Hindi ASR and TTS
1.0.0
在这个项目中,我们专注于为低资源的语言印地语创建自动语音识别(ASR)和文本(TTS)模块。
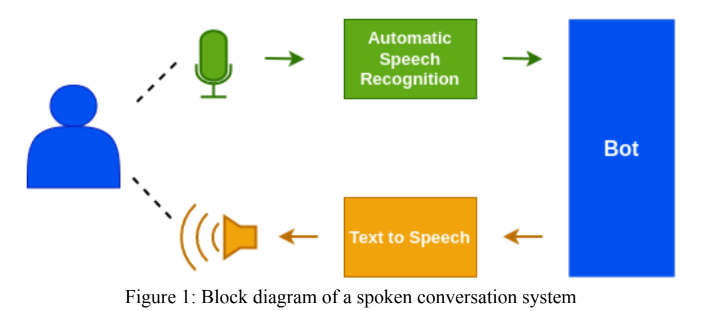
印地语ASR模块是使用Facebook的WAV2VEC 2.0型号设计的。在“开放”和“自我监督”类别中,还提交了“革兰州vaani asr挑战2022”。对于开放挑战,我们使用了Vakyansh的预训练模型,名为“ Clsril-23”,并使用100小时的电话标记数据进行了微调。对于自我监督的挑战,我们最初使用1000小时电话未标记的数据设计了预训练的模型,然后使用100小时电话标记的数据进行了填充。一种语言模型,在解码步骤中使用了Kenlm,以提高模型的准确性。
使用tacotron2和平行波甘模型开发了印地语TTS模型。 TTS合成器主要包含两个模块,一个是“光谱图预测网络”和“ vocoder”。 Tacotron2是由Google开发的AI驱动的端到端语音综合模型。它将处理的字符作为输入,并具有将其转换为语音波形的能力。在我们的项目中,我们使用Tacotron2模型只是为我们创建声学功能。然后将声学和光谱特征馈送到一个名为“ Parallel Wavegan”的Vocoder,我们将语音作为输出。两种型号均经过21.46小时IIT Madras Hindi Dataset(女声音)的培训。


