูกวางไว้ใน DIR
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-MODELS_PATH: PATH to Store Model สุดท้าย (ค่าเริ่มต้น: Models/)
-beam_size: ขนาดลำแสงสำหรับการตรวจสอบ (ค่าเริ่มต้น: 3)
-vocab_path: Path ไปยัง MSR-VTT คำศัพท์ (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/msrvtt_vocab.pkl)
-Captions_Path: Path ไปยัง MSR-VTT คำอธิบาย (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/MSRVTT_CAPTIONS.CSV)
-videos_path: Path ไปยังวิดีโอ MSR-VTT (ค่าเริ่มต้น: os.environ ['home'] + '/database/msr-vtt/train-video/')
-LR: อัตราการเรียนรู้ที่จะใช้ (ค่าเริ่มต้น: 0.001)
-VAL_INTERVAL: การตรวจสอบความถี่ EPOCH (ค่าเริ่มต้น: 10)
-SAVE_INTERVAL: บันทึกความถี่ EPOCH POCTION POINTION (ค่าเริ่มต้น: 10)
-NUM_EPOCHS: จำนวนยุคที่จะฝึกอบรม (ค่าเริ่มต้น: 1000)
-initial_checkpoint_file: จุดตรวจเพื่อเริ่มการฝึกอบรมจาก (ค่าเริ่มต้น: ไม่มี)
-Version: หมายเลขรุ่นรุ่น (ค่าเริ่มต้น: 11)
--batch_size: ขนาดแบทช์ (ค่าเริ่มต้น: 64)
-load_features: ตัวเลือกในการโหลดหรือสร้าง embeddings วิดีโอ (ค่าเริ่มต้น: จริง)
-LOAD_CAPTIONS: ตัวเลือกในการโหลดหรือสร้างคำอธิบายภาพฝังตัว (ค่าเริ่มต้น: จริง)
-PRELOAD: ตัวเลือกในการโหลดข้อมูลล่วงหน้าไปยังหน่วยความจำระบบก่อนการฝึกอบรม (ค่าเริ่มต้น: จริง)
--base_model: โมเดล CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19_bn 'Densenet121', 'Densenet201', 'Inception'])))
-embedding_size: ขนาดของการฝังเฟรม (ค่าเริ่มต้น: 2048)
-EMBED_SIZE: ขนาดของอินพุต RNN (ค่าเริ่มต้น: 256)
-hidden_size: ขนาดของเลเยอร์ที่ซ่อน RNN (ค่าเริ่มต้น: 512)
-rnn_type: ประเภท rnn (ค่าเริ่มต้น: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-MODEL_PATH: PATH TO TO TRAINED VIDEALE Model Model
-beam_size: ขนาดลำแสงสำหรับการตรวจสอบ
-vocab_path: Path ไปยัง MSR-VTT คำศัพท์ (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/msrvtt_vocab.pkl)
-Captions_Path: Path ไปยัง MSR-VTT คำอธิบาย (ค่าเริ่มต้น: ข้อมูล/ประมวลผล/MSRVTT_CAPTIONS.CSV)
-videos_path: Path ไปยังวิดีโอ MSR-VTT (ค่าเริ่มต้น: os.environ ['home'] + '/database/msr-vtt/train-video/')
--batch_size: ขนาดแบทช์ (ค่าเริ่มต้น: 64)
-load_features: ตัวเลือกในการโหลดหรือสร้าง embeddings วิดีโอ (ค่าเริ่มต้น: จริง)
-LOAD_CAPTIONS: ตัวเลือกในการโหลดหรือสร้างคำอธิบายภาพฝังตัว (ค่าเริ่มต้น: จริง)
-PRELOAD: ตัวเลือกในการโหลดข้อมูลล่วงหน้าไปยังหน่วยความจำระบบก่อนการฝึกอบรม (ค่าเริ่มต้น: จริง)
--base_model: โมเดล CNN พื้นฐานที่จะใช้สำหรับการประมวลผลล่วงหน้า (ตัวเลือก: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19_bn 'Densenet121', 'Densenet201', 'Inception'])))
-embedding_size: ขนาดของการฝังเฟรม (ค่าเริ่มต้น: 2048)
-EMBED_SIZE: ขนาดของอินพุต RNN (ค่าเริ่มต้น: 256)
-hidden_size: ขนาดของเลเยอร์ที่ซ่อน RNN (ค่าเริ่มต้น: 512)
-rnn_type: ประเภท rnn (ค่าเริ่มต้น: 'lstm')


