Hindi ASR and TTS
1.0.0
이 프로젝트에서는 낮은 리소스 표시 힌디어를위한 자동 음성 인식 (ASR) 및 TTS (Text to Speech) 모듈을 만드는 데 중점을 두었습니다.
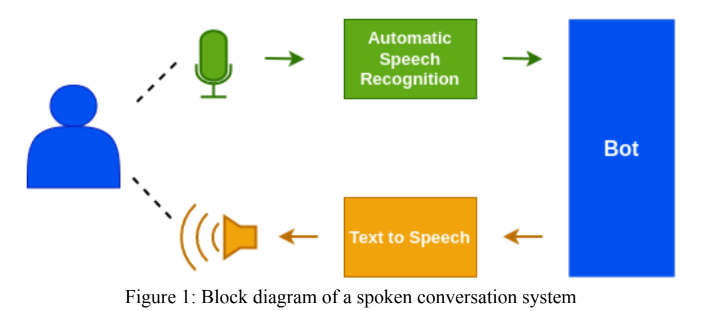
Hindi ASR 모듈은 Facebook의 WAV2VEC 2.0 모델을 사용하여 설계되었습니다. 'Open'및 'self-supervised'카테고리에서 'Gram Vaani ASR 챌린지 2022'에 제출이 이루어졌습니다. Open Challenge의 경우 Vakyansh의 'Clsril-23'이라는 미리 훈련 된 모델을 사용하고 100 시간의 전화로 표시된 데이터를 사용하여 추가로 미세 조정했습니다. 자체 감독 챌린지를 위해 처음에는 1000 시간 전화 방사선 데이터를 사용하여 미리 훈련 된 모델을 설계 한 다음 100hrs 전화 레이블이 붙은 데이터를 사용하여 양조했습니다. 언어 모델 인 Kenlm은 디코딩 단계에서 모델의 정확도를 향상시키기 위해 사용되었습니다.
힌디어 TTS 모델은 Tacotron2 및 병렬 웨이 저 모델을 사용하여 개발되었습니다. TTS 합성기에는 주로 두 개의 모듈이 포함되어 있으며, 하나는 '스펙트로 그램 예측 네트워크'및 '보코더'입니다. Tacotron2는 Google에서 개발 한 AI 기반 엔드 투 엔드 스피치 합성 모델입니다. 처리 된 문자를 입력으로 필요로하며 음성 파형으로 변환 할 수 있습니다. 우리의 프로젝트에서 우리는 Tacotron2 모델을 사용하여 우리를위한 음향 기능을 만듭니다. 그런 다음 음향 및 스펙트럼 특징은 출력으로 음성을 얻는 'Parallel Weavegan'이라는 보코더로 공급됩니다. 두 모델 모두 21.46HRS IIT Madras 힌디어 데이터 세트 (여성 음성)에서 교육을받습니다.


