Narrator
1.0.0
=====================================================
이 API와 서비스는 콘텐츠 제작자가 시력 장애가있는 사람들이 콘텐츠에 더 액세스 할 수 있도록 사용할 수있는 장면 및 이미지에 대한 AI 청각 설명을 생성하도록 돕기 위해 만들어졌습니다.
해설자 API는 Pytorch에서 개발 된 두 개의 CNN-RNN 신경망을 사용하여 제공된 이미지 및 비디오에 대한 오디오 설명을 생성합니다. 1) Show-and Tell 네트워크를 기반으로 한 이미지 to 텍스트 설명 네트워크 및 2)이 네트워크를 비디오로 텍스트 설명으로 확장합니다. 비디오 설명 네트워크를 추가로 사용하여 비디오에서 장면 당 설명을 생성 할 수 있습니다.
내레이터를위한 전반적인 아크 타이터는 다음과 같습니다. 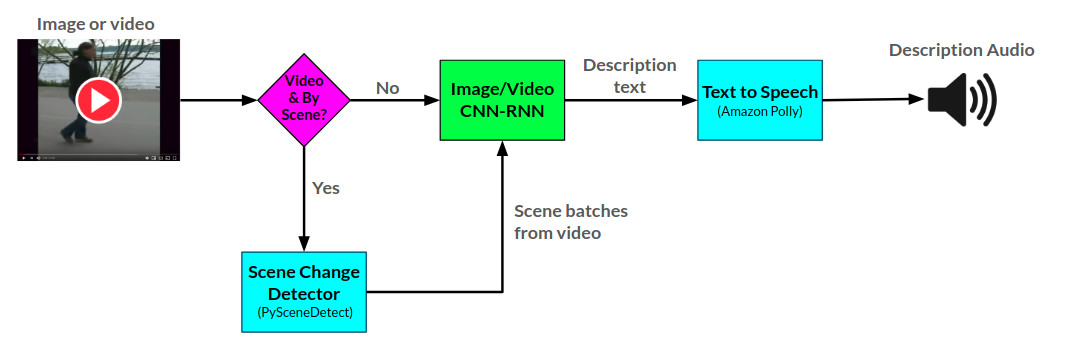
이미지 설명 모델 아키텍처는 여기에서 볼 수 있습니다. 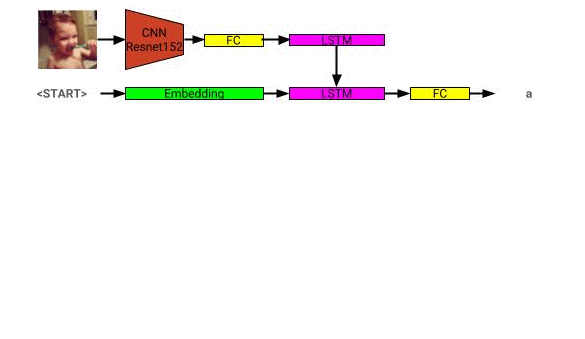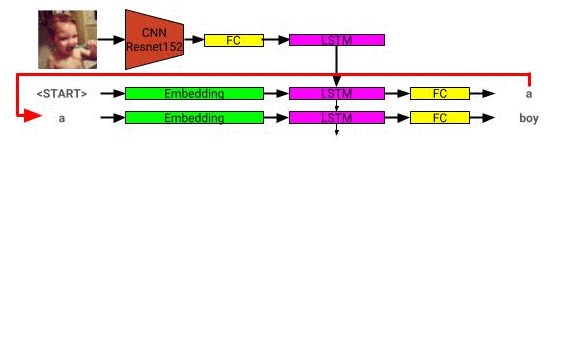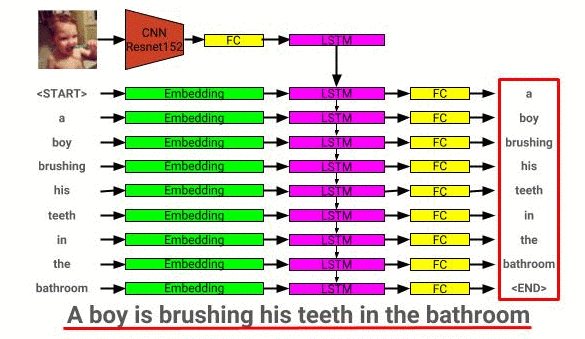
비디오 설명 모델 아키텍처는 여기에서 볼 수 있습니다. 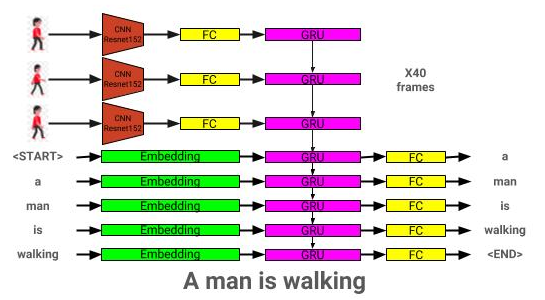
해설자는 현재 두 가지 방식으로 제공됩니다. 1) 현재 AWS에서 호스팅되고 웹 사이트를 통해 제공되는 플라스크 웹 앱과 2) 독립형 API : Narrator.py. 웹 사이트 사용의 예는 웹 사이트에서 볼 수 있으며 API 사용의 예는 노트북/내레이터 사용 예제.ipynb에서 볼 수 있습니다.
