WhisperSpeech
1.0.0
如果您有疑問或想幫助您可以在Laion Discord服務器上的#音頻生成頻道中找到我們。
通過反轉耳語構建的開源文本到語音系統。以前稱為Spear-Tts-Pytorch 。
我們希望該模型像穩定的擴散一樣,但對於語音來說 - 既強大又易於自定義。
我們僅使用適當許可的語音記錄,所有代碼都是開源的,因此該模型始終可以安全用於商業應用程序。
目前,這些模型已在英語liblelight數據集上進行培訓。在下一個版本中,我們想針對多種語言(Whisper和codec都是多語言)。
綜合語音樣本:
我們在EN+PL+FR數據集上成功培訓了一個tiny S2A模型,它可以用法語進行語音克隆:
我們能夠使用僅接受英語和波蘭語訓練的冷凍語義令牌來做到這一點。這支持了我們能夠培訓單個語義令牌模型以支持世界上所有語言的想法。即使是當前不受耳語模型支持的人也很可能。請繼續關注此方面的更多更新。 :)
我們將上週花費了優化推理性能。我們集成了torch.compile ,添加了kV攝取並調整了一些層 - 現在,我們在消費者4090上的工作速度比實時快12倍!
我們可以用一句話混合語言(在這裡突出顯示的英語項目名稱無縫地混合到波蘭語音中):
開玩笑,Pierwszy測試Wielojęzycznego
Whisper Speech模型Zamieniającegotekst naMowę,CollaboraiLaionnauczyli nauczyli na superkomputerzeJewels。
我們還添加了一種簡單的方法來測試語音粘結。這是溫斯頓·丘吉爾(Winston Churchill)著名演講的樣本聲音(無線電靜態是一個功能,而不是錯誤;) - 它是參考錄音的一部分):
您可以在COLAB上測試所有這些(我們優化了依賴項,因此現在不到30秒才能安裝)。擁抱面空間即將到來。
我們推出了一種新的SD S2A模型,該模型在仍在產生高質量演講的同時更快。我們還根據參考音頻文件添加了語音克隆的示例。
與往常一樣,您可以查看我們的colab自己嘗試一下!
另一個三人模型,這次它們支持多種語言(英語和波蘭語)。這是偷看的兩個新樣本。您可以查看我們的Colab自己嘗試一下!
英語演講,女性聲音(從波蘭語言數據集轉移):
