Narrator
1.0.0
====================================================
تم إنشاء واجهة برمجة التطبيقات والخدمة هذه بقصد مساعدة منشئي المحتوى على الحصول على أوصاف سمعية من الذكاء الاصطناعي للمشاهد والصور التي يمكنهم استخدامها لجعل محتواهم أكثر سهولة للأشخاص الذين يعانون من ضعف الرؤية.
تقوم API للراوي بإنشاء أوصاف صوتية للصور ومقاطع الفيديو المقدمة باستخدام شبكتين عصبيتين من CNN-RNN تم تطويرهما في Pytorch: 1) شبكة وصفًا للوصف النص بناءً على شبكة العرض والتخلي ، و 2) امتداد لهذا الشبكة إلى فيديو إلى نص نص. بالإضافة إلى ذلك ، يمكن استخدام شبكة وصف الفيديو لإنشاء أوصاف لكل مشهد في مقطع فيديو.
يمكن رؤية البنية الإجمالية للراوي هنا: 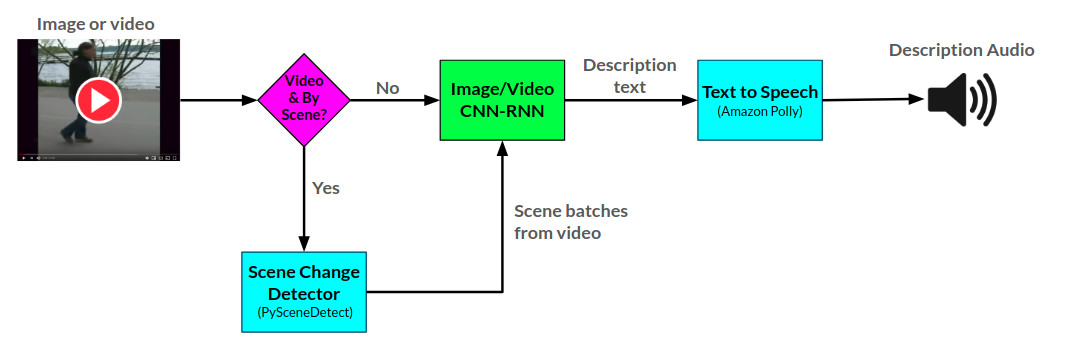
يمكن رؤية بنية نموذج وصف الصورة هنا: 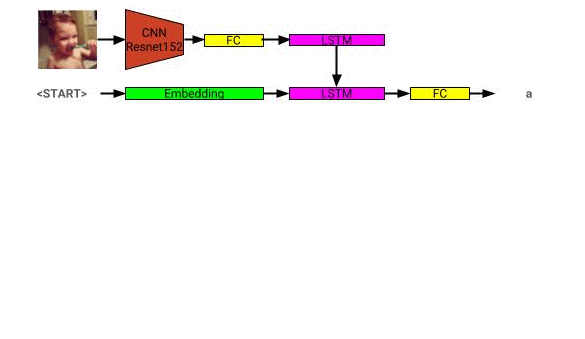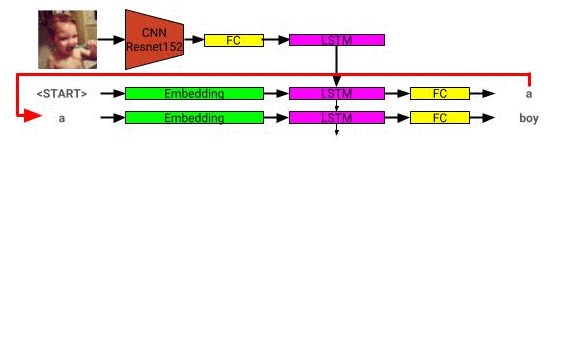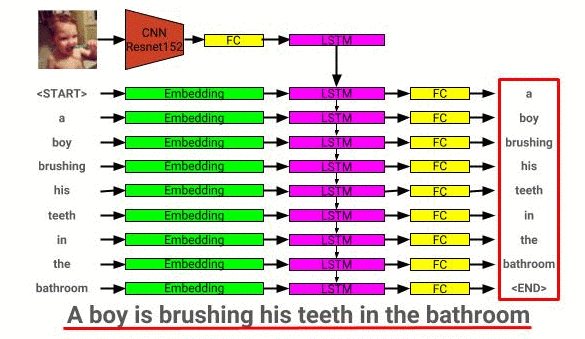
يمكن رؤية بنية نموذج وصف الفيديو هنا: 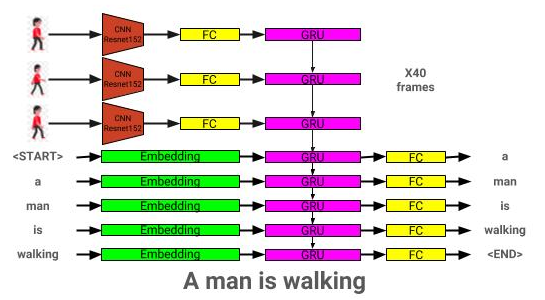
يتم تقديم الراوي حاليًا بطريقتين: 1) تطبيق ويب Flask يتم استضافته حاليًا على AWS ويتم تقديمه عبر موقع ويب ، و 2) واجهة برمجة تطبيقات مستقلة: الراوي. يمكن رؤية أمثلة على استخدام موقع الويب على موقع الويب ، ويمكن رؤية أمثلة استخدام API في أمثلة استخدام الدفاتر/الراوي.
يستخدم Api الراوي Amazon Polly إنشاء أوصاف صوتية من النص ، و pyscenedetect للكشف عن تغييرات المشهد داخل الفيديو.
يتم تدريب شبكة وصف الصورة باستخدام مجموعة بيانات Coco 2014.
يتم تدريب شبكة وصف الفيديو باستخدام مجموعة بيانات MSR-VTT.
يمكن تنزيل نموذج وصف الصورة الذي تم تدريبه مسبقًا من هنا.
يمكن تنزيل نموذج وصف الفيديو الذي تم تدريبه مسبقًا من هنا.
ضع هذه النماذج في دليل النماذج.
├── LICENSE
├── README.md <- The top-level README for developers using this project.
├── data
│ ├── interim <- Intermediate data that has been transformed.
│ ├── processed <- The final, canonical data sets for modeling.
│ └── raw <- The original, immutable data dump.
│
├── models <- Location to store trained models to be used by Narrator
│
├── notebooks <- Example Jupyter notebook + notebooks for validation
│ ├── Narrator-Usage-Examples.ipynb <- Examples of how to use Narrator independently of the web interface
