Narrator
1.0.0
======================================================
Esta API y el servicio se crearon con la intención de ayudar a los creadores de contenido a obtener descripciones auditivas generadas de AI de escenas e imágenes que pueden usar para que su contenido sea más accesible para las personas con discapacidad visual.
La API del narrador genera descripciones de audio para imágenes y videos proporcionados utilizando dos redes neuronales CNN-RNN desarrolladas en Pytorch: 1) Una red de descripción de imagen para texto basada en la red de espectáculos y telarañas, y 2) una extensión de esta red en la descripción de videos a texto. La red de descripción de video también se puede utilizar para generar descripciones por escena en un video.
La arctitectura general para el narrador se puede ver aquí: 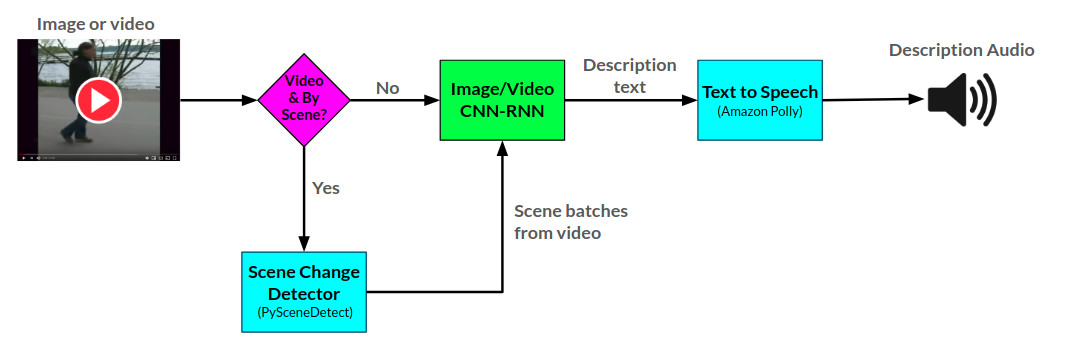
La arquitectura del modelo de descripción de la imagen se puede ver aquí: 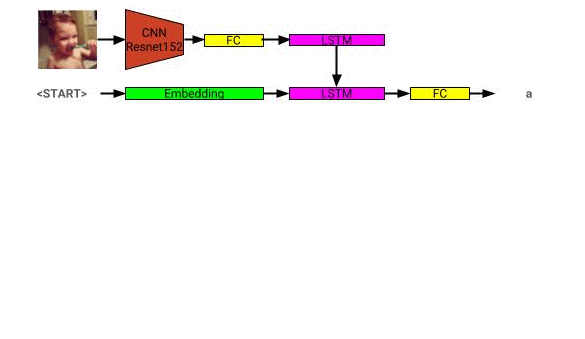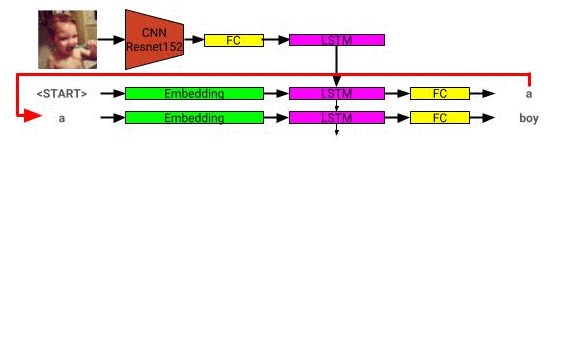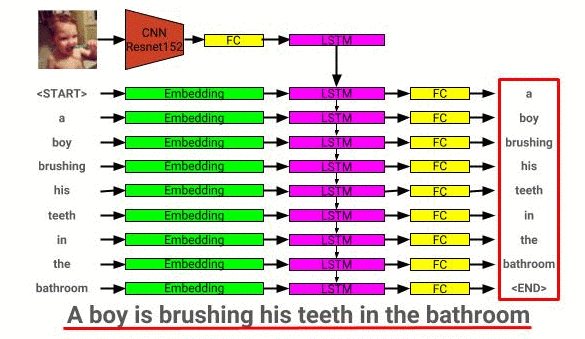
La arquitectura del modelo de descripción de video se puede ver aquí: 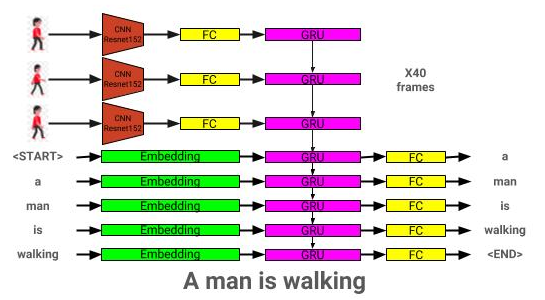
Actualmente, el narrador se sirve de dos maneras: 1) una aplicación web de frascos que actualmente se aloja en AWS y se sirve a través de un sitio web, y 2) una API independiente: Narrator.py. Se pueden ver ejemplos de uso del sitio web en el sitio web, y se pueden ver ejemplos de la API en cuadernos/ejemplos de uso del narrador.ipynb.
