Narrator
1.0.0
==============================================================================
Этот API и сервис были созданы с намерением помочь создателям контента получить ИИ, сгенерированные слуховыми описаниями сцен и изображений, которые они могут использовать, чтобы сделать свой контент более доступным для людей с нарушениями зрения.
API рассказчика генерирует описания звука для предоставленных изображений и видео с использованием двух нейронных сети CNN-RNN, разработанных в Pytorch: 1) сеть изображения к текстовым описанию, основанную на сети Show и Tell, и 2) расширение этой сети на видео на описание текста. Сеть описания видео может быть дополнительно использоваться для создания описаний на сцену в видео.
Здесь можно увидеть общую аркттектору для рассказчика: 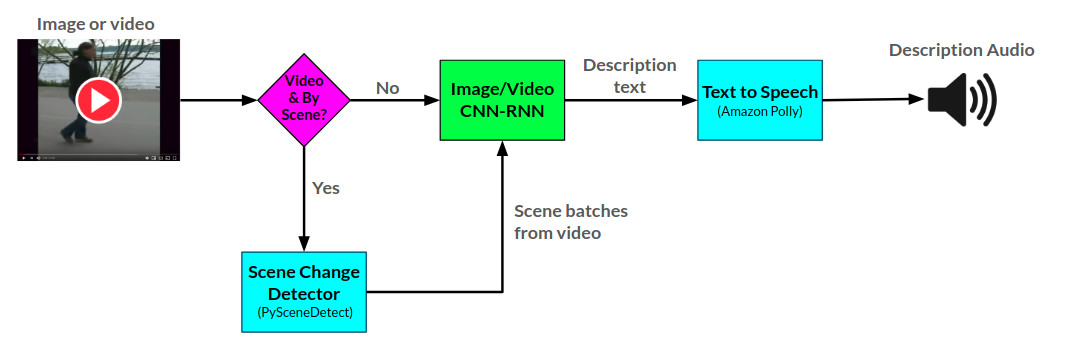
Здесь можно увидеть архитектуру модели модели изображения: 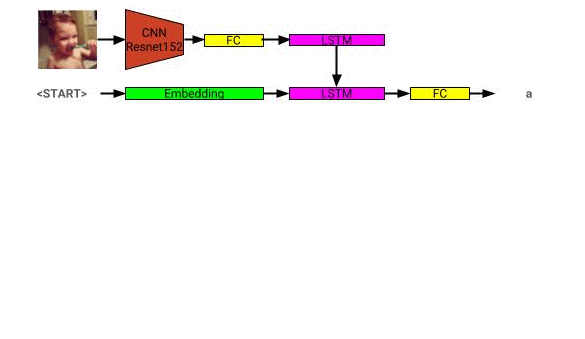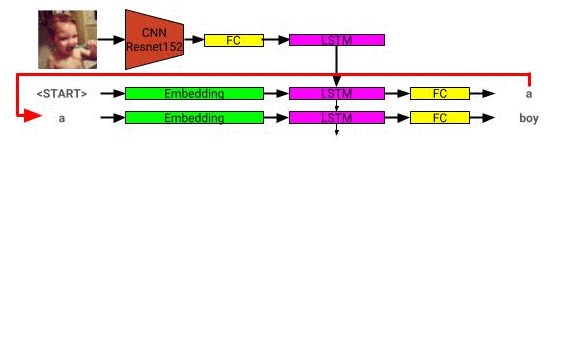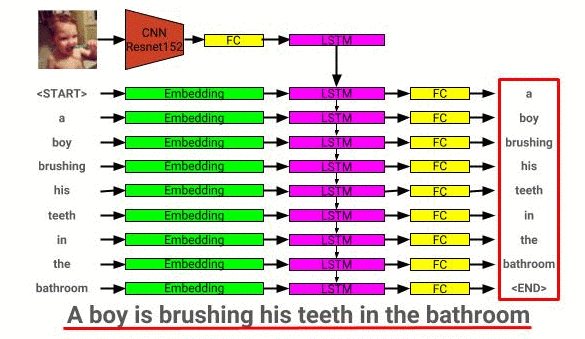
Здесь можно увидеть архитектуру модели модели видео: 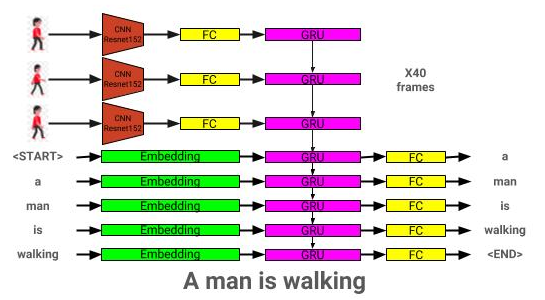
Рассказчик в настоящее время обслуживается двумя способами: 1) веб -приложение Flask, которое в настоящее время размещается на AWS и обслуживается через веб -сайт, и 2) автономный API: ourtor.py. Примеры использования веб -сайта можно увидеть на веб -сайте, и примеры использования API можно увидеть в ноутбуках/примерах использования.
