Hindi ASR and TTS
1.0.0
في هذا المشروع ، ركزنا على إنشاء وحدة التعرف التلقائي على الكلام (ASR) ووحدة النص إلى الكلام (TTS) لـ Low Resource Incurn Language Hindi.
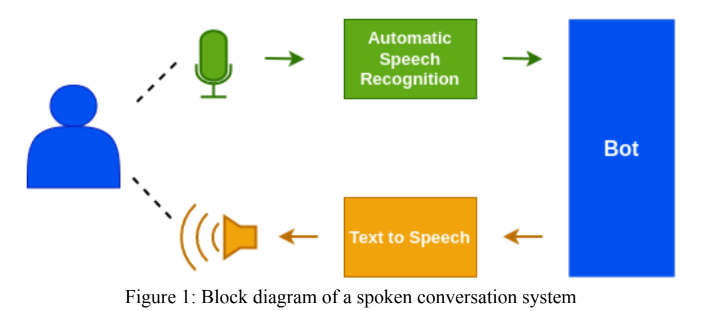
تم تصميم وحدة ASR الهندية باستخدام نموذج WAV2VEC 2.0 من Facebook. كما تم تقديم الطلبات إلى "Gram Vaani ASR Challenge 2022" في فئات "Open" و "الخاضعين للإشراف". بالنسبة للتحدي المفتوح ، استخدمنا نموذجًا تم تدريبه مسبقًا بواسطة Vakyansh يسمى "CLSRIL-23" ومزيد من ضبطه باستخدام بيانات تليفوني 100 ساعة. بالنسبة للتحدي الذي تم إشرافه ذاتيًا ، قمنا في البداية بتصميم نموذج تم تدريبه مسبقًا باستخدام بيانات غير مطلقة على بعد 1000 ساعة ، ثم تم تصميمها باستخدام بيانات تليفونية 100 ساعة. نموذج لغة ، تم استخدام Kenlm في خطوة فك التشفير لتحسين دقة النموذج.
تم تطوير نموذج TTS الهندي باستخدام نماذج Tacotron2 ونماذج الموجة الموازية. يحتوي مزج TTS بشكل أساسي على وحدتين ، أحدهما "شبكة تنبؤات طيفية" و "Vocoder". Tacotron2 هو نموذج توليف الكلام من طراز AI الذي يعمل به منظمة العفو الدولية التي طورتها Google. يتطلب الأمر الأحرف المصنعة كمدخلات ولديه القدرة على تحويلها إلى شكل موجي للكلام. في مشروعنا ، استخدمنا نموذج Tacotron2 لإنشاء الميزات الصوتية بالنسبة لنا. ثم يتم تغذية الميزات الصوتية والطيفية إلى مفردات تسمى "Wavegan" حيث نحصل على الكلام كإخراج. يتم تدريب كلا النموذجين على 21.46 ساعة IIT MADRAS HINDI DATASET (صوت أنثى).


