WhisperSpeech
1.0.0
หากคุณมีคำถามหรือคุณต้องการช่วยคุณสามารถค้นหาเราได้ในช่องสัญญาณรุ่น #เสียงบนเซิร์ฟเวอร์ Laion Discord
ระบบโอเพ่นซอร์สข้อความเป็นคำพูดที่สร้างขึ้นโดยการกระซิบแบบคว่ำ ก่อนหน้านี้รู้จักกันในชื่อ Spear-TTS-Pytorch
เราต้องการให้โมเดลนี้เป็นเหมือนการแพร่กระจายที่มั่นคง แต่สำหรับการพูด - ทั้งที่ทรงพลังและปรับแต่งได้ง่าย
เรากำลังทำงานกับการบันทึกเสียงพูดที่ได้รับใบอนุญาตอย่างเหมาะสมและรหัสทั้งหมดเป็นโอเพ่นซอร์สดังนั้นโมเดลจะปลอดภัยที่จะใช้สำหรับแอปพลิเคชันเชิงพาณิชย์เสมอ
ปัจจุบันรุ่นได้รับการฝึกฝนในชุดข้อมูล Librelight ภาษาอังกฤษ ในการเปิดตัวครั้งต่อไปเราต้องการกำหนดเป้าหมายหลายภาษา (Whisper และ ENCODEC เป็นทั้งภาษาหลายภาษา)
ตัวอย่างของเสียงสังเคราะห์:
เราได้ฝึกอบรมแบบจำลอง S2A tiny บนชุดข้อมูล EN+PL+FR สำเร็จและสามารถทำการโคลนนิ่งด้วยเสียงเป็นภาษาฝรั่งเศส:
เราสามารถทำสิ่งนี้ได้ด้วยโทเค็นความหมายแช่แข็งที่ได้รับการฝึกฝนเกี่ยวกับภาษาอังกฤษและภาษาโปแลนด์เท่านั้น สิ่งนี้สนับสนุนแนวคิดที่ว่าเราจะสามารถฝึกอบรมโมเดลโทเค็นความหมายเดียวเพื่อสนับสนุนทุกภาษาในโลก ค่อนข้างน่าจะเป็นคนที่ไม่ได้รับการสนับสนุนอย่างดีจากโมเดล Whisper คอยติดตามการอัปเดตเพิ่มเติมที่ด้านหน้านี้ -
เราใช้เวลาในสัปดาห์ที่ผ่านมาเพื่อเพิ่มประสิทธิภาพการอนุมาน เรารวม torch.compile เพิ่ม KV-caching และปรับเลเยอร์บางชั้น-ตอนนี้เราทำงานเร็วกว่า 12x เร็วกว่าเวลาจริงบนผู้บริโภค 4090!
เราสามารถผสมภาษาในประโยคเดียว (นี่คือชื่อโครงการภาษาอังกฤษที่เน้นเป็นคำพูดภาษาโปแลนด์อย่างราบรื่น):
Laionตลกการทดสอบ pierwszy wielojęzycznegoWhisper SpeechModelu zamieniającego tekst na mowę, KtóryCollaboraJewels
นอกจากนี้เรายังเพิ่มวิธีที่ง่ายในการทดสอบการโคลนนิ่งด้วยเสียง นี่คือตัวอย่างเสียงที่ถูกโคลนจากคำพูดที่มีชื่อเสียงโดย Winston Churchill (วิทยุคงที่เป็นคุณสมบัติไม่ใช่ข้อผิดพลาด;) - มันเป็นส่วนหนึ่งของการบันทึกอ้างอิง):
คุณสามารถทดสอบสิ่งเหล่านี้ทั้งหมดบน colab (เราปรับปรุงการพึ่งพาดังนั้นตอนนี้มันใช้เวลาน้อยกว่า 30 วินาทีในการติดตั้ง) พื้นที่ HuggingFace กำลังจะมาเร็ว ๆ นี้
เราได้ผลักดันรุ่น SD S2A ใหม่ที่เร็วกว่ามากในขณะที่ยังคงสร้างคำพูดที่มีคุณภาพสูง นอกจากนี้เรายังได้เพิ่มตัวอย่างของการโคลนเสียงตามไฟล์เสียงอ้างอิง
เช่นเคยคุณสามารถตรวจสอบ colab ของเราเพื่อลองด้วยตัวเอง!