API рассказчика использует Amazon Polly для генерации описаний звука из текста и pyscenedEtect для обнаружения изменений сцены в видео.
Сеть Описания изображения обучается с использованием набора данных COCO 2014.
Сеть видео-описания обучена с помощью набора данных MSR-VTT.
Текущая лучшая модель описания изображения может быть загружена отсюда.
Текущая лучшая модель описания видео может быть загружена отсюда.
Поместите эти модели в каталог моделей.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
Зависимости можно загрузить с помощью:
pip install -r requirements.txt
| Архитектура | CNN | Инициализация | Жадный | Луч = 3 |
|---|---|---|---|---|
| LSTM (Enced: 256) | Resnet152 | Случайный | 0,123 | 0,132 |
| Гру (встрадание: 256) | Resnet152 | Случайный | 0,122 | 0,131 |
| LSTM (Enced: 256) | VGG16 | Случайный | 0,108 | 0,117 |
| Архитектура | CNN | Инициализация | Жадный | Луч = 3 |
|---|---|---|---|---|
| Гру (встрадание: 256) | Resnet152 | Случайный | 0,317 | 0,351 |
| LSTM (Enced: 256) | Resnet152 | Случайный | 0,305 | 0,320 |
| LSTM (Enced: 256) | VGG16 | Случайный | 0,283 | 0,318 |
| LSTM (Enced: 512) | Resnet152 | Случайный | 0,270 | 0,317 |
| LSTM (Enced: 256) | Resnet152 | Предварительно обученный коко | 0,278 | 0,310 |
В этом разделе будет показано, как можно обучить свою собственную модель описания изображения.
