Narrator
1.0.0
=========================================================
Diese API und dieser Service wurde erstellt, um die Ersteller von Inhalten zu helfen, die KI -generierten auditorischen Beschreibungen von Szenen und Bildern zu erstellen, mit denen sie ihre Inhalte für Menschen mit Sehbehinderung zugänglicher machen können.
Die Erzähler-API generiert Audiobeschreibungen für bereitgestellte Bilder und Videos unter Verwendung von zwei in Pytorch entwickelten CNN-RNN-Netzwerken: 1) Ein auf dem Show-and-Tell-Netzwerk basierendes Bild von Bildbeschreibung und 2) eine Erweiterung dieses Netzwerks in Video-to-Text-Beschreibung. Das Video Beschreibung Netzwerk kann zusätzlich verwendet werden, um Beschreibungen pro Szene in einem Video zu generieren.
Die allgemeine Arktitektur für den Erzähler ist hier zu sehen: 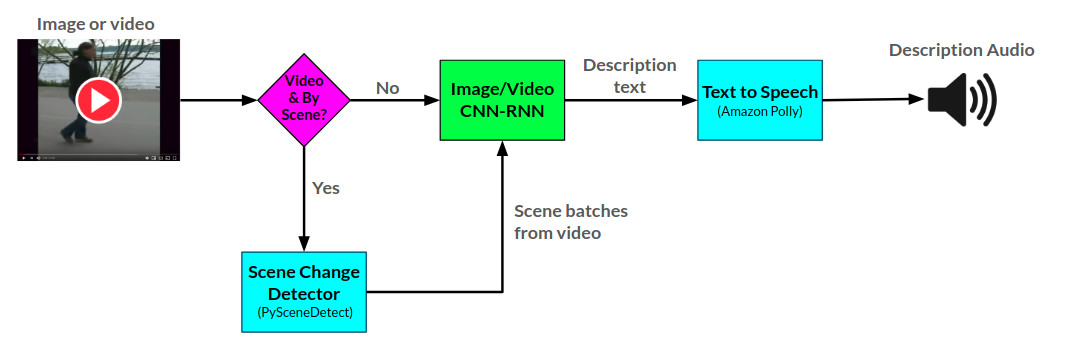
Die Bildbeschreibungsmodellarchitektur ist hier zu sehen: 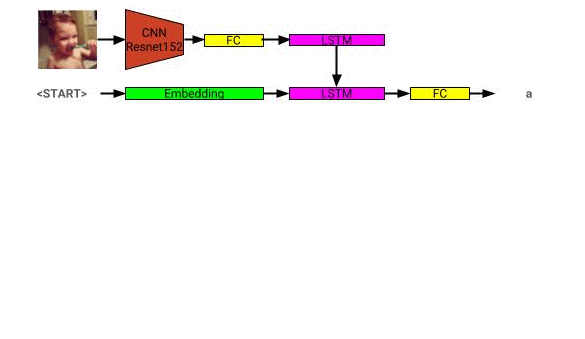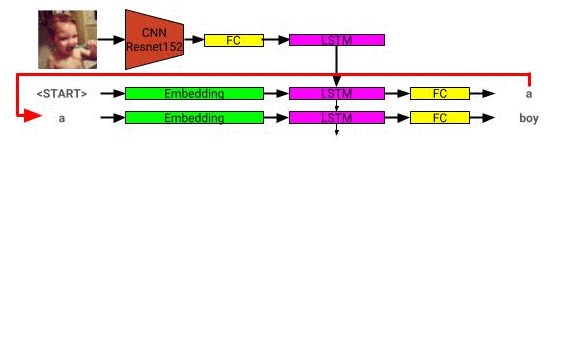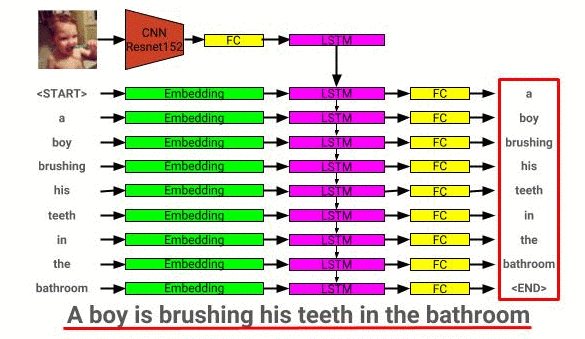
Die Videobeschreibungsmodellarchitektur ist hier zu sehen: 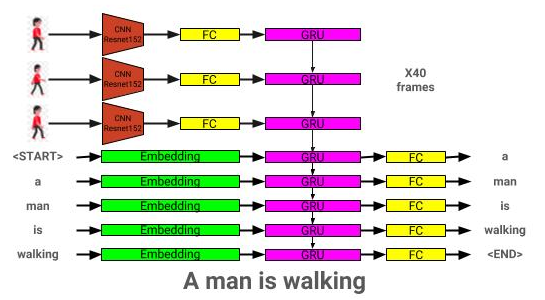
Der Erzähler wird derzeit auf zwei Arten bedient: 1) Eine Flask -Web -App wird derzeit auf AWS gehostet und über eine Website und 2) eine eigenständige API: Erzähler.py. Beispiele für die Nutzung der Website finden Sie auf der Website, und Beispiele für die Verwendung der API finden Sie in Beispielen für Notizbücher/Erzähler.