│ ├── Image-Captioner-Validation.ipynb <- Notebook for validating image captioner model
│ ├── Video-Captioner-Validation.ipynb <- Notebook for validating video captioner model
│ └── Data-Analysis.ipynb <- Notebook for analyzing image/data analysis
│
├── results <- Directory to store results
│
├── samples <- Image and video samples to use with Narrator.
│
├── src <- Source code for use in this project.
│ ├── __init__.py <- Makes src a Python module
│ ├── ic_trainer.py <- Module for training image description model
│ ├── ic_validate.py <- Module for evaluating image description model
│ ├── Narrator.py <- Python class for deploying trained image/video description models
│ ├── vc_trainer.py <- Module for training video description model
│ ├── vc_validate.py <- Module for evaluating video description model
│ │
│ ├── models <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── EncoderCNN.py <-- Pre-trained CNN PyTorch model
│ │ ├── ImageCaptioner.py <- Image Captioner Show-and-tell PyTorch Model
│ │ ├── VideoCaptioner.py <- Video Captioner PyTorch Model
│ │ ├── S2VTCaptioner.py <- S2VT PyTorch PyTorch Model
│ │ ├── YoloObjectDetector.py <- Wrapper for yolo submodule
│ │ └── pytorch-yolo-v3 <- git submodule: https://github.com/ayooshkathuria/pytorch-yolo-v3
│ │
│ ├── prepare <- Scripts to prepare COCO/MSR-VTT datasets for training
│ │ ├── build_coco_vocabulary.py
│ │ ├── build_msrvtt_vocabulary.py
│ │ ├── make_coco_dataset.py
│ │ ├── make_msrvtt_dataset.py
│ │ ├── preprocess_coco_images.py
│ │ ├── preprocess_coco_objects.py
│ │ ├── preprocess_msrvtt_objects.py
│ │ └── preprocess_msrvtt_videos.py
│ │
│ └── utils <- Assistance classes and modules
│ ├── create_transformer.py <- Create image transformer with torchvision
│ ├── TTS.py <- Amazon Polly wrapper
│ ├── ImageDataloader.py <- Torch dataloader for the COCO dataset
│ ├── VideoDataloader.py <- Torch dataloader for the MSR-VTT dataset
│ └── Vocabulary.py <- Vocabulary class
│
│
└── web <- Scripts/templates related to deploying web app with Flask
يمكن تنزيل التبعيات باستخدام:
pip install -r requirements.txt