Во -первых, изображения и подписи Coco должны быть предварительно обработаны для обучения.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-Coco_path: Path to Cocoapi Path (можно скачать отсюда)
--interm_results_path: Путь к хранению промежуточных результатов (по умолчанию: данные/промежуточный/)
-results_path: Путь к хранению окончательных результатов (по умолчанию: данные/обработка/)
В этом дополнительно хранится набор данных объединенных подписей в <coco_path>/anantations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-Coco_path: Path to Cocoapi Path (можно скачать отсюда)
-vocab_path: Путь к хранению кокосового словаря (по умолчанию данных/обработка/coco_vocab.pkl)
-throshold: min ord ocpaction, которое будет добавлено в словарный запас (по умолчанию: 5)
-Сетвы: Коковые наборы включают в словарный запас (по умолчанию: «Train2014», «Train2017»)
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-Модель: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0 'Densenet121', 'Densenet201', 'Начало'])
-DIR: Path to Coco Images для кодирования с использованием выбранной модели
-continue_processing: кодировать оставшиеся изображения в каталоге
Кодированные файлы будут размещены в Dir.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path: Путь к хранению окончательной модели (по умолчанию: модели/)
-beam_size: размер луча для проверки (по умолчанию: 3)
-vocab_path: Path to Coco Vocab (по умолчанию: Data/Processed/Coco_vocab.pkl)
-captions_path: Path to Coco Подпись (по умолчанию: OS.Environ ['Home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-images_path: Path to Coco iamges (по умолчанию: OS.Environ ['Home'] + '/Database/Coco/Images/')
--LR: скорость обучения для использования (по умолчанию: 0,001)
-Val_Interval: частота эпохи валидации (по умолчанию: 10)
-save_interval: Сохранить частоту эпохи контрольной точки (по умолчанию: 10)
-NUM_EPOCHS: количество эпох для обучения (по умолчанию: 1000)
-INITIAL_CHECKPOINT_FILE: Контрольная точка для начала обучения (по умолчанию: нет)
-Версия: номер версии модели (по умолчанию: 11)
-batch_size: размер партии (по умолчанию: 64)
-COCO_SET: набор данных COCO для обучения (по умолчанию: 2014)
-load_features: опция для загрузки или построения встроенных изображений (по умолчанию: true)
-load_captions: опция для загрузки или строительства подготовительной подвески (по умолчанию: true)
-Пелуаза: опция для предварительной загрузки данных в системную память перед обучением (по умолчанию: true)
-base_model: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0' 'Densenet121', 'Densenet201', 'Начало'])
-embedding_size: размер встраивания изображения (по умолчанию: 2048)
-embed_size: размер входа RNN (по умолчанию: 256)
-hidden_size: размер скрытого слоя RNN (по умолчанию: 512)
-rnn_type: rnn type (по умолчанию: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path: Путь к обученной модели IC
-beam_size: размер луча для проверки
-vocab_path: Path to Coco Vocab (по умолчанию: Data/Processed/Coco_vocab.pkl)
-captions_path: Path to Coco Подпись (по умолчанию: OS.Environ ['Home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-images_path: Path to Coco Images (по умолчанию: os.environ ['home'] + '/database/coco/images/')
-batch_size: размер партии (по умолчанию: 64)
-COCO_SET: набор данных COCO для обучения (по умолчанию: 2014)
-load_features: опция для загрузки или построения встроенных изображений (по умолчанию: true)
-load_captions: опция для загрузки или строительства подготовительной подвески (по умолчанию: true)
-Пелуаза: опция для предварительной загрузки данных в системную память перед обучением (по умолчанию: true)
-base_model: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0' 'Densenet121', 'Densenet201', 'Начало'])
-embedding_size: размер встраивания изображения (по умолчанию: 2048)
-embed_size: размер входа RNN (по умолчанию: 256)
-hidden_size: размер скрытого слоя RNN (по умолчанию: 512)
-rnn_type: rnn type (по умолчанию: 'lstm')
В этом разделе будет показано, как можно обучить свою собственную модель описания видео.
