WhisperSpeech
1.0.0
Si tiene preguntas o desea ayudar, puede encontrarnos en el canal de generación de audio #en el servidor Laion Discord.
Un sistema de texto a voz de código abierto construido por Whisper invertir. Anteriormente conocido como Spear-TTS-Pytorch .
Queremos que este modelo sea como una difusión estable pero para el habla, tanto poderoso como fácilmente personalizable.
Estamos trabajando solo con grabaciones de habla correctamente con licencia y todo el código es de código abierto, por lo que el modelo siempre será seguro de usar para aplicaciones comerciales.
Actualmente, los modelos están capacitados en el conjunto de datos en inglés Librelight. En el próximo lanzamiento queremos dirigirnos varios idiomas (Whisper y Encodec son multilenguajos).
Muestra de la voz sintetizada:
Entrenamos con éxito un tiny modelo S2A en un conjunto de datos EN+PL+FR y puede hacer una clonación de voz en francés:
Pudimos hacer esto con tokens semánticos congelados que solo estaban entrenados en inglés y polaco. Esto respalda la idea de que podremos capacitar a un solo modelo de token semántico para apoyar todos los idiomas del mundo. Es muy probable que incluso los que actualmente no están bien respaldados por el modelo Whisper. Estén atentos para obtener más actualizaciones en este frente. :)
Pasamos la última semana optimizando el rendimiento de la inferencia. Integramos torch.compile , agregamos el almacenamiento en caché de KV y sintonizamos algunas de las capas, ¡ahora estamos trabajando más de 12 veces más rápido que en tiempo real en un consumidor 4090!
Podemos mezclar idiomas en una sola oración (aquí los nombres de los proyectos de inglés resaltados se mezclan sin problemas en el habla polaca):
Test Pierwszy Test Wielojęzycznego
Whisper SpeechModelu ZamieniaJąCEGO Tekst na Mowę, KtóryCollaboraILaionNauczyli Na SuperkomputerzeJewels.
También agregamos una manera fácil de probar la clonación de voz. Aquí hay una voz de muestra clonada de un famoso discurso de Winston Churchill (la radio estática es una característica, no un error;) - Es parte de la grabación de referencia):
Puede probar todo esto en Colab (optimizamos las dependencias, por lo que ahora tarda menos de 30 segundos en instalarse). Pronto llegará un espacio para la cara de abrazo.
Hemos presionado un nuevo modelo SD S2A que es mucho más rápido mientras genera un discurso de alta calidad. También hemos agregado un ejemplo de clonación de voz basado en un archivo de audio de referencia.
Como siempre, ¡puedes ver nuestro Colab para probarlo tú mismo!
Otro trío de modelos, esta vez admiten múltiples idiomas (inglés y polaco). Aquí hay dos nuevas muestras para un vistazo. ¡Puedes ver nuestro colab para probarlo tú mismo!
Discurso inglés, voz femenina (transferida de un conjunto de datos de idioma polaco):
Una muestra polaca, voz masculina:
Las actualizaciones de progreso más antiguas se archivan aquí
Le recomendamos que comience con el enlace de Google Colab arriba o ejecute el cuaderno proporcionado localmente. Si desea descargar manualmente o entrenar a los modelos desde cero, tanto los modelos pre-capacitados WhispersPeech, así como los conjuntos de datos convertidos, están disponibles en Huggingface.
La arquitectura general es similar a Audiolm, Spear TTS de Google y MusicGen de Meta. Evitamos el síndrome de NIH y lo construimos en la parte superior de los potentes modelos de código abierto: Whisper de OpenAi para generar tokens semánticos y realizar transcripción, codec de meta para modelado acústico y vocos de Charactr Inc como el vocoder de alta calidad.
Dimos dos presentaciones que se sumergieron más profundamente en el conjunto de susurros. El primero habla sobre los desafíos del entrenamiento a gran escala:
Trucos aprendidos al escalar modelos de tiempo de susurros a 80k+ horas de discurso - grabación de video por Jakub Cłapa, Collabora
El otro va un poco más a las elecciones arquitectónicas que hicimos:
Proyectos de texto a voz de código abierto: WhispersPeech-Discusión en profundidad
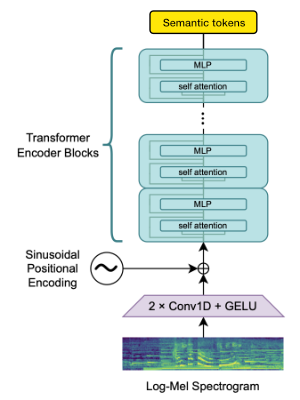
Utilizamos el bloque de codificadores Operai Whisper para generar integridades que luego cuantificamos para obtener tokens semánticos.