| بنيان | سي إن إن | التهيئة | طماع | شعاع = 3 |
|---|---|---|---|---|
| LSTM (تضمين: 256) | RESNET152 | عشوائي | 0.123 | 0.132 |
| جرو (تضمين: 256) | RESNET152 | عشوائي | 0.122 | 0.131 |
| LSTM (تضمين: 256) | VGG16 | عشوائي | 0.108 | 0.117 |
| بنيان | سي إن إن | التهيئة | طماع | شعاع = 3 |
|---|---|---|---|---|
| جرو (تضمين: 256) | RESNET152 | عشوائي | 0.317 | 0.351 |
| LSTM (تضمين: 256) | RESNET152 | عشوائي | 0.305 | 0.320 |
| LSTM (تضمين: 256) | VGG16 | عشوائي | 0.283 | 0.318 |
| LSTM (تضمين: 512) | RESNET152 | عشوائي | 0.270 | 0.317 |
| LSTM (تضمين: 256) | RESNET152 | كوكو تدرب مسبقا | 0.278 | 0.310 |
سيوضح هذا القسم كيف يمكن للمرء تدريب نموذج وصف الصور الخاص به.
أولاً ، يجب معالجة صور مجموعة بيانات COCO للتدريب.
python3 src/prepare/make_coco_dataset.py
--coco_path <path_to_cocoapi>
--interim_results_path <interim_results_path>
--results_path <final_results_path>
-COCO_PATH: مسار إلى Cocoapi Path (يمكن تنزيل من هنا)
-in-inters_results_path: مسار لتخزين النتائج المؤقتة (الافتراضي: البيانات/المؤقتة/)
-results_path: مسار لتخزين النتائج النهائية (الافتراضي: البيانات/المعالجة/)
هذا يخزن بالإضافة إلى ذلك مجموعة بيانات التسميات التوضيحية المدمجة في <coco_path> /annotations/coco_captions.csv.
python3 src/prepare/build_coco_vocabulary.py
--coco_path <path_to_cocoapi>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-COCO_PATH: مسار إلى Cocoapi Path (يمكن تنزيل من هنا)
-VOCAB_PATH: مسار إلى تخزين مفردات الكوكو (الافتراضية للبيانات/المعالجة/coco_vocab.pkl)
-عتبة: min word sickent لإضافتها إلى المفردات (الافتراضي: 5)
-مجموعات: مجموعات كوكو لتضمينها في بناء المفردات (الافتراضي: 'Train2014' ، 'Train2017')
python3 src/prepare/preprocess_coco_images.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
-نموذج: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['resnet18' ، 'resnet50' ، 'resnet152' ، 'vgg11' ، 'vgg11_bn' ، 'vgg16' ، 'vgg16_bn' ، 'vgg19 ،' vgg19_bn '،' "Densenet121" ، "Densenet201" ، "Inception"])
-DIR: مسار إلى صور Coco للتشفير باستخدام النموذج المختار
---Continue_processing: تشفير الصور المتبقية في الدليل
سيتم وضع الملفات المشفرة في DIR.