La API narradora utiliza Amazon Polly para generar descripciones de audio del texto, y PysCenedetect para detectar los cambios de escena dentro de un video.
La red Descripción de la imagen está capacitada utilizando el conjunto de datos Coco 2014.
La red de descripción de video está capacitada utilizando el conjunto de datos MSR-VTT.
El mejor modelo actual de descripción de imagen previamente capacitada se puede descargar desde aquí.
El mejor modelo de descripción de video previamente capacitado actual se puede descargar desde aquí.
Coloque estos modelos en el directorio de modelos.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
Las dependencias se pueden descargar usando:
pip install -r requirements.txt
| Arquitectura | CNN | Inicialización | Avaro | Beam = 3 |
|---|---|---|---|---|
| LSTM (incrustación: 256) | Resnet152 | Aleatorio | 0.123 | 0.132 |
| Gru (Incorporación: 256) | Resnet152 | Aleatorio | 0.122 | 0.131 |
| LSTM (incrustación: 256) | VGG16 | Aleatorio | 0.108 | 0.117 |
| Arquitectura | CNN | Inicialización | Avaro | Beam = 3 |
|---|---|---|---|---|
| Gru (Incorporación: 256) | Resnet152 | Aleatorio | 0.317 | 0.351 |
| LSTM (incrustación: 256) | Resnet152 | Aleatorio | 0.305 | 0.320 |
| LSTM (incrustación: 256) | VGG16 | Aleatorio | 0.283 | 0.318 |
| LSTM (incrustación: 512) | Resnet152 | Aleatorio | 0.270 | 0.317 |
| LSTM (incrustación: 256) | Resnet152 | Coco pre-entrenado | 0.278 | 0.310 |
Esta sección mostrará cómo se puede entrenar su propio modelo de descripción de imagen.
Primero, las imágenes y subtítulos del conjunto de datos de Coco deben preprocesarse para el entrenamiento.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
--coco_path: ruta a la ruta de Cocoapi (puede descargar desde aquí)
--inter_results_path: ruta para almacenar resultados provisionales (predeterminado: data/interim/)
--Results_path: ruta para almacenar resultados finales (predeterminado: datos/procesado/)
Esto también almacena el conjunto de datos de subtítulos combinados en <coco_path> /annotations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: ruta a la ruta de Cocoapi (puede descargar desde aquí)
--vocab_path: ruta para almacenar vocabulario de coco (predeterminado a datos/procesado/coco_vocab.pkl)
-umbral: mínima palabra ocurrente que se agregará al vocabulario (predeterminado: 5)
--sets: Coco Conjuntos para incluir en la construcción del vocabulario (predeterminado: 'Train2014', 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-Modelo: modelo Base CNN para usar para preprocesamiento (opciones: ['ResNet18', 'ResNet50', 'ResNet152', 'VGG11', 'VGG11_BN', 'VGG16', 'VGG16_BN', 'VGG19', 'VGG19_BN', 'Squeezenet0', 'Squeezenet1', 'densenet121', 'densenet201', 'inception'])
--dir: ruta a las imágenes de coco para codificar con el modelo elegido
--continue_processing: codifica las imágenes restantes en el directorio
Los archivos codificados se colocarán en Dir.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--models_path: ruta para almacenar el modelo final (predeterminado: modelos/)
--beam_size: tamaño del haz para la validación (predeterminado: 3)
--vocab_path: ruta a la vocabulidad de la coco (predeterminada: datos/procesado/coco_vocab.pkl)
--captions_path: ruta a los subtítulos (predeterminado: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: ruta a Coco iamges (predeterminado: OS.environ ['home'] + '/database/coco/images/')
--lr: tasa de aprendizaje para usar (predeterminado: 0.001)
--val_interval: frecuencia de época de validación (predeterminado: 10)
--save_interval: Guardar frecuencia de la época del punto de control (predeterminado: 10)
--num_epochs: número de épocas para entrenar para (predeterminado: 1000)
--inicial_checkpoint_file: punto de control para comenzar la capacitación desde (predeterminado: ninguno)
