WhisperSpeech
1.0.0
Если у вас есть вопросы или вы хотите помочь, вы можете найти нас в канале #аудиопогенерации на сервере Discord Laion.
Система с открытым исходным кодом текста в речь, построенная путем инвертирования шепота. Ранее известный как Spear-TTS-Pytorch .
Мы хотим, чтобы эта модель была похожа на стабильную диффузию, но для речи - как мощной, так и легко настраиваемой.
Мы работаем только с правильно лицензированными речевыми записями, и весь код является открытым исходным кодом, поэтому модель всегда будет безопасна для использования для коммерческих приложений.
В настоящее время модели обучаются на наборе данных английского LibreLight. В следующем выпуске мы хотим нацеливаться на несколько языков (Whisper и Encodec являются многолучеванием).
Образец синтезированного голоса:
Мы успешно обучили tiny модель S2A на наборе данных EN+PL+FR, и она может выполнять голосовой клонирование на французском языке:
Мы смогли сделать это с замороженными семантическими токенами, которые были обучены только на английском и лаке. Это поддерживает идею о том, что мы сможем обучить одну модель семантического токена для поддержки всех языков в мире. Вполне вероятно, что даже те, которые в настоящее время не поддерживаются моделью Whisper. Следите за обновлениями на этом фронте. :)
Мы проводим последнюю неделю оптимизируя производительность вывода. Мы интегрировали torch.compile , добавили KV-кэширование и настроили некоторые слои-теперь мы работаем в 12 раз быстрее, чем в режиме реального времени на потребителе 4090!
Мы можем смешивать языки в одном предложении (здесь выделенные английские имена проектов плавно смешаны с польской речью):
Чтобы Jest Pierwszy Test Wielojęzycznego
Whisper SpeechModelu Zamieniającego tekst na mowę, KtóryCollaboraiLaionnauczyli na superkomputerzeJewels.
Мы также добавили простой способ протестировать голосовой клонинг. Вот образец голоса, клонированный из известной речи Уинстона Черчилля (радиосвязь - это особенность, а не ошибка;) - это часть справочной записи):
Вы можете проверить все это на Colab (мы оптимизировали зависимости, поэтому теперь для установки требуется менее 30 секунд). Скоро наступит пространство для объятий.
Мы подтолкнули новую модель SD S2A, которая намного быстрее, при этом генерируя высококачественную речь. Мы также добавили пример голосового клонирования на основе эталонного аудиофайла.
Как всегда, вы можете проверить нашу колаба, чтобы попробовать сами!
Еще одно трио моделей, на этот раз они поддерживают несколько языков (английский и польский). Вот два новых образца для подглядывания. Вы можете проверить нашу колаба, чтобы попробовать сами!
Английская речь, женский голос (перенесен из набора данных польского языка):
Польский образец, мужской голос:
Здесь архивируют более старые обновления прогресса
Мы рекомендуем вам начать со ссылки Google Colab выше или запустить предоставленную ноутбук на локальном уровне. Если вы хотите загрузить вручную или тренировать модели с нуля, то как Whisperspeech, предварительно обученные модели, так и конвертированные наборы данных, доступны на Huggingface.
Общая архитектура аналогична Audiolm, Spear TTS от Google и MusicGen от Meta. Мы избежали синдрома NIH и построили его поверх мощных моделей с открытым исходным кодом: Whisper от Openai, чтобы генерировать семантические токены и выполнить транскрипцию, incodec от Meta для акустического моделирования и Vocos от Parmantr Inc в качестве высококачественного вокала.
Мы дали две презентации погружение глубже в Whisperspeech. Первый рассказывает о проблемах крупномасштабного обучения:
Трюки, изученные из масштабирования моделей Whisperspeech до 80K+ часов речи - видеозапись Jakub Cłapa, Collabora
Другой все больше входит в архитектурный выбор, который мы сделали:
Проекты с открытым исходным кодом
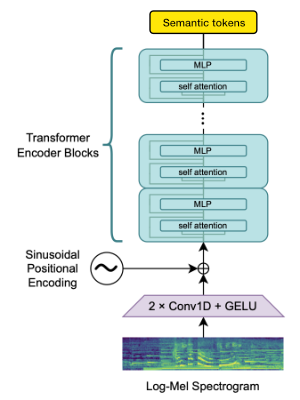
Мы используем блок энкодера Openai для генерации встраиваний, которые мы затем определяем, чтобы получить семантические жетоны.
Если язык уже поддерживается Whisper, то этот процесс требует только аудиофайлов (без основных транскрипций истины).