python3 src/ic_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path: مسار لتخزين النموذج النهائي (الافتراضي: النماذج/)
-beam_size: حجم شعاع للتحقق من الصحة (الافتراضي: 3)
-VOCAB_PATH: مسار إلى Coco Vocab (افتراضي: البيانات/المعالجة/COCO_VOCAB.PKL)
---Captions_Path: مسار إلى Coco Captions (افتراضي: OS.Environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-Imasages_Path: Path to Coco Iamges (افتراضي: OS.Environ ['home'] + '/database/coco/images/')
-LR: معدل التعلم للاستخدام (الافتراضي: 0.001)
-val_interval: تردد التحقق من الصحة (الافتراضي: 10)
-save_interval: حفظ تردد نقطة التفتيش (الافتراضي: 10)
-NUM_EPOCHS: عدد الحقبة للتدريب (الافتراضي: 1000)
-initial_checkpoint_file: نقطة تفتيش لبدء التدريب من (الافتراضي: لا شيء)
-التنفس: رقم إصدار النموذج (افتراضي: 11)
-batch_size: حجم الدُفعة (الافتراضي: 64)
-coco_set: مجموعة بيانات Coco للتدريب مع (افتراضي: 2014)
-tload_features: خيار تحميل أو بناء تضمينات الصورة (افتراضي: صحيح)
-TOLD_CAPTIONS: خيار تحميل أو إنشاء تضمينات التسمية التوضيحية (افتراضي: صحيح)
-التحميل: خيار لتحميل البيانات المسبقة إلى ذاكرة النظام قبل التدريب (الافتراضي: صحيح)
--Base_model: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['' resnet18 '،' resnet50 '،' resnet152 '،' vgg11 '،' vgg11_bn '،' vgg16 '،' vgg16_bn '،' vgg19 ، 'vgg19_bn' ، 'squeezen ،' squeezen ، "Densenet121" ، "Densenet201" ، "Inception"])
-embedding_size: حجم تضمين الصورة (افتراضي: 2048)
-embed_size: حجم إدخال RNN (افتراضي: 256)
-Hidden_Size: حجم الطبقة المخفية RNN (الافتراضي: 512)
-rnn_type: type rnn (افتراضي: 'lstm')
python3 src/ic_validate.py
--model_path <path_to_trained_ic_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_coco_vocab>
--captions_path <path_to_coco_captions_file>
--images_path <path_to_coco_image_embeddings>
--batch_size <batch_size>
--coco_set <coco_set>
--load_features <load_or_construct_image_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_image_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path: مسار إلى نموذج IC المدربين
-beam_size: حجم الشعاع للتحقق من الصحة
-VOCAB_PATH: مسار إلى Coco Vocab (افتراضي: البيانات/المعالجة/COCO_VOCAB.PKL)
---Captions_Path: مسار إلى Coco Captions (افتراضي: OS.Environ ['home'] + '/programs/cocoapi/annotations/coco_captions.csv')
-Imasages_Path: Path to Coco Images (افتراضي: OS.Environ ['home'] + '/database/coco/images/')
-batch_size: حجم الدُفعة (الافتراضي: 64)
-coco_set: مجموعة بيانات Coco للتدريب مع (افتراضي: 2014)
-tload_features: خيار تحميل أو بناء تضمينات الصورة (افتراضي: صحيح)
-TOLD_CAPTIONS: خيار تحميل أو إنشاء تضمينات التسمية التوضيحية (افتراضي: صحيح)
-التحميل: خيار لتحميل البيانات المسبقة إلى ذاكرة النظام قبل التدريب (الافتراضي: صحيح)
--Base_model: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['' resnet18 '،' resnet50 '،' resnet152 '،' vgg11 '،' vgg11_bn '،' vgg16 '،' vgg16_bn '،' vgg19 ، 'vgg19_bn' ، 'squeezen ،' squeezen ، "Densenet121" ، "Densenet201" ، "Inception"])
-embedding_size: حجم تضمين الصورة (افتراضي: 2048)
-embed_size: حجم إدخال RNN (افتراضي: 256)
-Hidden_Size: حجم الطبقة المخفية RNN (الافتراضي: 512)
-rnn_type: type rnn (افتراضي: 'lstm')
سيوضح هذا القسم كيف يمكن للمرء تدريب نموذج وصف الفيديو الخاص به.