--versión: número de versión del modelo (predeterminado: 11)
-Batch_size: tamaño por lotes (predeterminado: 64)
--coco_set: conjunto de datos de Coco para entrenar con (predeterminado: 2014)
--Load_Feature: Opción para cargar o construir incrustaciones de imagen (predeterminada: Verdadero)
--Load_captions: opción para cargar o construir integrantes de subtítulos (predeterminado: verdadero)
--Preload: opción para precargar los datos a la memoria del sistema antes de la capacitación (predeterminado: verdadero)
--Base_Model: modelo base CNN para usar para preprocesamiento (opciones: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeeezeet1', 'densenet121', 'densenet201', 'inception'])
--Embedding_Size: Tamaño de la incrustación de imagen (predeterminado: 2048)
--Embed_Size: tamaño de la entrada RNN (predeterminado: 256)
--hidden_size: tamaño de la capa oculta RNN (predeterminada: 512)
--rnn_type: rnn type (predeterminado: 'LSTM')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--model_path: ruta al modelo IC entrenado
--beam_size: tamaño del haz para la validación
--vocab_path: ruta a la vocabulidad de la coco (predeterminada: datos/procesado/coco_vocab.pkl)
--captions_path: ruta a los subtítulos (predeterminado: os.environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
--images_path: ruta a coco imágenes (predeterminada: os.environ ['home'] + '/database/coco/images/')
-Batch_size: tamaño por lotes (predeterminado: 64)
--coco_set: conjunto de datos de Coco para entrenar con (predeterminado: 2014)
--Load_Feature: Opción para cargar o construir incrustaciones de imagen (predeterminada: Verdadero)
--Load_captions: opción para cargar o construir integrantes de subtítulos (predeterminado: verdadero)
--Preload: opción para precargar los datos a la memoria del sistema antes de la capacitación (predeterminado: verdadero)
--Base_Model: modelo base CNN para usar para preprocesamiento (opciones: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeeezeet1', 'densenet121', 'densenet201', 'inception'])
--Embedding_Size: Tamaño de la incrustación de imagen (predeterminado: 2048)
--Embed_Size: tamaño de la entrada RNN (predeterminado: 256)
--hidden_size: tamaño de la capa oculta RNN (predeterminada: 512)
--rnn_type: rnn type (predeterminado: 'LSTM')
Esta sección mostrará cómo se puede entrenar su propio modelo de descripción de video.
Primero, los videos y subtítulos de conjunto de datos MSR-VTT deben preprocesarse para la capacitación.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
--raw_data_path: ruta a archivos de datos de msrvtt sin procesar (predeterminado: 'data/raw/videodatainfo_2017_ustc.json')
--interim_data_path: ruta para almacenar resultados provisionales (predeterminado: 'data/interim/')
--final_data_path: ruta para almacenar resultados finales (predeterminado: 'data/procesado/')
--Continue_Converting: ruta para continuar convirtiendo el conjunto de datos MSR-VTT (predeterminado: verdadero)
--train_pct: porcentaje del conjunto de datos para usar para la capacitación (predeterminado: 0.8)
--DEV_PCT: porcentaje del conjunto de datos para usar para el desarrollo (predeterminado: 0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
--coco_path: ruta a las subtítulos de MSR-VTT generadas por make_msrvtt_dataset.py (predeterminado: 'data/procesado/msrvtt_captions.csv')
--vocab_path: ruta para almacenar el vocabulario MSR-VTT (predeterminado a datos/procesado/msrvtt_vocab.pkl)
-umbral: mínima palabra ocurrente que se agregará al vocabulario (predeterminado: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-Modelo: modelo Base CNN para usar para preprocesamiento (opciones: ['ResNet18', 'ResNet50', 'ResNet152', 'VGG11', 'VGG11_BN', 'VGG16', 'VGG16_BN', 'VGG19', 'VGG19_BN', 'Squeezenet0', 'Squeezenet1', 'densenet121', 'densenet201', 'inception'])