해설자 API는 Amazon Polly를 사용하여 텍스트에서 오디오 설명을 생성하고 비디오 내에서 장면 변경을 감지하기 위해 PyScenedEtect를 생성합니다.
이미지 설명 네트워크는 Coco 2014 데이터 세트를 사용하여 교육을받습니다.
비디오 설명 네트워크는 MSR-VTT 데이터 세트를 사용하여 교육을받습니다.
현재 가장 미리 훈련 된 이미지 설명 모델은 여기에서 다운로드 할 수 있습니다.
현재 가장 미리 훈련 된 비디오 설명 모델은 여기에서 다운로드 할 수 있습니다.
이 모델을 모델 디렉토리에 배치하십시오.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
종속성은 다음을 사용하여 다운로드 할 수 있습니다.
pip install -r requirements.txt
| 건축학 | CNN | 초기화 | 탐욕스러운 | 빔 = 3 |
|---|---|---|---|---|
| LSTM (Embed : 256) | RESNET152 | 무작위의 | 0.123 | 0.132 |
| Gru (Embed : 256) | RESNET152 | 무작위의 | 0.122 | 0.131 |
| LSTM (Embed : 256) | vgg16 | 무작위의 | 0.108 | 0.117 |
| 건축학 | CNN | 초기화 | 탐욕스러운 | 빔 = 3 |
|---|---|---|---|---|
| Gru (Embed : 256) | RESNET152 | 무작위의 | 0.317 | 0.351 |
| LSTM (Embed : 256) | RESNET152 | 무작위의 | 0.305 | 0.320 |
| LSTM (Embed : 256) | vgg16 | 무작위의 | 0.283 | 0.318 |
| LSTM (Embed : 512) | RESNET152 | 무작위의 | 0.270 | 0.317 |
| LSTM (Embed : 256) | RESNET152 | 미리 훈련 된 코코 | 0.278 | 0.310 |
이 섹션에서는 자신의 이미지 설명 모델을 어떻게 훈련시키는지를 보여줍니다.