أولاً ، يجب معالجة مقاطع الفيديو والتسميات التوضيحية MSR-VTT للتدريب.
python3 src/prepare/make_msrvtt_dataset.py
--raw_data_path <path_to_raw_msrvtt_data>
--interim_data_path <path_to_store_interim_data>
--final_data_path <path_to_store_final_data>
--continue_converting <continue_conversion>
--train_pct <percentage_to_allocate_to_training_set>
--dev_pct <percentage_to_allocate_to_development_set>
--- RAW_DATA_PATH: مسار إلى ملفات بيانات RAW MSRVTT (افتراضي: "البيانات/RAW/videodatainfo_2017_ustc.json ')
-interim_data_path: مسار لتخزين النتائج المؤقتة (الافتراضي: "البيانات/interim/')
--Fal_data_path: مسار لتخزين النتائج النهائية (الافتراضي: "البيانات/المعالجة/')
---Continue_Converting: مسار لمواصلة تحويل مجموعة بيانات MSR-VTT (افتراضي: صواب)
-TRAIN_PCT: النسبة المئوية لمجموعة البيانات التي يجب استخدامها للتدريب (الافتراضي: 0.8)
-DEV_PCT: النسبة المئوية لمجموعة البيانات التي يجب استخدامها للتطوير (الافتراضي: 0.15)
python3 src/prepare/build_msrvtt_vocabulary.py
--captions_path <path_to_captions>
--vocab_path <desired_path_of_vocab>
--threshold <min_word_threshold>
--sets <coco_sets_to_include>
-coco_path: المسار إلى التسميات التوضيحية MSR-VTT التي تم إنشاؤها بواسطة make_msrvtt_dataset.py (الافتراضي: "البيانات/المعالجة/msrvtt_captions.csv ')
-VOCAB_PATH: مسار لتخزين المفردات MSR-VTT (الافتراضية للبيانات/المعالجة/MSRVTT_VOCAB.PKL)
-عتبة: min word sickent لإضافتها إلى المفردات (الافتراضي: 5)
python3 src/prepare/preprocess_msrvtt_videos.py
--model <base_model_type>
--dir <path_to_images_to_encode>
--continue_preprocessing <continue_preprocessing?>
--resolution <CNN_input_resolution>
--num_frames <number_of_frames_to_encode>
--frames_interval <interval_between_frames>
--embedding_size <frame_embedding_size>
-نموذج: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['resnet18' ، 'resnet50' ، 'resnet152' ، 'vgg11' ، 'vgg11_bn' ، 'vgg16' ، 'vgg16_bn' ، 'vgg19 ،' vgg19_bn '،' "Densenet121" ، "Densenet201" ، "Inception"])
--DIR: مسار إلى مقاطع فيديو MSR-VTT للتشفير باستخدام النموذج المختار (افتراضي: OS.Environ ['home'] + '/database/msr-vtt/train-video/')
---Continue_processing: تشفير مقاطع الفيديو المتبقية في الدليل (افتراضي: صحيح)
-حل: دقة إدخال CNN (افتراضي: 224)
-Num_Frames: عدد الإطارات للتشفير (الافتراضي: 40)
-Frames_Interval: الفاصل بين الإطارات (افتراضي: 1)
-embedding_size: دقة CNN ouput (افتراضي: 2048)
سيتم وضع الملفات المشفرة في DIR.
