Hindi ASR and TTS
1.0.0
В этом проекте мы сосредоточились на создании автоматического распознавания речи (ASR) и модуля текста в речи (TTS) для языка с низким уровнем индикации ресурсов хинди.
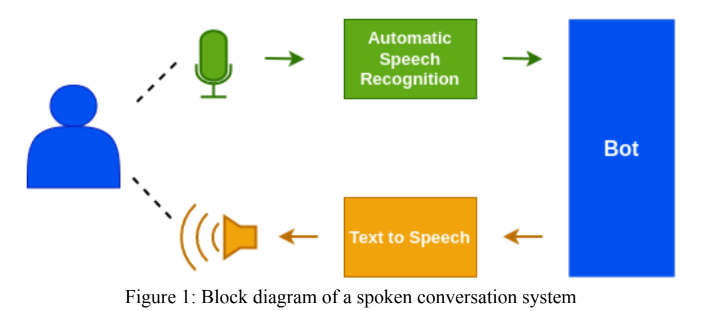
Модуль хинди ASR был разработан с использованием модели Facebook Wav2VEC 2.0. Материалы также были сделаны в «Грамм Ваани Ас-Аср» 2022 года в «открытых» и «самоотверженных» категориях. Для открытой задачи мы использовали предварительно обученную модель Вакьянша, названную «CLSRIL-23» и дополнительно настраивали с использованием 100-часовых телефонных данных. Для самоотверженной задачи мы изначально разработали предварительно обученную модель с использованием 1000-часовых телефонных неметочных данных, а затем созданы с использованием 100-часовых телефонных данных. Языковая модель, Kenlm использовалась на этапе декодирования для повышения точности модели.
Модель хинди была разработана с использованием моделей Tacotron2 и Parallel Wavegan. Синтезатор TTS в основном содержит два модуля, один из которых является «сетью прогнозирования спектрограммы» и «Vocoder». Tacotron2-это модель сквозного синтеза речи с AI, разработанная Google. Он принимает обработанные символы в качестве ввода и способен преобразовать их в речевую форму. В нашем проекте мы использовали модель Tacotron2, чтобы просто создать акустические функции для нас. Акустические и спектральные особенности затем питаются вокодером под названием «Parallel Wawgan», где мы получаем речь в качестве вывода. Обе модели обучены 21,46 часам набора данных Hindi IIT Madras (женский голос).


