Hindi ASR and TTS
1.0.0
ในโครงการนี้เราได้เพ่งความสนใจไปที่การสร้างโมดูลการรู้จำเสียงพูดอัตโนมัติ (ASR) และโมดูลข้อความเป็นคำพูด (TTS) สำหรับภาษาฮินดีอินดิคชั่นทรัพยากรต่ำ
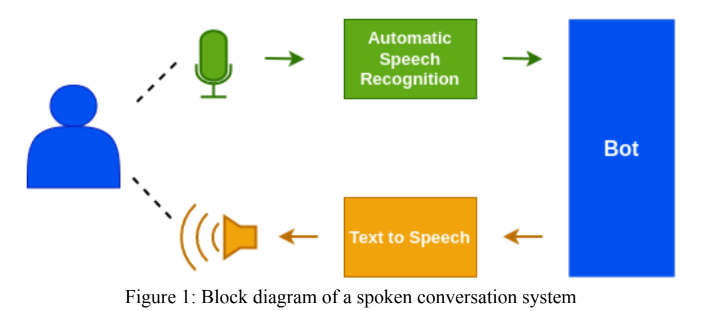
โมดูล Hindi ASR ได้รับการออกแบบโดยใช้โมเดล WAV2VEC 2.0 ของ Facebook นอกจากนี้ยังมีการส่งผลงานให้กับ 'Gram Vaani ASR Challenge 2022' ในหมวดหมู่ 'เปิด' และ 'ผู้ดูแลตนเอง' สำหรับความท้าทายแบบเปิดเราได้ใช้โมเดลที่ผ่านการฝึกอบรมมาก่อนโดย Vakyansh ชื่อ 'Clsril-23' และปรับแต่งเพิ่มเติมโดยใช้ข้อมูลที่มีป้ายกำกับโทรศัพท์ 100 ชั่วโมง สำหรับความท้าทายที่ดูแลตนเองเราได้ออกแบบโมเดลที่ผ่านการฝึกอบรมมาก่อนโดยใช้ข้อมูลที่ไม่มีป้ายกำกับโทรศัพท์ 1,000 ชั่วโมงจากนั้นใช้ข้อมูลที่มีป้ายกำกับโทรศัพท์ 100 ชั่วโมง รูปแบบภาษา Kenlm ถูกใช้ในขั้นตอนการถอดรหัสเพื่อปรับปรุงความแม่นยำของโมเดล
แบบจำลองภาษาฮินดี TTS ได้รับการพัฒนาโดยใช้ Tacotron2 และโมเดล Wavegan แบบขนาน TTS synthesizer ส่วนใหญ่มีสองโมดูลหนึ่งคือ 'เครือข่ายการทำนาย Spectrogram' และ 'vocoder' Tacotron2 เป็นรูปแบบการสังเคราะห์คำพูดแบบ end-to-end ที่พัฒนาโดย AI ที่พัฒนาโดย Google ต้องใช้อักขระประมวลผลเป็นอินพุตและมีความสามารถในการแปลงเป็นรูปคลื่นเสียงพูด ในโครงการของเราเราได้ใช้โมเดล Tacotron2 เพื่อสร้างคุณสมบัติอะคูสติกสำหรับเรา คุณสมบัติอคูสติกและสเปกตรัมจะถูกป้อนไปยังผู้ร้องชื่อ 'Wavegan คู่ขนาน' ที่ซึ่งเราได้รับคำพูดเป็นเอาท์พุท ทั้งสองรุ่นได้รับการฝึกฝนเมื่อ 21.46hrs IIT Madras Hindi ชุดข้อมูล (เสียงหญิง)


