Hindi ASR and TTS
1.0.0
En este proyecto, nos hemos centrado en crear un módulo automático de reconocimiento de voz (ASR) y texto a discurso (TTS) para un lenguaje indic de bajo recurso hindi.
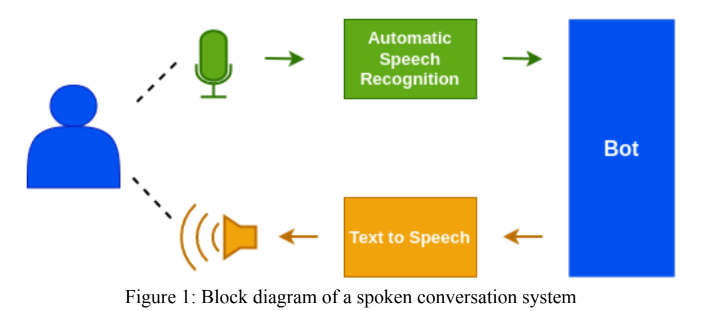
El módulo Hindi ASR fue diseñado utilizando el modelo WAV2VEC 2.0 de Facebook. También se hicieron presentaciones a la 'Gram Vaani Asr Challenge 2022' en las categorías 'abiertas' y 'auto-supervisadas'. Para el desafío abierto, hemos utilizado un modelo previamente capacitado de Vakyansh llamado 'CLSRIL-23' y ajustado aún más utilizando datos etiquetados telefónicos de 100 horas. Para el desafío auto-supervisado, inicialmente diseñamos un modelo previamente capacitado que usa datos telefónicos de 1000 horas y luego fingidos con datos telefónicos de 100 horas. Un modelo de idioma, KenLM se utilizó en el paso de decodificación para mejorar la precisión del modelo.
El modelo Hindi TTS se desarrolló utilizando modelos Tacotron2 y Wavan Paralelo. El sintetizador TTS contiene principalmente dos módulos, uno es 'Red de predicción de espectrograma' y 'Vocoder'. Tacotron2 es un modelo de síntesis de habla de extremo a extremo con IA desarrollado por Google. Se necesitan caracteres procesados como entrada y tiene la capacidad de convertirlos en una forma de onda del habla. En nuestro proyecto, hemos utilizado el modelo Tacotron2 para crear las características acústicas para nosotros. Las características acústicas y espectrales se alimentan a un vocoder llamado 'paralelo Wavan' donde obtenemos el discurso como salida. Ambos modelos están entrenados en 21.46 horas IIT Madras Hindi DataSet (voz femenina).


