Narrator
1.0.0
=====================================================
Essa API e serviço foram criados com a intenção de ajudar os criadores de conteúdo a obter descrições auditivas geradas por IA de cenas e imagens que eles podem usar para tornar seu conteúdo mais acessível para pessoas com deficiência de visão.
A API do narrador gera descrições de áudio para imagens e vídeos fornecidos usando duas redes neurais CNN-RNN desenvolvidas em Pytorch: 1) Uma imagem para o texto Descrição Rede com base na rede Show-and-roul e 2) uma extensão dessa rede para a descrição do vídeo para o texto. A rede de descrição do vídeo pode ser usada adicionalmente para gerar descrições por cena em um vídeo.
A arctitecture geral para o narrador pode ser vista aqui: 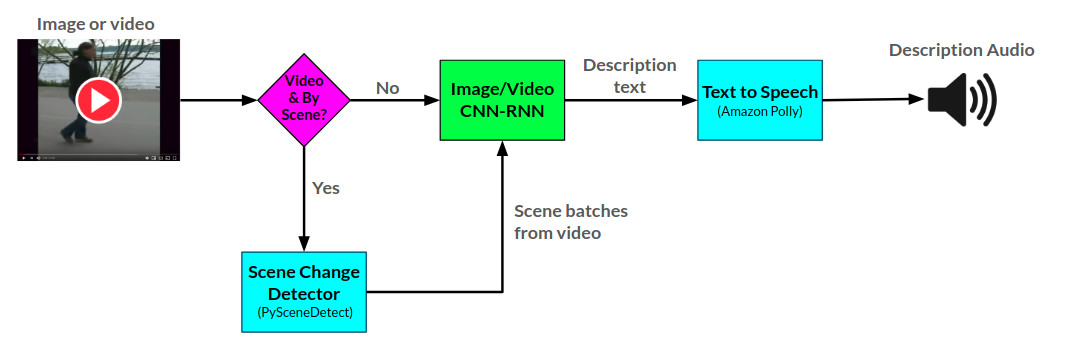
A arquitetura do modelo de descrição da imagem pode ser vista aqui: 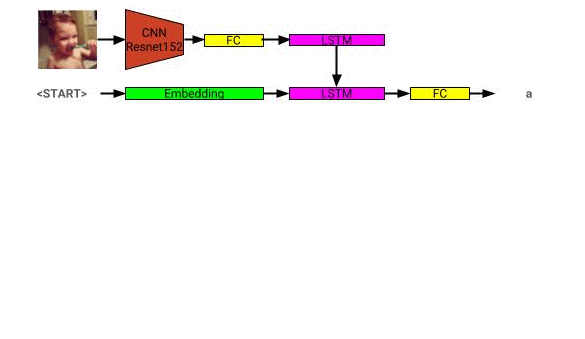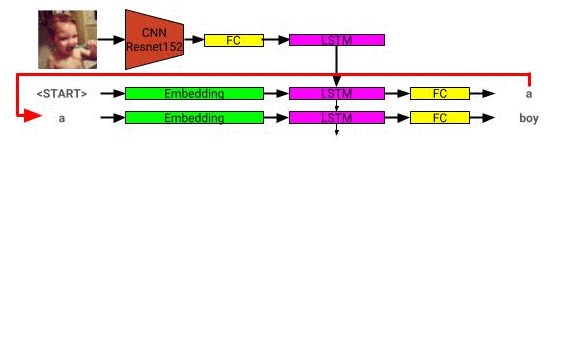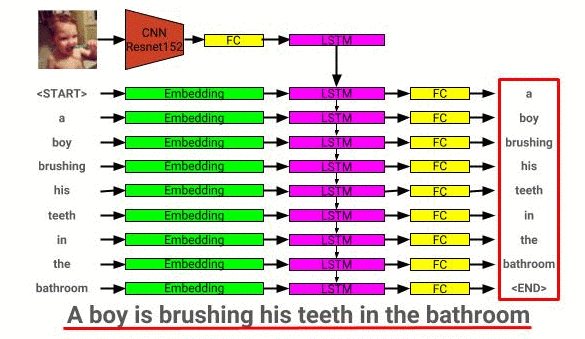
A arquitetura do modelo de descrição de vídeo pode ser vista aqui: 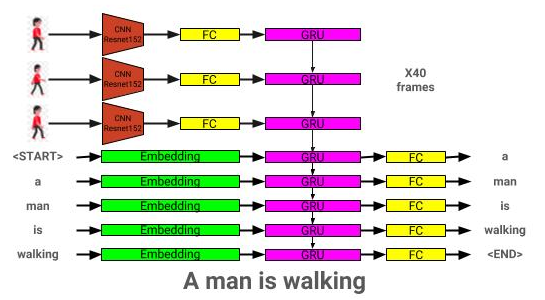
Atualmente, o narrador é servido de duas maneiras: 1) um aplicativo da Web de Flask atualmente hospedado na AWS e servido por um site e 2) uma API independente: narrador.py. Exemplos de uso do site podem ser vistos no site, e exemplos de uso da API podem ser vistos em notebooks/uso de uso do narrador.ipynb.