อีกสามรุ่นของรุ่นนี้พวกเขาสนับสนุนหลายภาษา (ภาษาอังกฤษและภาษาโปแลนด์) นี่คือตัวอย่างใหม่สองตัวอย่างสำหรับแอบดู คุณสามารถตรวจสอบ colab ของเราเพื่อลองด้วยตัวเอง!
คำพูดภาษาอังกฤษเสียงหญิง (ถ่ายโอนจากชุดข้อมูลภาษาโปแลนด์):
ตัวอย่างภาษาโปแลนด์เสียงชาย:
การอัปเดตความคืบหน้าเก่ามีการเก็บถาวรที่นี่
เราขอแนะนำให้คุณเริ่มต้นด้วยลิงค์ Google Colab ด้านบนหรือเรียกใช้สมุดบันทึกที่ให้ไว้ในเครื่อง หากคุณต้องการดาวน์โหลดด้วยตนเองหรือฝึกอบรมโมเดลตั้งแต่เริ่มต้นจากนั้นทั้งรุ่น Whisperspeech ที่ผ่านการฝึกอบรมมาแล้วรวมถึงชุดข้อมูลที่แปลงแล้วมีให้ใน HuggingFace
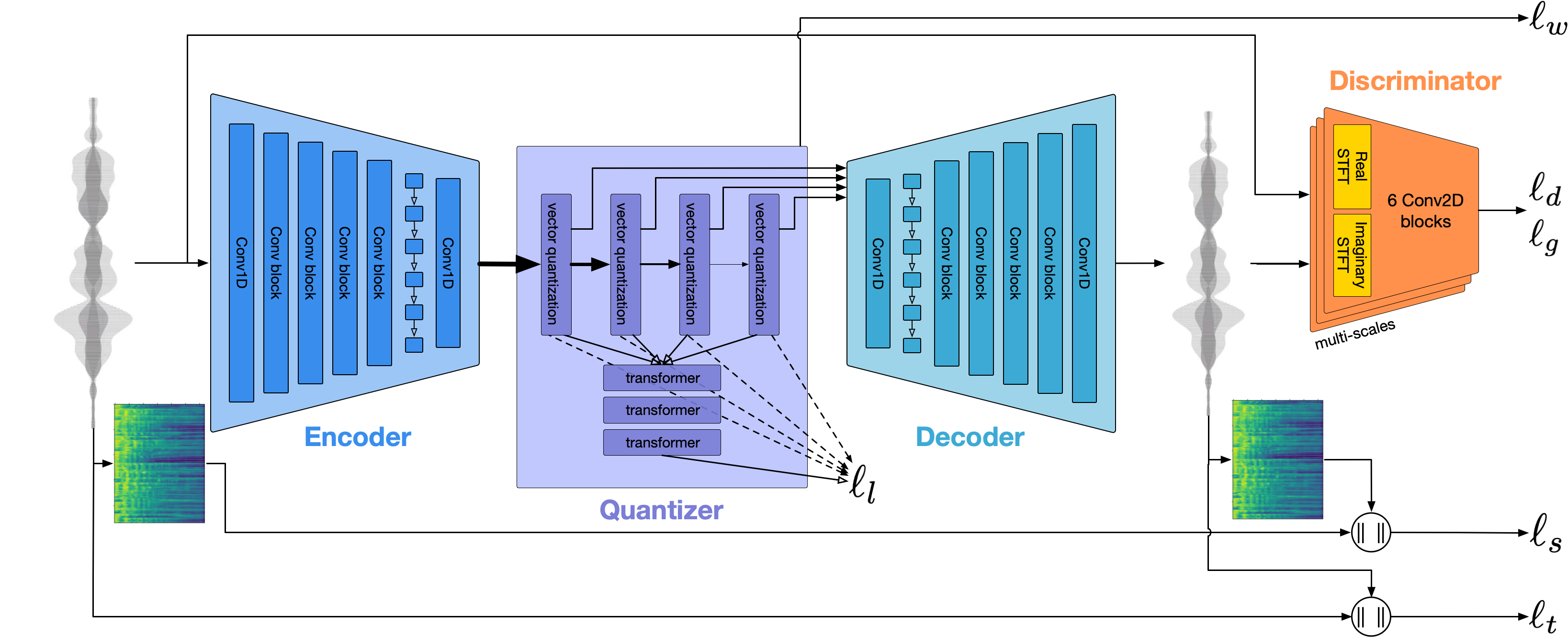
สถาปัตยกรรมทั่วไปคล้ายกับ Audiolm หอก TTs จาก Google และ Musicgen จาก Meta เราหลีกเลี่ยงกลุ่มอาการของ NIH และสร้างขึ้นบนรุ่นโอเพนซอร์สที่ทรงพลัง: กระซิบจาก OpenAI เพื่อสร้างโทเค็นความหมายและทำการถอดความ, encodec จาก Meta สำหรับการสร้างแบบจำลองอะคูสติกและ VOCOS จาก Charactr Inc ในฐานะนักร้องคุณภาพสูง
เราให้การนำเสนอสองครั้งดำน้ำลึกลงไปในเสียงกระซิบ คนแรกพูดถึงความท้าทายของการฝึกอบรมขนาดใหญ่:
เทคนิคที่เรียนรู้จากการปรับขนาดโมเดล Whisperspeech เป็น 80K+ ชั่วโมงของการพูด - การบันทึกวิดีโอโดย Jakub Cłapa, Collabora
อีกอันหนึ่งไปอีกเล็กน้อยในการเลือกสถาปัตยกรรมที่เราทำ:
