Hindi ASR and TTS
1.0.0
Dans ce projet, nous nous sommes concentrés sur la création d'un module automatique de reconnaissance vocale (ASR) et de discours (TTS) pour le langage indic à faible ressource hindi.
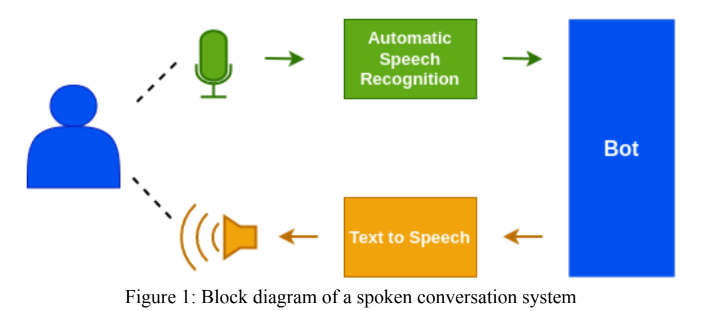
Le module Hindi ASR a été conçu à l'aide du modèle WAV2VEC 2.0 de Facebook. Des soumissions ont également été faites au «Gram Vaani ASR Challenge 2022» dans les catégories «ouvertes» et «auto-supervisées». Pour le défi ouvert, nous avons utilisé un modèle pré-formé par Vakyansh nommé «CLSril-23» et encore affiné en utilisant des données marquées téléphoniques de 100 heures. Pour le défi auto-supervisé, nous avons initialement conçu un modèle pré-formé en utilisant des données téléphoniques téléphoniques de 1000 heures, puis des données finetues à l'aide de données marquées téléphoniques de 100 heures. Un modèle de langue, Kenlm a été utilisé dans l'étape de décodage pour améliorer la précision du modèle.
Le modèle hindi TTS a été développé en utilisant des modèles Tacotron2 et Wavegan parallèles. Le synthétiseur TTS contient principalement deux modules, l'un étant le «réseau de prédiction de spectrogramme» et «Vocoder». Tacotron2 est un modèle de synthèse vocal de bout en bout alimenté par AI développé par Google. Il prend des caractères traités comme entrée et a la capacité de les convertir en forme d'onde de parole. Dans notre projet, nous avons utilisé le modèle Tacotron2 pour créer simplement les fonctionnalités acoustiques pour nous. Les caractéristiques acoustiques et spectrales sont ensuite transférées à un vocodeur nommé «parallèle Wavegan» où nous obtenons la parole comme sortie. Les deux modèles sont formés sur 21,46 heures IIT Madras Hindi Dataset (voix féminine).