--dir: ruta a los videos MSR-VTT para codificar con el modelo elegido (predeterminado: OS.environ ['Home'] + '/Database/MSR-VTT/Train-Video/')
--continue_processing: codifica videos restantes en el directorio (predeterminado: verdadero)
-resolución: resolución de entrada CNN (predeterminada: 224)
--num_frames: número de cuadros para codificar (predeterminado: 40)
--frames_interval: intervalo entre cuadros (predeterminado: 1)
--Embedding_Size: resolución CNN OutuPut (predeterminada: 2048)
Los archivos codificados se colocarán en Dir.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--models_path: ruta para almacenar el modelo final (predeterminado: modelos/)
--beam_size: tamaño del haz para la validación (predeterminado: 3)
--vocab_path: ruta a msr-vtt vocab (predeterminado: data/procesado/msrvtt_vocab.pkl)
--captions_path: ruta a las subtítulos de MSR-VTT (predeterminado: Data/Processed/MSRVTT_Captions.csv)
--videos_path: ruta a videos MSR-VTT (predeterminado: OS.environ ['Home'] + '/Database/MSR-VTT/Train-Video/'))
--lr: tasa de aprendizaje para usar (predeterminado: 0.001)
--val_interval: frecuencia de época de validación (predeterminado: 10)
--save_interval: Guardar frecuencia de la época del punto de control (predeterminado: 10)
--num_epochs: número de épocas para entrenar para (predeterminado: 1000)
--inicial_checkpoint_file: punto de control para comenzar la capacitación desde (predeterminado: ninguno)
--versión: número de versión del modelo (predeterminado: 11)
-Batch_size: tamaño por lotes (predeterminado: 64)
--Load_Feature: Opción para cargar o construir incrustaciones de video (predeterminado: verdadero)
--Load_captions: opción para cargar o construir integrantes de subtítulos (predeterminado: verdadero)
--Preload: opción para precargar los datos a la memoria del sistema antes de la capacitación (predeterminado: verdadero)
--Base_Model: modelo base CNN para usar para preprocesamiento (opciones: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeeezeet1', 'densenet121', 'densenet201', 'inception'])
--Embedding_Size: Tamaño de la incrustación de cuadro (predeterminado: 2048)
--Embed_Size: tamaño de la entrada RNN (predeterminado: 256)
--hidden_size: tamaño de la capa oculta RNN (predeterminada: 512)
--rnn_type: rnn type (predeterminado: 'LSTM')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
--model_path: ruta al modelo de descripción de video entrenado
--beam_size: tamaño del haz para la validación
--vocab_path: ruta a msr-vtt vocab (predeterminado: data/procesado/msrvtt_vocab.pkl)
--captions_path: ruta a las subtítulos de MSR-VTT (predeterminado: Data/Processed/MSRVTT_Captions.csv)
--videos_path: ruta a videos MSR-VTT (predeterminado: OS.environ ['Home'] + '/Database/MSR-VTT/Train-Video/'))
-Batch_size: tamaño por lotes (predeterminado: 64)
--Load_Feature: Opción para cargar o construir incrustaciones de video (predeterminado: verdadero)
--Load_captions: opción para cargar o construir integrantes de subtítulos (predeterminado: verdadero)
--Preload: opción para precargar los datos a la memoria del sistema antes de la capacitación (predeterminado: verdadero)
--Base_Model: modelo base CNN para usar para preprocesamiento (opciones: ['resnet18', 'resnet50', 'resnet152', 'vgg11', 'vgg11_bn', 'vgg16', 'vgg16_bn', 'vgg19', 'vgg19_bn', 'squeezenet0', 'squeeezeet1', 'densenet121', 'densenet201', 'inception'])
--Embedding_Size: Tamaño de la incrustación de cuadro (predeterminado: 2048)
--Embed_Size: tamaño de la entrada RNN (predeterminado: 256)
--hidden_size: tamaño de la capa oculta RNN (predeterminada: 512)
--rnn_type: rnn type (predeterminado: 'LSTM')