波蘭樣本,男性聲音:
較舊的進度更新在這裡存檔
我們鼓勵您從上面的Google Colab鏈接開始,或在本地運行提供的筆記本。如果您想手動下載或從頭開始訓練模型,則在HuggingFace上都可以使用Whisperspeech預訓練的模型以及轉換後的數據集。
通用架構類似於Audiolm,Google的Spear TT和Meta的Musicgen。我們避免了NIH綜合徵,並在功能強大的開源模型的頂部建立了它:從Openai竊竊私語,生成語義令牌並執行轉錄,從Meta for Meta進行聲學建模和containtr Inc的VOCOS作為高質量的Vocoder。
我們給了兩個演講,深入研究了竊竊私語。第一個談論大規模培訓的挑戰:
從縮放低語模型到80k+小時的語音 - jakubcłapa錄製的技巧
另一個是我們做出的建築選擇的更多信息:
開源文本到語音項目:竊竊私語 - 深度討論
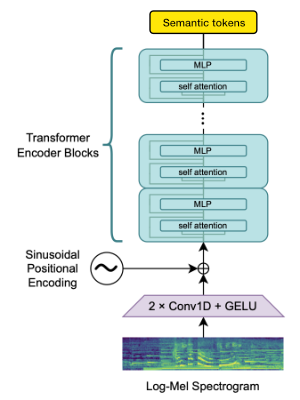
我們利用OpenAi Whisper編碼器塊來生成嵌入,然後進行量化以獲取語義令牌。
如果語言已經受到竊竊私語的支持,那麼此過程僅需要音頻文件(沒有地面真相轉錄)。
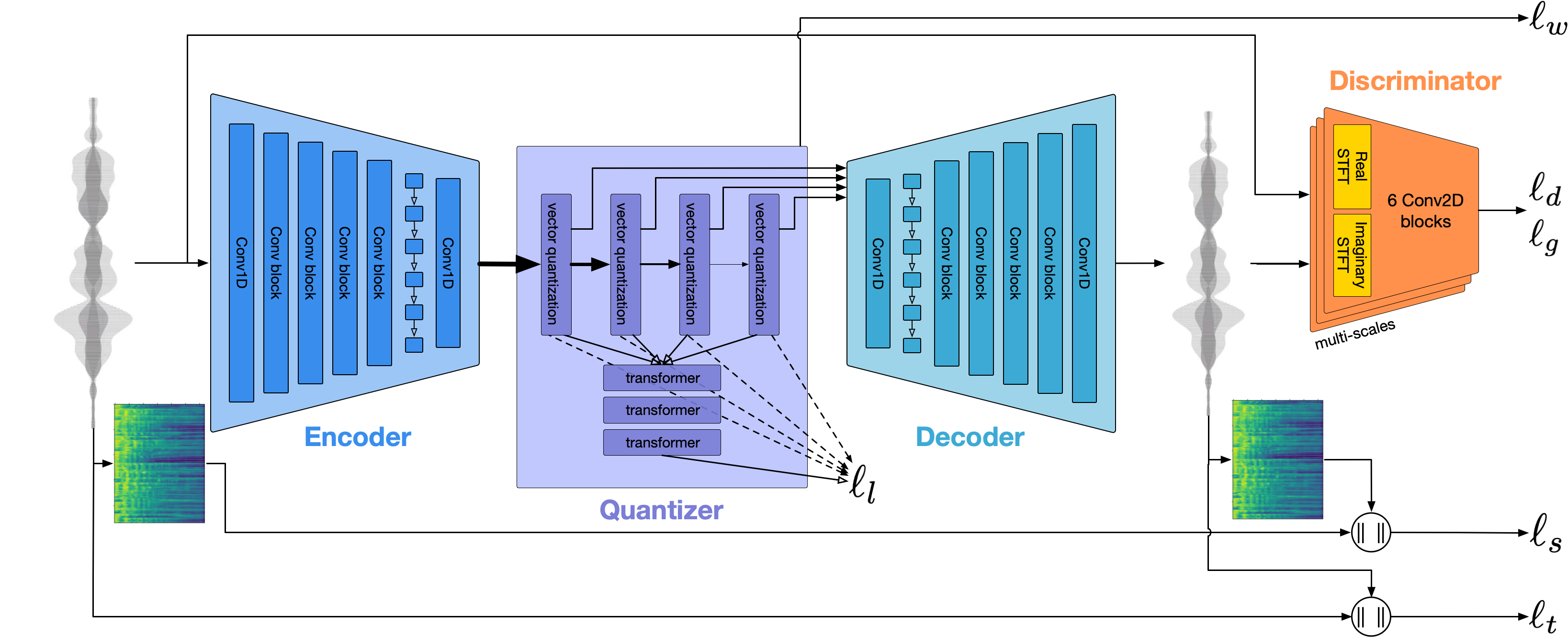
我們使用Encodec對音頻波形進行建模。開箱即用,它以1.5kbps的形式提供合理的質量,我們可以使用VOCOS(在Eccodec代幣上仔細預測的Vocos)將其提高到高質量。


沒有慷慨的讚助,這項工作將是不可能的:
我們非常感謝高斯超級計算中心(www.gauss-centre.eu)通過在GCS超級計算中心(JSC)的GCS超級計算機Booster上通過John von Neumann計算研究所(NIC)提供計算時間來資助這項工作的一部分,並提供了訪問的訪問。
我們還要感謝個人貢獻者在建立此模型方面的巨大幫助:
qwerty_qwer 我們可以為您提供開源和專有AI項目的幫助。您可以通過Collabora網站或Discord(和)與我們聯繫
我們依靠許多驚人的開源項目和研究論文:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

