WhisperSpeech
1.0.0
Si vous avez des questions ou si vous souhaitez vous aider, vous pouvez nous trouver dans le canal de génération audio # sur le serveur LAION Discord.
Un système de texte vocal open source construit par un chuchotement inversé. Auparavant connu sous le nom de Spear-Tts-Pytorch .
Nous voulons que ce modèle soit comme une diffusion stable mais pour la parole - à la fois puissant et facilement personnalisable.
Nous travaillons uniquement avec des enregistrements vocaux correctement agréés et tout le code est open source, donc le modèle sera toujours sûr à utiliser pour les applications commerciales.
Actuellement, les modèles sont formés sur l'ensemble de données anglaise Librelight. Dans la version suivante, nous voulons cibler plusieurs langues (Whisper et Encodec sont tous deux multiples).
Échantillon de la voix synthétisée:
Nous avons réussi à former un tiny modèle S2A sur un ensemble de données EN + PL + FR et il peut faire du clonage vocal en français:
Nous avons pu le faire avec des jetons sémantiques congelés qui n'étaient formés que sur l'anglais et le poli. Cela soutient l'idée que nous serons en mesure de former un seul modèle de jeton sémantique pour soutenir toutes les langues du monde. Très probablement même ceux qui ne sont pas actuellement bien soutenus par le modèle Whisper. Restez à l'écoute pour plus de mises à jour sur ce front. :)
Nous passons la dernière semaine à optimiser les performances d'inférence. Nous avons intégré torch.compile , ajouté KV-Caching et réglé certaines des couches - nous travaillons maintenant plus de 12x plus vite que le temps réel sur un consommateur 4090!
Nous pouvons mélanger les langues en une seule phrase (ici les noms de projet en anglais mis en évidence sont mélangés parfaitement dans le discours polonais):
Pour plaisanter Pierwszy Test Wielojęzycznego
Whisper SpeechModelu Zamieniającego Tekst Na Mowę, KtóryCollaboraILaionNauczyli na SuperkomputerzeJewels.
Nous avons également ajouté un moyen facile de tester la clonage vocale. Voici un échantillon de voix cloné à partir d'un discours célèbre de Winston Churchill (la radio statique est une fonctionnalité, pas un bug;) - il fait partie de l'enregistrement de référence):
Vous pouvez tester tous ces éléments sur Colab (nous avons optimisé les dépendances, il faut donc maintenant moins de 30 secondes pour installer). Un espace étreint arrive bientôt.
Nous avons poussé un nouveau modèle SD S2A qui est beaucoup plus rapide tout en générant des discours de haute qualité. Nous avons également ajouté un exemple de clonage vocal basé sur un fichier audio de référence.
Comme toujours, vous pouvez consulter notre colab pour l'essayer vous-même!
Un autre trio de modèles, cette fois, ils prennent en charge plusieurs langues (anglais et polonais). Voici deux nouveaux échantillons pour un aperçu. Vous pouvez consulter notre colab pour l'essayer vous-même!
Discours anglais, voix féminine (transférée d'un ensemble de données de langue polonaise):
Un échantillon polonais, voix masculine:
Les plus anciennes mises à jour de progrès sont archivées ici
Nous vous encourageons à commencer par le lien Google Colab ci-dessus ou à exécuter le cahier fourni localement. Si vous souhaitez télécharger manuellement ou former les modèles à partir de zéro, les modèles Whisperspeech pré-formés ainsi que les ensembles de données convertis sont disponibles sur HuggingFace.
L'architecture générale est similaire à Audiolm, Spear TTS de Google et Musicgen de Meta. Nous avons évité le syndrome du NIH et l'avons construit au-dessus de puissants modèles open source: chuchoter d'OpenAI pour générer des jetons sémantiques et effectuer la transcription, encodéc à partir de Meta pour la modélisation acoustique et VOCOS de Charactr Inc en tant que vocodeur de haute qualité.
Nous avons donné deux présentations en plongeant plus profondément dans Whisperspeech. Le premier parle des défis de la formation à grande échelle:
Tricks appris de l'échelle des modèles Whisperspeech à 80k + heures de discours - Enregistrement vidéo de Jakub Cłapa, Collabora
L'autre va un peu plus dans les choix architecturaux que nous avons faits:
Projets de texte vocale open source: Whisperspeech - Discussion en profondeur
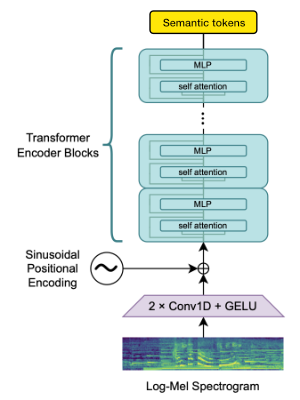
Nous utilisons le bloc Openai Whisper Encodeur pour générer des intérêts que nous quantifions ensuite pour obtenir des jetons sémantiques.