Во-первых, видео и подписи набора данных MSR-VTT должны быть предварительно обработаны для обучения.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
-RAW_DATA_PATH: PATH TO RAW MSRVTT DATA FILE
--interim_data_path: Путь к хранению промежуточных результатов (по умолчанию: 'data/interim/')
-final_data_path: Path to сохранить окончательные результаты (по умолчанию: 'Data/обработан/')
-continue_converting: путь к продолжению преобразования набора данных MSR-VTT (по умолчанию: true)
-train_pct: процент набора данных для использования для обучения (по умолчанию: 0,8)
-DEV_PCT: процент набора данных для использования для разработки (по умолчанию: 0,15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-COCO_PATH: PATH TO MSR-VTT Подпись, сгенерированные make_msrvtt_dataset.py (по умолчанию: 'DATA/PROFCEDED/MSRVTT_CAPTICES.CSV')
-vocab_path: Путь к хранению словаря MSR-VTT (по умолчанию данных/обработка/MSRVTT_VOCAB.PKL)
-throshold: min ord ocpaction, которое будет добавлено в словарный запас (по умолчанию: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-Модель: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0 'Densenet121', 'Densenet201', 'Начало'])
-DIR: Path to MSR-VTT Videos для кодирования с использованием выбранной модели (по умолчанию: OS.ENVIRON ['HOME'] + '/База данных/MSR-VTT/TRAIN-VIDEO/')
-continue_processing: кодировать оставшиеся видео в каталоге (по умолчанию: true)
-разрешение: входное разрешение CNN (по умолчанию: 224)
-Num_frames: количество кадров для кодирования (по умолчанию: 40)
-frames_interval: интервал между кадрами (по умолчанию: 1)
-embedding_size: разрешение OUPUL CNN (по умолчанию: 2048)
Кодированные файлы будут размещены в Dir.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path: Путь к хранению окончательной модели (по умолчанию: модели/)
-beam_size: размер луча для проверки (по умолчанию: 3)
-vocab_path: path to msr-vtt Vocab (по умолчанию: data/upported/msrvtt_vocab.pkl)
-captions_path: path to msr-vtt Подпись (по умолчанию: data/upported/msrvtt_captions.csv)
-videos_path: Path to MSR-VTT Videos (по умолчанию: OS.ENVIRON ['HOME'] + '/DATABASE/MSR-VTT/TRAIN-VIDEO/')
--LR: скорость обучения для использования (по умолчанию: 0,001)
-Val_Interval: частота эпохи валидации (по умолчанию: 10)
-save_interval: Сохранить частоту эпохи контрольной точки (по умолчанию: 10)
-NUM_EPOCHS: количество эпох для обучения (по умолчанию: 1000)
-INITIAL_CHECKPOINT_FILE: Контрольная точка для начала обучения (по умолчанию: нет)
-Версия: номер версии модели (по умолчанию: 11)
-batch_size: размер партии (по умолчанию: 64)
-load_features: опция для загрузки или построения видео встроений (по умолчанию: true)
-load_captions: опция для загрузки или строительства подвески.
-Пелуаза: опция для предварительной загрузки данных в системную память перед обучением (по умолчанию: true)
-base_model: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0' 'Densenet121', 'Densenet201', 'Начало'])
-embedding_size: размер встраивания кадров (по умолчанию: 2048)
-embed_size: размер входа RNN (по умолчанию: 256)
-hidden_size: размер скрытого слоя RNN (по умолчанию: 512)
-rnn_type: rnn type (по умолчанию: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path: Path to Trained Video Описание модели
-beam_size: размер луча для проверки
-vocab_path: path to msr-vtt Vocab (по умолчанию: data/upported/msrvtt_vocab.pkl)
-captions_path: path to msr-vtt Подпись (по умолчанию: data/upported/msrvtt_captions.csv)
-videos_path: Path to MSR-VTT Videos (по умолчанию: OS.ENVIRON ['HOME'] + '/DATABASE/MSR-VTT/TRAIN-VIDEO/')
-batch_size: размер партии (по умолчанию: 64)
-load_features: опция для загрузки или построения видео встроений (по умолчанию: true)
-load_captions: опция для загрузки или строительства подготовительной подвески (по умолчанию: true)
-Пелуаза: опция для предварительной загрузки данных в системную память перед обучением (по умолчанию: true)
-base_model: базовая модель CNN для использования для предварительной обработки (параметры: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'queezenet0', 'vgg19', 'vgg19_bn', 'queezenet0' 'Densenet121', 'Densenet201', 'Начало'])
-embedding_size: размер встраивания кадров (по умолчанию: 2048)
-embed_size: размер входа RNN (по умолчанию: 256)
-hidden_size: размер скрытого слоя RNN (по умолчанию: 512)
-rnn_type: rnn type (по умолчанию: 'lstm')