Si el lenguaje ya es compatible con Whisper, entonces este proceso requiere solo archivos de audio (sin transcripciones de verdad de tierra).
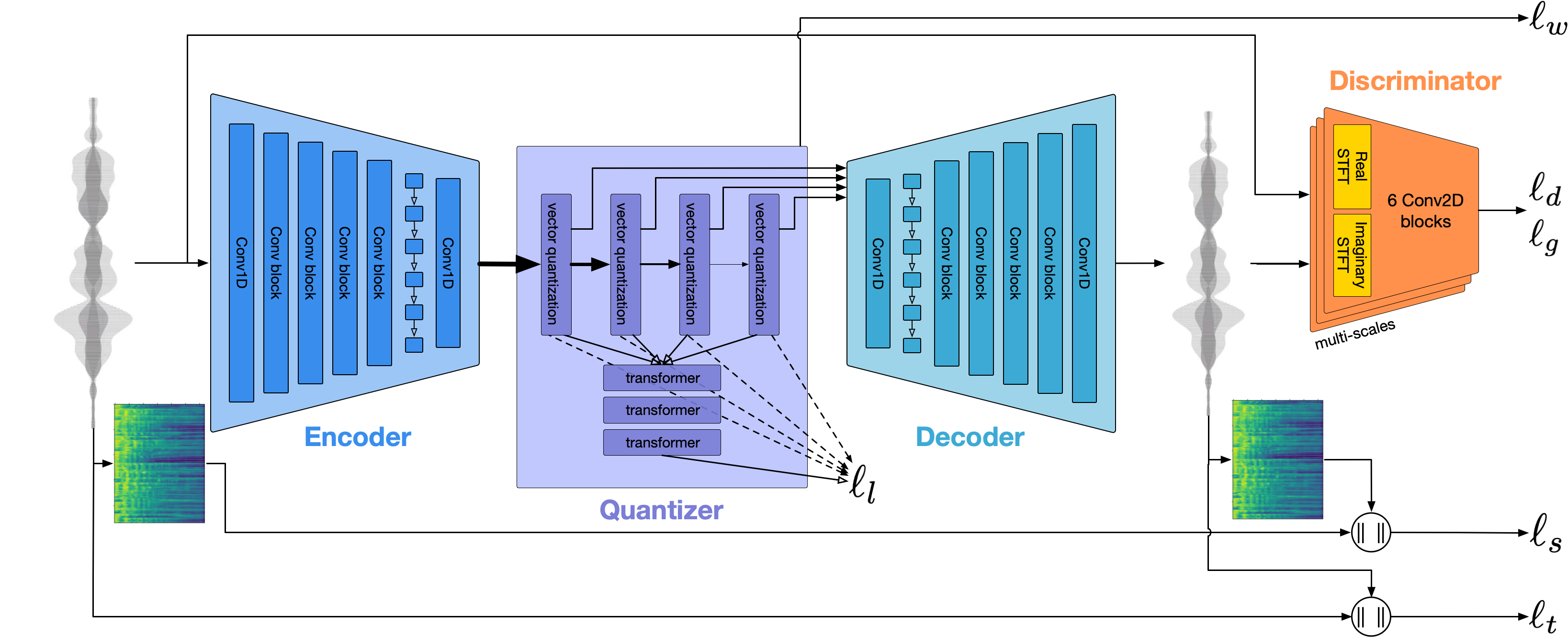
Utilizamos Codec para modelar la forma de onda de audio. Fuera de la caja ofrece una calidad razonable a 1.5 kbps y podemos llevar esto a alta calidad mediante el uso de VOCOS, un vocoder previamente en los tokens Encodec.


Este trabajo no sería posible sin los generosos patrocinios de:
Agradecemos al Centro Gauss para la Supercomputación EV (www.gauss-centre.eu) por financiar parte de este trabajo proporcionando tiempo de computación a través del Instituto John Von Neumann para la Computación (NIC) en la supercomputadora GCS Juwels Booster en Jülich SuperComputing Center (JSC), con acceso a la computa proporcionada a través de la cooperación de Laion en la investigación de modelos de cimientos.
También nos gustaría agradecer a los contribuyentes individuales por su gran ayuda para construir este modelo:
qwerty_qwer EN DISCORD) para la curación del conjunto de datos Estamos disponibles para ayudarlo tanto con los proyectos de AI y de código abierto. Puede comunicarse con nosotros a través del sitio web de Collabora o en Discord (y)
Confiamos en muchos increíbles proyectos de código abierto y trabajos de investigación:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