A API do narrador usa a Amazon Polly para gerar descrições de áudio a partir de texto e pysecnedetect para detectar mudanças de cena em um vídeo.
A rede de descrição da imagem é treinada usando o conjunto de dados Coco 2014.
A rede de descrição do vídeo é treinada usando o conjunto de dados MSR-VTT.
O melhor modelo de descrição de imagem pré-treinado atual pode ser baixado aqui.
O melhor modelo de descrição de vídeo pré-treinado atual pode ser baixado aqui.
Coloque esses modelos no diretório de modelos.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
As dependências podem ser baixadas usando:
pip install -r requirements.txt
| Arquitetura | CNN | Inicialização | Ambicioso | Feixe = 3 |
|---|---|---|---|---|
| LSTM (incorporado: 256) | Resnet152 | Aleatório | 0,123 | 0,132 |
| Gru (incorporado: 256) | Resnet152 | Aleatório | 0,122 | 0,131 |
| LSTM (incorporado: 256) | VGG16 | Aleatório | 0,108 | 0,117 |
| Arquitetura | CNN | Inicialização | Ambicioso | Feixe = 3 |
|---|---|---|---|---|
| Gru (incorporado: 256) | Resnet152 | Aleatório | 0,317 | 0,351 |
| LSTM (incorporado: 256) | Resnet152 | Aleatório | 0,305 | 0,320 |
| LSTM (incorporado: 256) | VGG16 | Aleatório | 0,283 | 0,318 |
| LSTM (incorporado: 512) | Resnet152 | Aleatório | 0,270 | 0,317 |
| LSTM (incorporado: 256) | Resnet152 | Coco pré-treinado | 0,278 | 0,310 |
Esta seção mostrará como alguém pode treinar seu próprio modelo de descrição da imagem.
Primeiro, as imagens e legendas do conjunto de dados Coco precisam ser pré -processadas para treinamento.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
--coco_path: caminho para o caminho Cocoapi (pode baixar aqui)
--inDert_results_path: caminho para armazenar resultados intermediários (padrão: dados/interim/)
-Results_path: caminho para armazenar resultados finais (padrão: dados/processado/)
Além disso, armazena o conjunto de dados de legendas combinadas em <coco_path> /annotações/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: caminho para o caminho Cocoapi (pode baixar aqui)
--vocab_path: caminho para armazenar vocabulário Coco (padrão para dados/processado/coco_vocab.pkl)
--threshold: minig word ocro a ser adicionado ao vocabulário (padrão: 5)
-Sets: Coco Conjuntos a serem incluídos na Construção de Vocabulário (Padrão: 'Train2014', 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--DIR: caminho para imagens de coco para codificar usando o modelo escolhido
--continue_processing: codifique imagens restantes no diretório
Os arquivos codificados serão colocados no dir.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--Models_path: caminho para armazenar o modelo final (padrão: modelos/)
-Beam_size: Tamanho do feixe para validação (Padrão: 3)
--vocab_path: Path to Coco Vocab (Padrão: Dados/Processado/Coco_vocab.pkl)
--Captions_path: caminho para as legendas Coco (padrão: os.environ ['home'] + '/programs/cocoapi/annotações/coco_captions.csv')
--images_path: caminho para coco iamges (padrão: os.environ ['home'] + '/banco de dados/coco/imagens/')
-LR: Taxa de aprendizado a ser usada (Padrão: 0,001)
--Val_Interval: Frequência de época da validação (Padrão: 10)
--save_interval: salve a frequência da época do ponto de verificação (padrão: 10)
--num_epochs: número de épocas para treinar (padrão: 1000)
-Initial_CheckPoint_file: Ponto de verificação para começar o treinamento de (Padrão: Nenhum)
--Version: Modelo Número da versão (Padrão: 11)
--Batch_size: Tamanho do lote (Padrão: 64)
--coco_set: conjunto de dados Coco para treinar (Padrão: 2014)
--load_features: opção para carregar ou construir incorpitings de imagem (padrão: true)
--load_captions: Opção para carregar ou construir legendas incorporadas (padrão: true)
--Preload: opção para pré-carregar dados para a memória do sistema antes do treinamento (padrão: true)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: tamanho da incorporação de imagem (padrão: 2048)
--embed_size: tamanho da entrada RNN (padrão: 256)
-Hidden_size: Tamanho da camada oculta RNN (Padrão: 512)
--rnn_type: rnn tipo (padrão: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--Model_path: caminho para o modelo de IC treinado
-Beam_size: Tamanho do feixe para validação
--vocab_path: Path to Coco Vocab (Padrão: Dados/Processado/Coco_vocab.pkl)
--Captions_path: caminho para as legendas Coco (padrão: os.environ ['home'] + '/programs/cocoapi/annotações/coco_captions.csv')
--images_path: caminho para imagens coco (padrão: os.environ ['home'] + '/banco de dados/coco/imagens/')
--Batch_size: Tamanho do lote (Padrão: 64)
--coco_set: conjunto de dados Coco para treinar (Padrão: 2014)
--load_features: opção para carregar ou construir incorpitings de imagem (padrão: true)
--load_captions: Opção para carregar ou construir legendas incorporadas (padrão: true)
--Preload: opção para pré-carregar dados para a memória do sistema antes do treinamento (padrão: true)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: tamanho da incorporação de imagem (padrão: 2048)
--embed_size: tamanho da entrada RNN (padrão: 256)
-Hidden_size: Tamanho da camada oculta RNN (Padrão: 512)
--rnn_type: rnn tipo (padrão: 'lstm')
Esta seção mostrará como alguém pode treinar seu próprio modelo de descrição de vídeo.