โครงการโอเพ่นซอร์สข้อความเป็นคำพูด: Whisperspeech-ในการสนทนาเชิงลึก
เราใช้บล็อก Openai Whisper Encoder เพื่อสร้าง embeddings ซึ่งเราจะหาปริมาณเพื่อรับโทเค็นความหมาย
หากภาษาได้รับการสนับสนุนโดย Whisper แล้วกระบวนการนี้ต้องใช้ไฟล์เสียงเท่านั้น (โดยไม่มีการถอดความความจริงภาคพื้นดิน)
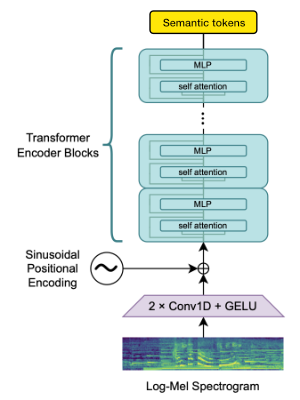
เราใช้ encodec เพื่อจำลองรูปคลื่นเสียง ออกมาจากกล่องให้คุณภาพที่สมเหตุสมผลที่ 1.5kbps และเราสามารถนำสิ่งนี้ไปสู่คุณภาพสูงโดยใช้ Vocos-Vocoder pretrained บนโทเค็น encodec


งานนี้จะเป็นไปไม่ได้หากไม่มีการสนับสนุนจาก:
เราขอขอบคุณศูนย์เกาส์สำหรับซูเปอร์คอมพิวเตอร์ EV (www.gauss-centre.eu) สำหรับการระดมทุนเป็นส่วนหนึ่งของงานนี้โดยการให้เวลาในการคำนวณผ่านสถาบัน John Von Neumann สำหรับการคำนวณ (NIC) ใน GCS Supercomputer
เราขอขอบคุณผู้มีส่วนร่วมแต่ละคนสำหรับความช่วยเหลือที่ยอดเยี่ยมในการสร้างรุ่นนี้:
qwerty_qwer on discord) สำหรับการดูแลชุดข้อมูล เราพร้อมที่จะช่วยเหลือคุณทั้งโครงการโอเพ่นซอร์สและโครงการ AI ที่เป็นกรรมสิทธิ์ คุณสามารถติดต่อเราผ่านเว็บไซต์ Collabora หรือบน Discord (และ)
เราพึ่งพาโครงการโอเพ่นซอร์สที่น่าตื่นตาตื่นใจและงานวิจัย:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