Die Erzähler -API verwendet Amazon Polly, um Audiobeschreibungen aus Text zu generieren, und pyscenedEtect zum Erkennen von Szenenänderungen in einem Video.
Das Bildbeschreibungsnetzwerk wird mit dem Coco 2014 -Datensatz trainiert.
Das Videobeschreibungsnetzwerk wird mit dem MSR-VTT-Datensatz trainiert.
Das aktuell beste Modellbeschreibungsmodell für vorgeborene Bild kann von hier heruntergeladen werden.
Das aktuell beste Modellbeschreibungsmodell für die beste ausgebildete Video kann von hier heruntergeladen werden.
Platzieren Sie diese Modelle in das Modelsverzeichnis.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
Die Abhängigkeiten können mit:
pip install -r requirements.txt
| Architektur | CNN | Initialisierung | Gierig | Strahl = 3 |
|---|---|---|---|---|
| LSTM (Einbett: 256) | Resnet152 | Zufällig | 0,123 | 0,132 |
| Gru (Einbett: 256) | Resnet152 | Zufällig | 0,122 | 0,131 |
| LSTM (Einbett: 256) | VGG16 | Zufällig | 0,108 | 0,117 |
| Architektur | CNN | Initialisierung | Gierig | Strahl = 3 |
|---|---|---|---|---|
| Gru (Einbett: 256) | Resnet152 | Zufällig | 0,317 | 0,351 |
| LSTM (Einbett: 256) | Resnet152 | Zufällig | 0,305 | 0,320 |
| LSTM (Einbett: 256) | VGG16 | Zufällig | 0,283 | 0,318 |
| LSTM (Einbett: 512) | Resnet152 | Zufällig | 0,270 | 0,317 |
| LSTM (Einbett: 256) | Resnet152 | PreAnt-Coco | 0,278 | 0,310 |
In diesem Abschnitt wird angezeigt, wie man sein eigenes Bildbeschreibungsmodell trainieren kann.
