Hindi ASR and TTS
1.0.0
In diesem Projekt haben wir uns darauf konzentriert, ein automatisches Spracherkennung (ASR) und ein Text -to -Sprachmodul (TTS) für die Niedrigressource -Indic -Sprache Hindi zu erstellen.
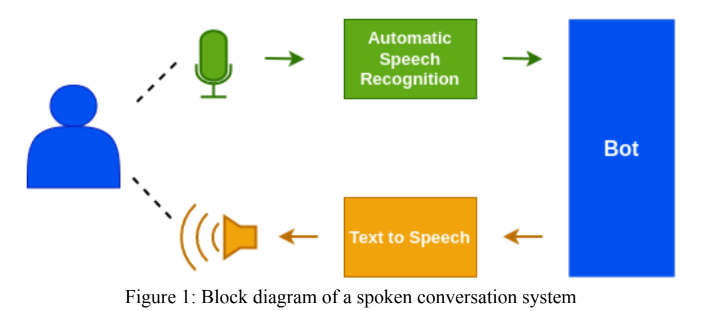
Das Hindi ASR -Modul wurde mit dem WAV2VEC 2.0 -Modell von Facebook entworfen. Einsendungen wurden auch in die "Gram Vaani ASR Challenge 2022" in den Kategorien "Open" und "Selbstversorgung" gemacht. Für die offene Herausforderung haben wir ein vorgebildetes Modell von Vakyansh mit dem Namen "CLSRIL-23" verwendet und mit telefonisch gekennzeichneten 100-Stunden-Daten weiter fein abgestimmt. Für die selbstbewertete Herausforderung haben wir zunächst ein vorgebildetes Modell unter Verwendung von 1000-Stunden-telemonischen Daten entworfen und anschließend mit telefonisch gekennzeichneten 100-Stunden-Daten abgeschlossen. Kenlm, ein Sprachmodell, wurde im Dekodierungsschritt verwendet, um die Genauigkeit des Modells zu verbessern.
Das Hindi TTS -Modell wurde unter Verwendung von Tacotron2- und Parallel -Wavegegan -Modellen entwickelt. Der TTS -Synthesizer enthält hauptsächlich zwei Module, von denen eines das "Spektrogram -Vorhersage -Netzwerk" und "Vocoder" ist. Tacotron2 ist ein von Google entwickelter KI-angetriebenes End-to-End-Sprachsynthesemodell. Es dauert verarbeitete Zeichen als Eingabe und kann sie in eine Sprachwellenform umwandeln. In unserem Projekt haben wir das Tacotron2 -Modell verwendet, um nur die akustischen Merkmale für uns zu erstellen. Die akustischen und spektralen Merkmale werden dann an einen Vokoder mit dem Namen "Parallel Wavegan" versetzt, in dem wir die Sprache als Ausgabe erhalten. Beide Modelle sind auf 21,46 Stunden ausgebildet.