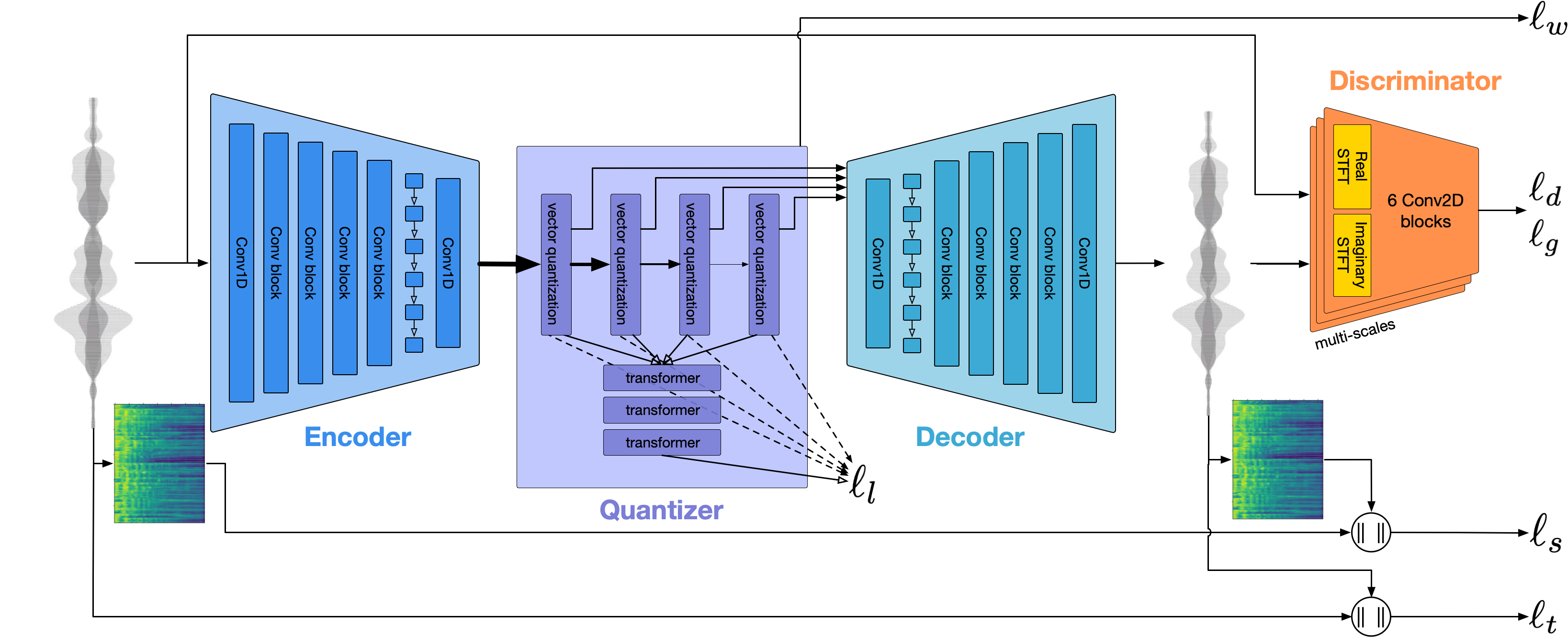
Мы используем Encodec для моделирования формы волны аудио. Из коробки он обеспечивает разумное качество со скоростью 1,5 кбит / с, и мы можем довести это до качества, используя Vocos-Vocoder, предварительно проведенный на токенах Encodec.


Эта работа была бы невозможна без щедрого спонсорства от:
Мы благодарны за то, что Центр суперкомпьютинг EV (www.gauss-sentre.eu) Центр по суперкомпьютинге (www.gauss-gent.eu), предоставляя вычислительное время через Институт вычислительных наук Джона фон Неймана (NIC) на суперкомпьютере GCS Juwels Booster в Jülich Supercomputing Center (JSC), с доступом к компоненту, предоставленному с помощью Comoperection Laion Cooperection на модели основы.
Мы также хотели бы поблагодарить отдельных участников за большую помощь в создании этой модели:
qwerty_qwer ON DISCORD) для курирования наборов данных Мы готовы помочь вам с открытым исходным кодом и проприетарными проектами искусственного интеллекта. Вы можете связаться с нами через веб -сайт Collabora или на Discord (и)
Мы полагаемся на многие удивительные проекты с открытым исходным кодом и исследовательские работы:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