Zunächst müssen die Coco -Datensatzbilder und -unterschriften für das Training vorverarbeitet werden.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-coco_path: Pfad zum Cocoapi-Pfad (kann hier herunterladen)
-Bei der Speicherung von Zwischenergebnissen (Standard: Daten/Interim/)
-Results_Path: Pfad zum Speichern der Endergebnisse (Standard: Daten/verarbeitet/)
Dies speichert zusätzlich den kombinierten Bildungsdatensatz in <coco_path> /annotations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path: Pfad zum Cocoapi-Pfad (kann hier herunterladen)
-Vocab_path: Pfad zum Speichern von Coco-Vokabeln (Standardeinstellungen zu Daten/verarbeitet/coco_vocab.pkl)
-Threshold: Min-Wortaufnahme zum Wortschatz hinzugefügt (Standard: 5)
-Sets: Coco-Sets, die in den Vokabularkonstruktion enthalten sind (Standard: 'Train2014', 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--dir: Pfad zu Coco-Bildern, um mit dem ausgewählten Modell zu codieren
-Continue_processing: codieren verbleibende Bilder im Verzeichnis
Die codierten Dateien werden in DIR platziert.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Models_Path: Pfad zum Speichern des endgültigen Modells (Standard: Modelle/)
-Beam_Size: Strahlgröße für die Validierung (Standard: 3)
-Vocab_path: Pfad zum Coco-Vokab (Standard: Daten/verarbeitet/coco_vocab.pkl)
-Captions_path: Pfad zu Coco-Bildunterschriften (Standard: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv'))
--images_path: Pfad zu Coco iamges (Standard: OS.Environ ['Home'] + '/Database/Coco/Bilder/'))
--LR: Lernrate zu verwenden (Standard: 0,001)
-Val_Interval: Validation Epoch Frequenz (Standard: 10)
-SAVE_INTERVAL: Scheckpoint-EPOCH-Frequenz speichern (Standard: 10)
--Num_epochs: Anzahl der Epochen, die sie trainieren sollen (Standard: 1000)
--initial_checkpoint_file: Checkpoint zum Starten von (Standard: keine)
--version: Modellversionsnummer (Standard: 11)
--Batch_Size: Stapelgröße (Standard: 64)
-Coco_Set: Coco-Datensatz zum Training mit (Standard: 2014)
--load_Features: Option zum Laden oder Erstellen von Bildempfetten (Standard: TRUE)
--load_captions: Option zum Laden oder Konstrukt von Caption-Einbetten (Standard: TRUE)
-Preload: Option zum Vorladung von Daten in den Systemspeicher vor dem Training (Standard: TRUE)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: Größe der Bildeinbettung (Standard: 2048)
--embed_Size: Größe der RNN-Eingabe (Standard: 256)
-HIDDEN_SIZE: Größe der versteckten RNN-Schicht (Standard: 512)
--RNN_TYPE: RNN Type (Standard: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Model_Path: Pfad zum geschulten IC-Modell
-Beam_size: Strahlgröße zur Validierung
-Vocab_path: Pfad zum Coco-Vokab (Standard: Daten/verarbeitet/coco_vocab.pkl)
-Captions_path: Pfad zu Coco-Bildunterschriften (Standard: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv'))
--images_path: Pfad zu Coco-Bildern (Standard: os.environ ['home'] + '/database/coco/Bilder/'))
--Batch_Size: Stapelgröße (Standard: 64)
-Coco_Set: Coco-Datensatz zum Training mit (Standard: 2014)
--load_Features: Option zum Laden oder Erstellen von Bildempfetten (Standard: TRUE)
--load_captions: Option zum Laden oder Konstrukt von Caption-Einbetten (Standard: TRUE)
-Preload: Option zum Vorladung von Daten in den Systemspeicher vor dem Training (Standard: TRUE)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: Größe der Bildeinbettung (Standard: 2048)
--embed_Size: Größe der RNN-Eingabe (Standard: 256)
-HIDDEN_SIZE: Größe der versteckten RNN-Schicht (Standard: 512)
--RNN_TYPE: RNN Type (Standard: 'lstm')
In diesem Abschnitt wird angezeigt, wie man sein eigenes Videobeschreibung Modell trainieren kann.