먼저, Coco 데이터 세트 이미지 및 캡션은 훈련을 위해 전처리되어야합니다.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
---coco_path : Cocoapi 경로로가는 경로 (여기서 다운로드 할 수 있음)
-interm_results_path : 중간 결과를 저장하는 경로 (기본값 : 데이터/임시/)
---- results_path : 최종 결과를 저장하는 경로 (기본값 : data/processed/)
이것은 결합 된 캡션 데이터 세트를 <coco_path>/annotations/coco_captions.csv에 저장합니다.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
---coco_path : Cocoapi 경로로가는 경로 (여기서 다운로드 할 수 있음)
--vocab_path : 코코 어휘 저장 경로 (데이터 기본값/처리/Coco_vocab.pkl)
-threshold : 어휘에 추가 될 최소 단어 발생 (기본값 : 5)
-세트 : 어휘 구성에 포함 할 코코 세트 (기본값 : 'Train2014', 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-모델 : 전처리에 사용할 기본 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
-dir : 선택한 모델을 사용하여 인코딩하기 위해 코코 이미지로가는 경로
--continue_processing : 디렉토리에서 나머지 이미지를 인코딩합니다
인코딩 된 파일은 DIR에 배치됩니다.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Models_Path : 최종 모델을 저장하는 경로 (기본값 : Models/)
---eam_size : 유효성 검사를위한 빔 크기 (기본값 : 3)
--vocab_path : Coco Vocab의 경로 (기본값 : 데이터/처리/Coco_vocab.pkl)
--captions_path : 코코 캡션으로가는 경로 (기본값 : os.environ [ 'home'] + '/programs/cocoapi/annotations/coco_captions.csv'))
-Images_Path : Coco iamges로가는 경로 (기본값 : OS.Environ [ 'home'] + '/Database/Coco/Images/')
---LR : 사용하는 학습 속도 (기본값 : 0.001)
--val_interval : 유효성 검사 에포 주파수 (기본값 : 10)
-SAVE_INterVAL : SAVE SAVE POINTE EPOCH 주파수 (기본값 : 10)
-num_epochs : 훈련 할 에포크 수 (기본값 : 1000)
-initial_checkpoint_file : 훈련을 시작하기위한 체크 포인트 (기본값 : 없음)
-Version : 모델 버전 번호 (기본값 : 11)
---batch_size : 배치 크기 (기본값 : 64)
---coco_set : Coco Dataset to with (default : 2014)
---load_features : 이미지 임베딩을로드 또는 구성하는 옵션 (기본값 : true)
---load_captions : 캡션 임베드를로드 또는 구성하는 옵션 (기본값 : true)
-preload : 교육 전에 시스템 메모리에 데이터를 예압하는 옵션 (기본값 : true)
-BASE_MODEL : 전처리에 사용할베이스 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19_bn', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
--embedding_size : 이미지 임베딩의 크기 (기본값 : 2048)
-embed_size : RNN 입력의 크기 (기본값 : 256)
-Hidden_Size : RNN 숨겨진 레이어의 크기 (기본값 : 512)
---rnn_type : rnn 유형 (기본값 : 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Model_Path : 훈련 된 IC 모델로가는 경로
---eam_size : 유효성 검사를위한 빔 크기
--vocab_path : Coco Vocab의 경로 (기본값 : 데이터/처리/Coco_vocab.pkl)
--captions_path : 코코 캡션으로가는 경로 (기본값 : os.environ [ 'home'] + '/programs/cocoapi/annotations/coco_captions.csv'))
-Images_Path : Coco 이미지로가는 경로 (기본값 : OS.Environ [ 'home'] + '/Database/Coco/Images/')
---batch_size : 배치 크기 (기본값 : 64)
---coco_set : Coco Dataset to with (default : 2014)
---load_features : 이미지 임베딩을로드 또는 구성하는 옵션 (기본값 : true)
---load_captions : 캡션 임베드를로드 또는 구성하는 옵션 (기본값 : true)
-preload : 교육 전에 시스템 메모리에 데이터를 예압하는 옵션 (기본값 : true)
-BASE_MODEL : 전처리에 사용할베이스 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19_bn', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
--embedding_size : 이미지 임베딩의 크기 (기본값 : 2048)
-embed_size : RNN 입력의 크기 (기본값 : 256)
-Hidden_Size : RNN 숨겨진 레이어의 크기 (기본값 : 512)
---rnn_type : rnn 유형 (기본값 : 'lstm')
이 섹션에서는 자신의 비디오 설명 모델을 어떻게 훈련시킬 수 있는지 보여줍니다.