Primeiro, os vídeos e legendas do conjunto de dados MSR-VTT precisam ser pré-processados para treinamento.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
--raw_data_path: caminho para arquivos de dados RAW MSRVTT (padrão: 'Data/Raw/Videodatainfo_2017_USTC.json')
-Interim_data_path: caminho para armazenar resultados intermediários (padrão: 'dados/interim/')
--Final_Data_Path: caminho para armazenar resultados finais (padrão: 'dados/processado/')
--continue_converting: caminho para continuar convertendo o conjunto de dados MSR-VTT (padrão: true)
--train_pct: porcentagem do conjunto de dados a ser usado para treinamento (padrão: 0,8)
--dev_pct: porcentagem do conjunto de dados a ser usado para desenvolvimento (padrão: 0,15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: caminho para as legendas msr-vtt geradas por make_msrvtt_dataset.py (padrão: 'data/processou/msrvtt_captions.csv')
--vocab_path: caminho para armazenar vocabulário msr-vtt (padrão para dados/processado/msrvtt_vocab.pkl)
--threshold: minig word ocro a ser adicionado ao vocabulário (padrão: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
--model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--DIR: caminho para vídeos msr-vtt a codificar usando o modelo escolhido (padrão: os.environ ['home'] + '/banco de dados/msr-vtt/tren-video/')
--continue_processing: codifica vídeos restantes no diretório (padrão: true)
-Resolução: Resolução de entrada da CNN (Padrão: 224)
--num_frames: Número de quadros a serem codificados (padrão: 40)
--FRAMES_INTERVAL: intervalo entre os quadros (padrão: 1)
--embedding_size: CNN OUPUT Resolução (Padrão: 2048)
Os arquivos codificados serão colocados no dir.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--Models_path: caminho para armazenar o modelo final (padrão: modelos/)
-Beam_size: Tamanho do feixe para validação (Padrão: 3)
--vocab_path: caminho para msr-vtt vocab (padrão: dados/processado/msrvtt_vocab.pkl)
--Captions_path: caminho para as legendas MSR-VTT (Padrão: Data/Processado/msrvtt_captions.csv)
--videos_path: caminho para vídeos msr-vtt (padrão: os.environ ['home'] + '/database/msr-vtt/tren-video/')
-LR: Taxa de aprendizado a ser usada (Padrão: 0,001)
--Val_Interval: Frequência de época da validação (Padrão: 10)
--save_interval: salve a frequência da época do ponto de verificação (padrão: 10)
--num_epochs: número de épocas para treinar (padrão: 1000)
-Initial_CheckPoint_file: Ponto de verificação para começar o treinamento de (Padrão: Nenhum)
--Version: Modelo Número da versão (Padrão: 11)
--Batch_size: Tamanho do lote (Padrão: 64)
--load_features: opção para carregar ou construir incorpitings de vídeo (padrão: true)
--load_captions: Opção para carregar ou construir legendas incorporadas (padrão: true)
--Preload: opção para pré-carregar dados para a memória do sistema antes do treinamento (padrão: true)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: tamanho da incorporação do quadro (padrão: 2048)
--embed_size: tamanho da entrada RNN (padrão: 256)
-Hidden_size: Tamanho da camada oculta RNN (Padrão: 512)
--rnn_type: rnn tipo (padrão: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--Model_Path: Caminho para o modelo de descrição de vídeo treinado
-Beam_size: Tamanho do feixe para validação
--vocab_path: caminho para msr-vtt vocab (padrão: dados/processado/msrvtt_vocab.pkl)
--Captions_path: caminho para as legendas MSR-VTT (Padrão: Data/Processado/msrvtt_captions.csv)
--videos_path: caminho para vídeos msr-vtt (padrão: os.environ ['home'] + '/database/msr-vtt/tren-video/')
--Batch_size: Tamanho do lote (Padrão: 64)
--load_features: opção para carregar ou construir incorpitings de vídeo (padrão: true)
--load_captions: Opção para carregar ou construir legendas incorporadas (padrão: true)
--Preload: opção para pré-carregar dados para a memória do sistema antes do treinamento (padrão: true)
--base_model: Base CNN model to use for preprocessing (options: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeezenet1', 'Densenet121', 'Densenet201', 'Inception'])
--embedding_size: tamanho da incorporação do quadro (padrão: 2048)
--embed_size: tamanho da entrada RNN (padrão: 256)
-Hidden_size: Tamanho da camada oculta RNN (Padrão: 512)
--rnn_type: rnn tipo (padrão: 'lstm')