Zunächst müssen die MSR-VTT-Datensatzvideos und -unterschriften für das Training vorverarbeitet werden.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
--RAW_DATA_PATH: Pfad zu RAW-MSRVTT-Datendateien (Standard: 'Data/RAW/videodatainfo_2017_ustc.json')
---interim_data_path: Pfad zum Speichern von Zwischenergebnissen (Standard: 'Daten/Interim/')
-final_data_path: Pfad zum Speichern der endgültigen Ergebnisse (Standard: 'Daten/verarbeitet/')
-Continue_Converting: Pfad, um den MSR-VTT-Datensatz weiter zu konvertieren (Standard: true)
--Train_pct: Prozentsatz des Datensatzes für das Training (Standard: 0,8)
-Dev_pct: Prozentsatz des Datensatzes für die Entwicklung (Standard: 0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path: Pfad zu MSR-VTT-Bildunterschriften, die von make_msrvtt_dataset.py generiert wurden (Standard: 'Data/verarbeitet/msrvtt_captions.csv'))
-Vocab_path: Pfad zum Speichern von MSR-VTT-Vokabular (Standardeinstellungen zu Daten/verarbeitet/msrvtt_vocab.pkl)
-Threshold: Min-Wortaufnahme zum Wortschatz hinzugefügt (Standard: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
--model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--dir: Pfad zu MSR-VTT-Videos, die mit einem ausgewählten Modell codiert werden sollen (Standard: os.environ ['Home'] + '/database/msr-vtt/train-video/')
-Continue_processing: codieren verbleibende Videos im Verzeichnis (Standard: TRUE)
-Auflösung: CNN-Eingangsauflösung (Standardeinstellung: 224)
--Num_Frames: Anzahl der zu codierenden Frames (Standard: 40)
---Frames_interval: Intervall zwischen Frames (Standard: 1)
--embedding_size: cnn ouput Auflösung (Standard: 2048)
Die codierten Dateien werden in DIR platziert.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Models_Path: Pfad zum Speichern des endgültigen Modells (Standard: Modelle/)
-Beam_Size: Strahlgröße für die Validierung (Standard: 3)
-Vocab_path: Pfad zum MSR-VTT Vocab (Standard: Daten/verarbeitet/msrvtt_vocab.pkl)
-Captions_path: Pfad zu MSR-VTT-Bildunterschriften (Standard: Daten/verarbeitet/msrvtt_captions.csv)
--videos_path: Pfad zu MSR-VTT-Videos (Standard: os.environ ['home'] + '/database/msr-vtt/train-video/'))
--LR: Lernrate zu verwenden (Standard: 0,001)
-Val_Interval: Validation Epoch Frequenz (Standard: 10)
-SAVE_INTERVAL: Scheckpoint-EPOCH-Frequenz speichern (Standard: 10)
--Num_epochs: Anzahl der Epochen, die sie trainieren sollen (Standard: 1000)
--initial_checkpoint_file: Checkpoint zum Starten von (Standard: Keine)
--version: Modellversionsnummer (Standard: 11)
--Batch_Size: Stapelgröße (Standard: 64)
--load_Features: Option zum Laden oder Konstrukt von Video-Einbettungen (Standard: TRUE)
--load_captions: Option zum Laden oder Konstrukt von Caption-Einbetten (Standard: TRUE)
-Preload: Option zum Vorladung von Daten in den Systemspeicher vor dem Training (Standard: TRUE)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: Größe der Rahmeneinbettung (Standard: 2048)
--embed_Size: Größe der RNN-Eingabe (Standard: 256)
-HIDDEN_SIZE: Größe der versteckten RNN-Schicht (Standard: 512)
--RNN_TYPE: RNN Type (Standard: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Model_Path: Pfad zum geschulten Video Beschreibung Modell
-Beam_size: Strahlgröße zur Validierung
-Vocab_path: Pfad zum MSR-VTT Vocab (Standard: Daten/verarbeitet/msrvtt_vocab.pkl)
-Captions_path: Pfad zu MSR-VTT-Bildunterschriften (Standard: Daten/verarbeitet/msrvtt_captions.csv)
--videos_path: Pfad zu MSR-VTT-Videos (Standard: os.environ ['home'] + '/database/msr-vtt/train-video/'))
--Batch_Size: Stapelgröße (Standard: 64)
--load_Features: Option zum Laden oder Konstrukt von Video-Einbettungen (Standard: TRUE)
--load_captions: Option zum Laden oder Konstrukt von Caption-Einbetten (Standard: TRUE)
-Preload: Option zum Vorladung von Daten in den Systemspeicher vor dem Training (Standard: TRUE)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: Größe der Rahmeneinbettung (Standard: 2048)
--embed_Size: Größe der RNN-Eingabe (Standard: 256)
-HIDDEN_SIZE: Größe der versteckten RNN-Schicht (Standard: 512)
--RNN_TYPE: RNN Type (Standard: 'lstm')


