Hindi ASR and TTS
1.0.0
Neste projeto, focamos na criação de um módulo de reconhecimento automático de fala (ASR) e texto para a fala (TTS) para o Hindi da linguagem indicada de baixo recurso.
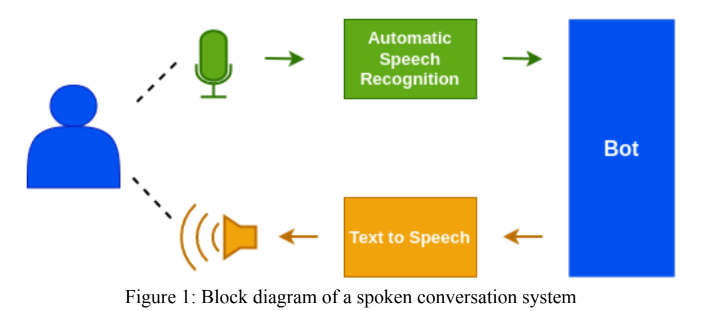
O módulo Hindi ASR foi projetado usando o modelo WAV2VEC 2.0 do Facebook. Também foram feitos envios para o 'Gram Vaani ASR Challenge 2022' nas categorias 'abertas' e 'auto-supervisionadas'. Para o desafio aberto, usamos um modelo pré-treinado por Vakyansh chamado 'CLSRIL-23' e ainda mais ajustado usando dados telefônicos de 100 horas. Para o desafio auto-supervisionado, projetamos inicialmente um modelo pré-treinado usando dados não marcados por 1000HRs e depois FinetunEd usando dados rotulados por telefone de 100 horas. Um modelo de idioma, o Kenlm foi usado na etapa de decodificação para melhorar a precisão do modelo.
O modelo Hindi TTS foi desenvolvido usando modelos Tacotron2 e Parallel Wavegan. O sintetizador TTS contém principalmente dois módulos, sendo um 'rede de previsão de espectrograma' e 'vocoder'. O Tacotron2 é um modelo de síntese de fala de ponta a ponta da IA desenvolvido pelo Google. Ele toma caracteres processados como entrada e tem a capacidade de convertê -los em uma forma de onda de fala. Em nosso projeto, usamos o modelo Tacotron2 para criar apenas os recursos acústicos para nós. Os recursos acústicos e espectrais são então alimentados a um vocoder chamado 'Parallel Wavegan', onde recebemos discursos como saída. Ambos os modelos são treinados em 21.46hrs iit madras hindi conjuntos de dados (voz feminina).