Si la langue est déjà prise en charge par Whisper, ce processus ne nécessite que des fichiers audio (sans transcriptions de vérité au sol).
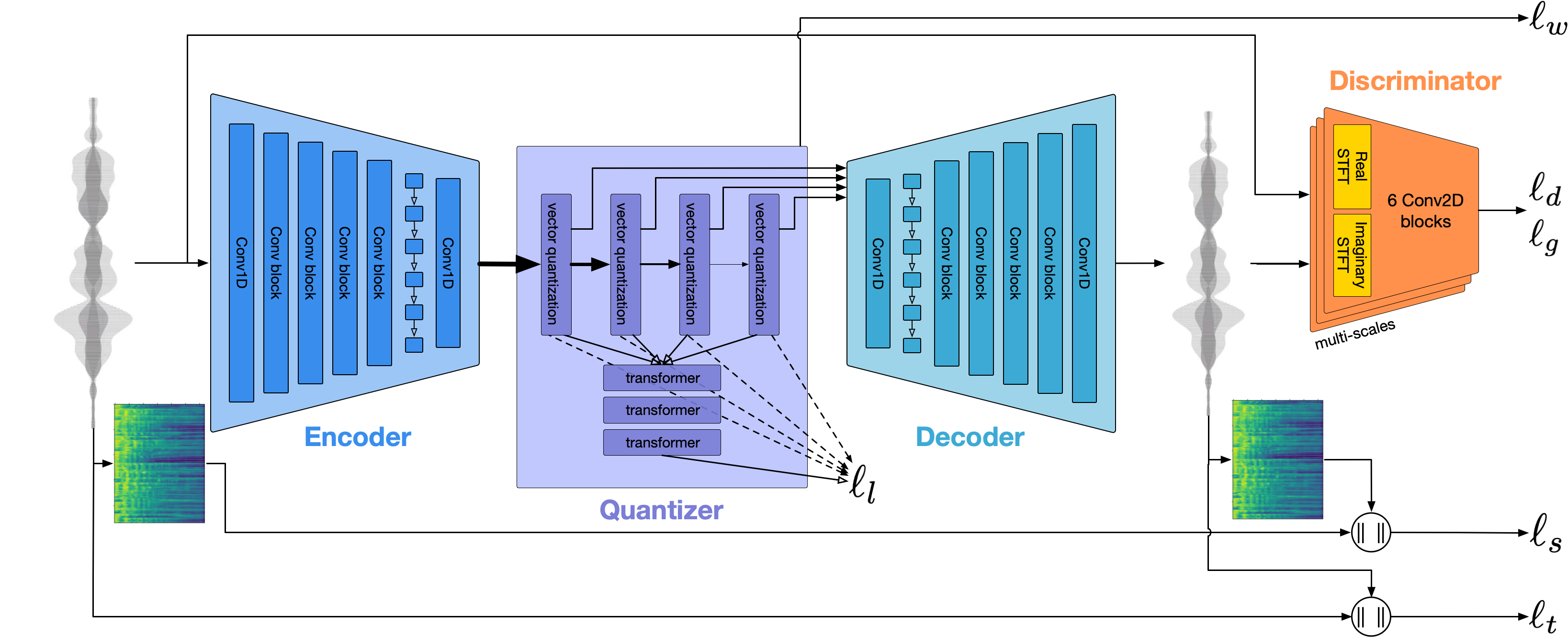
Nous utilisons Encodec pour modéliser la forme d'onde audio. Hors de la boîte, il offre une qualité raisonnable à 1,5 kbps et nous pouvons le porter à une qualité de haute qualité en utilisant VOCOS - un vocodeur pré-entraîné sur les jetons encodec.


Ce travail ne serait pas possible sans les généreux parrainages de:
Nous remercions le Gauss Center for Supercomputing EV (www.gauss-centre.eu) pour le financement d'une partie de ce travail en fournissant un temps informatique via le John Von Neumann Institute for Computing (NIC) sur le GCS Supercomputeur Juwels Booster au Jülich Supercompost Center (JSC), avec un accident pour compléter via le coopération LION sur les modèles de fondations.
Nous tenons également à remercier les contributeurs individuels pour leur grande aide pour construire ce modèle:
qwerty_qwer sur discorde) pour la conservation de l'ensemble de données Nous sommes disponibles pour vous aider avec les projets d'origine open source et propriétaires. Vous pouvez nous joindre via le site Web de Collabora ou sur Discord (et)
Nous comptons sur de nombreux projets open source et articles de recherche incroyables:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