먼저, MSR-VTT 데이터 세트 비디오 및 캡션은 교육을 위해 전처리되어야합니다.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
-raw_data_path : 원시 MSRVTT 데이터 파일로가는 경로 (기본값 : 'data/raw/videodatainfo_2017_ustc.json')
-interim_data_path : 중간 결과를 저장하는 경로 (기본값 : 'data/interim/')
-Final_Data_Path : 최종 결과를 저장하는 경로 (기본값 : 'data/processed/')
-Continue_Converting : MSR-VTT 데이터 세트를 계속 변환하는 경로 (기본값 : true)
--train_pct : 교육에 사용할 데이터 세트의 백분율 (기본값 : 0.8)
-dev_pct : 개발에 사용할 데이터 세트의 백분율 (기본값 : 0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
---coco_path : make_msrvtt_dataset.py 에 의해 생성 된 msr-vtt 캡션 경로 (기본값 : 'data/processed/msrvtt_captions.csv')
--vocab_path : msr-vtt 어휘를 저장하는 경로 (data/msrvtt_vocab.pkl에 대한 기본값)
-threshold : 어휘에 추가 될 최소 단어 발생 (기본값 : 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-모델 : 전처리에 사용할 기본 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
-dir : 선택한 모델을 사용하여 인코딩 할 MSR-VTT 비디오로가는 경로 (기본값 : os.environ [ 'home'] + '/database/msr-vtt/train-video/')
--continue_processing : 디렉토리에서 나머지 비디오를 인코딩 (기본값 : true)
-재생산 : CNN 입력 해상도 (기본값 : 224)
-num_frames : 인코딩 할 프레임 수 (기본값 : 40)
---frames_interval : 프레임 간격 (기본값 : 1)
--embedding_size : CNN OUPUT 해상도 (기본값 : 2048)
인코딩 된 파일은 DIR에 배치됩니다.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Models_Path : 최종 모델을 저장하는 경로 (기본값 : Models/)
---eam_size : 유효성 검사를위한 빔 크기 (기본값 : 3)
--vocab_path : msr-vtt로가는 경로 (기본값 : data/processed/msrvtt_vocab.pkl)
--captions_path : MSR-VTT 캡션으로가는 경로 (기본값 : 데이터/처리/MSRVTT_CAPTIONS.CSV)
--videos_path : msr-vtt 비디오로가는 경로 (기본값 : os.environ [ 'home'] + '/database/msr-vtt/train-video/')
---LR : 사용하는 학습 속도 (기본값 : 0.001)
--val_interval : 유효성 검사 에포 주파수 (기본값 : 10)
-SAVE_INterVAL : SAVE SAVE POINTE EPOCH 주파수 (기본값 : 10)
-num_epochs : 훈련 할 에포크 수 (기본값 : 1000)
-initial_checkpoint_file : 훈련을 시작하기위한 체크 포인트 (기본값 : 없음)
-Version : 모델 버전 번호 (기본값 : 11)
---batch_size : 배치 크기 (기본값 : 64)
---load_features : 비디오 임베딩을로드 또는 구성하는 옵션 (기본값 : true)
---load_captions : 캡션 임베드를로드 또는 구성하는 옵션 (기본값 : true)
-preload : 교육 전에 시스템 메모리에 데이터를 예압하는 옵션 (기본값 : true)
-BASE_MODEL : 전처리에 사용할베이스 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19_bn', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
--embedding_size : 프레임 임베딩의 크기 (기본값 : 2048)
-embed_size : RNN 입력의 크기 (기본값 : 256)
-Hidden_Size : RNN 숨겨진 레이어의 크기 (기본값 : 512)
---rnn_type : rnn 유형 (기본값 : 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-Model_Path : 훈련 된 비디오 설명 모델로가는 경로
---eam_size : 유효성 검사를위한 빔 크기
--vocab_path : msr-vtt로가는 경로 (기본값 : data/processed/msrvtt_vocab.pkl)
--captions_path : MSR-VTT 캡션으로가는 경로 (기본값 : 데이터/처리/MSRVTT_CAPTIONS.CSV)
--videos_path : msr-vtt 비디오로가는 경로 (기본값 : os.environ [ 'home'] + '/database/msr-vtt/train-video/')
---batch_size : 배치 크기 (기본값 : 64)
---load_features : 비디오 임베딩을로드 또는 구성하는 옵션 (기본값 : true)
---load_captions : 캡션 임베드를로드 또는 구성하는 옵션 (기본값 : true)
-preload : 교육 전에 시스템 메모리에 데이터를 예압하는 옵션 (기본값 : true)
-BASE_MODEL : 전처리에 사용할베이스 CNN 모델 (옵션 : [ 'resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet0', 'vgg19_bn', 'vgg16_bn' 'densenet121', 'densenet201', 'Inception'])))))
--embedding_size : 프레임 임베딩의 크기 (기본값 : 2048)
-embed_size : RNN 입력의 크기 (기본값 : 256)
-Hidden_Size : RNN 숨겨진 레이어의 크기 (기본값 : 512)
---rnn_type : rnn 유형 (기본값 : 'lstm')


