Hindi ASR and TTS
1.0.0
在這個項目中,我們專注於為低資源的語言印地語創建自動語音識別(ASR)和文本(TTS)模塊。
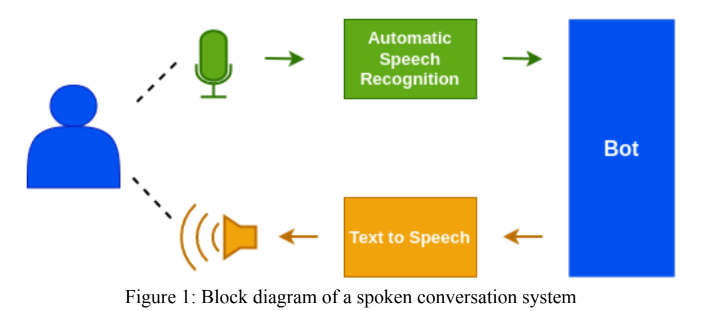
印地語ASR模塊是使用Facebook的WAV2VEC 2.0型號設計的。在“開放”和“自我監督”類別中,還提交了“革蘭州vaani asr挑戰2022”。對於開放挑戰,我們使用了Vakyansh的預訓練模型,名為“ Clsril-23”,並使用100小時的電話標記數據進行了微調。對於自我監督的挑戰,我們最初使用1000小時電話未標記的數據設計了預訓練的模型,然後使用100小時電話標記的數據進行了填充。一種語言模型,在解碼步驟中使用了Kenlm,以提高模型的準確性。
使用tacotron2和平行波甘模型開發了印地語TTS模型。 TTS合成器主要包含兩個模塊,一個是“光譜圖預測網絡”和“ vocoder”。 Tacotron2是由Google開發的AI驅動的端到端語音綜合模型。它將處理的字符作為輸入,並具有將其轉換為語音波形的能力。在我們的項目中,我們使用Tacotron2模型只是為我們創建聲學功能。然後將聲學和光譜特徵饋送到一個名為“ Parallel Wavegan”的Vocoder,我們將語音作為輸出。兩種型號均經過21.46小時IIT Madras Hindi Dataset(女聲音)的培訓。