python3 src/vc_trainer.py
--models_path <path_to_store_models>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--lr <learning_rate>
--val_interval <epoch_interval_to_validate_models>
--save_interval <epoch_inteval_to_save_model_checkpoints>
--num_epochs <epochs_to_train_for>
--initial_checkpoint_file <starting_model_checkpoint>
--version <model_version_number>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-models_path: مسار لتخزين النموذج النهائي (الافتراضي: النماذج/)
-beam_size: حجم شعاع للتحقق من الصحة (الافتراضي: 3)
-VOCAB_PATH: PATH إلى MSR-VTT VOCAB (افتراضي: البيانات/المعالجة/MSRVTT_VOCAB.PKL)
-captions_path: مسار إلى التسميات التوضيحية MSR-VTT (افتراضي: البيانات/المعالجة/msrvtt_captions.csv)
-Videos_Path: Path to MSR-VTT Videos (افتراضي: OS.Environ ['home'] + '/database/msr-vtt/train-video/')
-LR: معدل التعلم للاستخدام (الافتراضي: 0.001)
-val_interval: تردد التحقق من الصحة (الافتراضي: 10)
-save_interval: حفظ تردد نقطة التفتيش (الافتراضي: 10)
-NUM_EPOCHS: عدد الحقبة للتدريب (الافتراضي: 1000)
-initial_checkpoint_file: نقطة تفتيش لبدء التدريب من (الافتراضي: لا شيء)
-التنفس: رقم إصدار النموذج (افتراضي: 11)
-batch_size: حجم الدُفعة (الافتراضي: 64)
-tload_features: خيار تحميل أو بناء تضمينات الفيديو (افتراضي: صحيح)
-TOLD_CAPTIONS: خيار تحميل أو إنشاء تضمينات التسمية التوضيحية (افتراضي: صحيح)
-التحميل: خيار لتحميل البيانات المسبقة إلى ذاكرة النظام قبل التدريب (الافتراضي: صحيح)
--Base_model: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['' resnet18 '،' resnet50 '،' resnet152 '،' vgg11 '،' vgg11_bn '،' vgg16 '،' vgg16_bn '،' vgg19 ، 'vgg19_bn' ، 'squeezen ،' squeezen ، "Densenet121" ، "Densenet201" ، "Inception"])
-embedding_size: حجم تضمين الإطار (الافتراضي: 2048)
-embed_size: حجم إدخال RNN (افتراضي: 256)
-Hidden_Size: حجم الطبقة المخفية RNN (الافتراضي: 512)
-rnn_type: type rnn (افتراضي: 'lstm')
python3 src/vc_validate.py
--model_path <path_to_trained_vc_model>
--beam_size <beam_size_to_use_during_validation>
--vocab_path <path_to_msrvtt_vocab>
--captions_path <path_to_msrvtt_captions_file>
--videos_path <path_to_msrvtt_video_embeddings>
--batch_size <batch_size>
--load_features <load_or_construct_video_embeddings>
--load_captions <load_or_constructed_caption_encodings>
--preload <preload_image_and_caption_encodings_prior_to_training>
--base_model <CNN_encoder_model>
--embedding_size <size_of_frame_embedding>
--embed_size <size_of_RNN_input>
--hidden_size <RNN_hidden_size>
--rnn_type <type_of_RNN_unit_to_use>
-model_path: مسار إلى نموذج وصف الفيديو المدربين
-beam_size: حجم الشعاع للتحقق من الصحة
-VOCAB_PATH: PATH إلى MSR-VTT VOCAB (افتراضي: البيانات/المعالجة/MSRVTT_VOCAB.PKL)
-captions_path: مسار إلى التسميات التوضيحية MSR-VTT (افتراضي: البيانات/المعالجة/msrvtt_captions.csv)
-Videos_Path: Path to MSR-VTT Videos (افتراضي: OS.Environ ['home'] + '/database/msr-vtt/train-video/')
-batch_size: حجم الدُفعة (الافتراضي: 64)
-tload_features: خيار تحميل أو بناء تضمينات الفيديو (افتراضي: صحيح)
-TOLD_CAPTIONS: خيار تحميل أو إنشاء تضمينات التسمية التوضيحية (افتراضي: صحيح)
-التحميل: خيار لتحميل البيانات المسبقة إلى ذاكرة النظام قبل التدريب (الافتراضي: صحيح)
--Base_model: نموذج CNN الأساسي لاستخدامه في المعالجة المسبقة (الخيارات: ['' resnet18 '،' resnet50 '،' resnet152 '،' vgg11 '،' vgg11_bn '،' vgg16 '،' vgg16_bn '،' vgg19 ، 'vgg19_bn' ، 'squeezen ،' squeezen ، "Densenet121" ، "Densenet201" ، "Inception"])
-embedding_size: حجم تضمين الإطار (الافتراضي: 2048)
-embed_size: حجم إدخال RNN (افتراضي: 256)
-Hidden_Size: حجم الطبقة المخفية RNN (الافتراضي: 512)
-rnn_type: type rnn (افتراضي: 'lstm')


