Hindi ASR and TTS
1.0.0
このプロジェクトでは、低リソースインド言語ヒンディー語の自動音声認識(ASR)とテキスト(TTS)モジュールの作成に焦点を当てています。
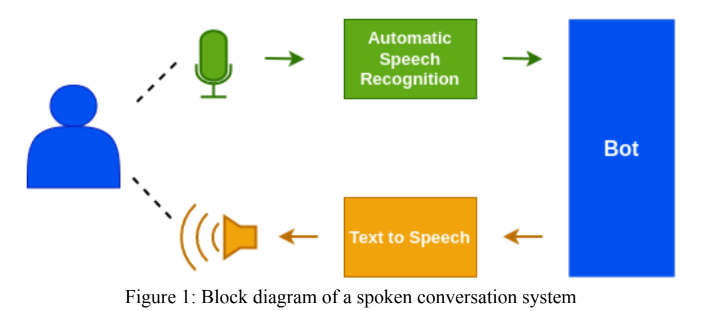
Hindi ASRモジュールは、FacebookのWAV2VEC 2.0モデルを使用して設計されました。また、「オープン」および「自己監視」カテゴリの「Gram Vaani Asr Challenge 2022」にも提出が行われました。オープンチャレンジのために、「Clsril-23」という名前のVakyanshによる事前に訓練されたモデルを使用し、100時間の電話のラベル付きデータを使用してさらに微調整しました。自己教師の課題のために、最初に1000時間の電話電話の非標識データを使用して事前に訓練されたモデルを設計し、100時間の電話のラベル付きデータを使用して微調整しました。言語モデルであるKenlmは、モデルの精度を向上させるためにデコードステップで使用されました。
Hindi TTSモデルは、Tacotron2およびParallel Wavganモデルを使用して開発されました。 TTSシンセサイザーには、主に2つのモジュールが含まれています。1つは「スペクトログラム予測ネットワーク」と「ボコーダー」です。 Tacotron2は、Googleが開発したAI駆動のエンドツーエンドの音声合成モデルです。処理された文字を入力として使用し、音声波形に変換する機能を備えています。私たちのプロジェクトでは、Tacotron2モデルを使用して、音響機能を作成するだけです。次に、音響とスペクトルの特徴を「Parallel Wavegan」という名前のボコーダーに供給し、出力として音声が得られます。両方のモデルは、21.46時間IITマドラスヒンディー語データセット(女性の声)でトレーニングされています。


