Hindi ASR and TTS
1.0.0
Dalam proyek ini, kami telah fokus pada pembuatan modul pengenalan ucapan otomatis (ASR) dan teks ke bicara (TTS) untuk bahasa Hindi indic sumber daya rendah.
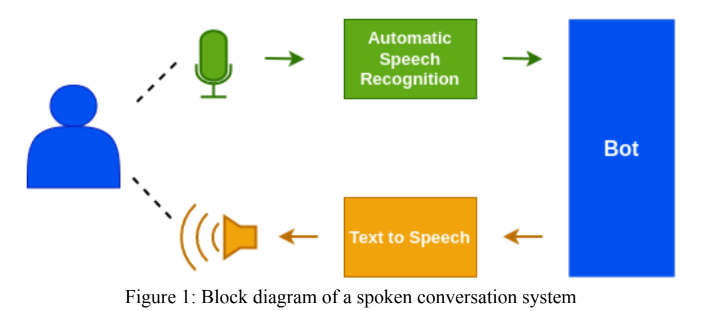
Modul Hindi ASR dirancang menggunakan model WAV2VEC 2.0 Facebook. Pengajuan juga dilakukan untuk 'Gram Vaani ASR Challenge 2022' dalam kategori 'terbuka' dan 'swadaya'. Untuk tantangan terbuka, kami telah menggunakan model pra-terlatih oleh Vakyansh bernama 'Clsril-23' dan selanjutnya disesuaikan menggunakan data berlabel telepon 100 jam. Untuk tantangan yang di-kupervis, kami awalnya merancang model pra-terlatih menggunakan data tidak berlabel telepon 1000 jam dan kemudian Finetuned menggunakan data berlabel telepon 100 jam. Model bahasa, Kenlm digunakan dalam langkah decoding untuk meningkatkan akurasi model.
Model Hindi TTS dikembangkan menggunakan model TACOTRON2 dan paralel Wavegan. TTS synthesizer terutama berisi dua modul, satu menjadi 'jaringan prediksi spektrogram' dan 'vocoder'. TACOTRON2 adalah model sintesis ucapan end-to-end bertenaga AI yang dikembangkan oleh Google. Dibutuhkan karakter yang diproses sebagai input dan memiliki kemampuan untuk mengubahnya menjadi bentuk gelombang ucapan. Dalam proyek kami, kami telah menggunakan model Tacotron2 untuk hanya membuat fitur akustik untuk kami. Fitur akustik dan spektral kemudian diumpankan ke vokoder bernama 'Parallel Wavegan' di mana kita mendapatkan ucapan sebagai output. Kedua model dilatih pada 21.46 jam IIT Madras Hindi dataset (suara wanita).


