WhisperSpeech
1.0.0
Se você tiver dúvidas ou quiser ajudar, pode nos encontrar no canal de geração de áudio #no servidor Laion Discord.
Um sistema de texto para fala em código aberto criado invertendo o Whisper. Anteriormente conhecido como spear-tts-pytorch .
Queremos que esse modelo seja como difusão estável, mas para a fala - poderosa e facilmente personalizável.
Estamos trabalhando apenas com gravações de fala devidamente licenciadas e todo o código é de código aberto, para que o modelo seja sempre seguro de usar para aplicações comerciais.
Atualmente, os modelos são treinados no conjunto de dados da LibreLight ingles. No próximo lançamento, queremos atingir vários idiomas (Whisper e Codec são ambos multilanguage).
Amostra da voz sintetizada:
Treminamos com sucesso um tiny modelo S2A em um conjunto de dados PL+PL+FR e ele pode fazer clonagem de voz em francês:
Conseguimos fazer isso com tokens semânticos congelados que só foram treinados em inglês e polimento. Isso apóia a ideia de que poderemos treinar um único modelo de token semântico para apoiar todos os idiomas do mundo. Provavelmente, mesmo os que atualmente não são bem suportados pelo modelo Whisper. Fique atento para mais atualizações nesta frente. :)
Passamos a última semana otimizando o desempenho da inferência. Integramos torch.compile , adicionamos KV-Caching e sintonizamos algumas das camadas-agora estamos trabalhando mais de 12x mais rápido que em tempo real em um consumidor 4090!
Podemos misturar idiomas em uma única frase (aqui os nomes de projetos em inglês destacados são perfeitamente misturados no discurso polonês):
Para o idiota Pierwszy Wielojęzycznego
Whisper SpeechModelu zamieniającego tekst na mowę, któryCollaboraiLaionnauczyli na superkomputerzeJewels.
Também adicionamos uma maneira fácil de testar a clonagem de voz. Aqui está uma amostra de voz clonada de um discurso famoso de Winston Churchill (o rádio estático é um recurso, não um bug;) - faz parte da gravação de referência):
Você pode testar tudo isso no COLAB (otimizamos as dependências, então agora leva menos de 30 segundos para instalar). Um espaço de abraço está chegando em breve.
Empurramos um novo modelo SD S2A que é muito mais rápido, enquanto ainda gera discursos de alta qualidade. Também adicionamos um exemplo de clonagem de voz com base em um arquivo de áudio de referência.
Como sempre, você pode conferir nosso colab para experimentar você mesmo!
Outro trio de modelos, desta vez eles suportam vários idiomas (inglês e polimento). Aqui estão duas novas amostras para uma prévia. Você pode conferir nosso colab para experimentar você mesmo!
Discurso em inglês, voz feminina (transferida de um conjunto de dados de idioma polonês):
Uma amostra polonesa, voz masculina:
As atualizações de progresso mais antigas estão arquivadas aqui
Incentivamos você a começar com o link do Google Colab acima ou executar o notebook fornecido localmente. Se você deseja baixar manualmente ou treinar os modelos do zero, os modelos pré-treinados com Whisperspeech e os conjuntos de dados convertidos estarão disponíveis no HuggingFace.
A arquitetura geral é semelhante ao Audiolm, Spear TTS do Google e MusicGen da Meta. Evitamos a síndrome do NIH e a construímos em cima de poderosos modelos de código aberto: sussurrar do OpenAi para gerar tokens semânticos e realizar transcrição, codec de meta para modelagem acústica e vocos da Charactr Inc como vocoder de alta qualidade.
Demos duas apresentações aprofundadas no Whisperspeech. O primeiro fala sobre os desafios do treinamento em larga escala:
Truques aprendidos com modelos de Whisperspeech de escala até 80k+ horas de fala - gravação de vídeo por Jakub Cłapa, Collabora
O outro vai um pouco mais nas escolhas arquitetônicas que fizemos:
Projetos de texto para fala em código aberto: Whisperspeech-Discussão em profundidade
Utilizamos o bloco de codificadores Whisper Openai para gerar incorporações que quantizamos para obter tokens semânticos.
Se o idioma já for suportado pelo Whisper, esse processo exigir apenas arquivos de áudio (sem transcrições de verdade).
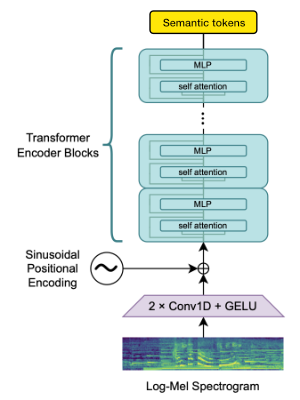
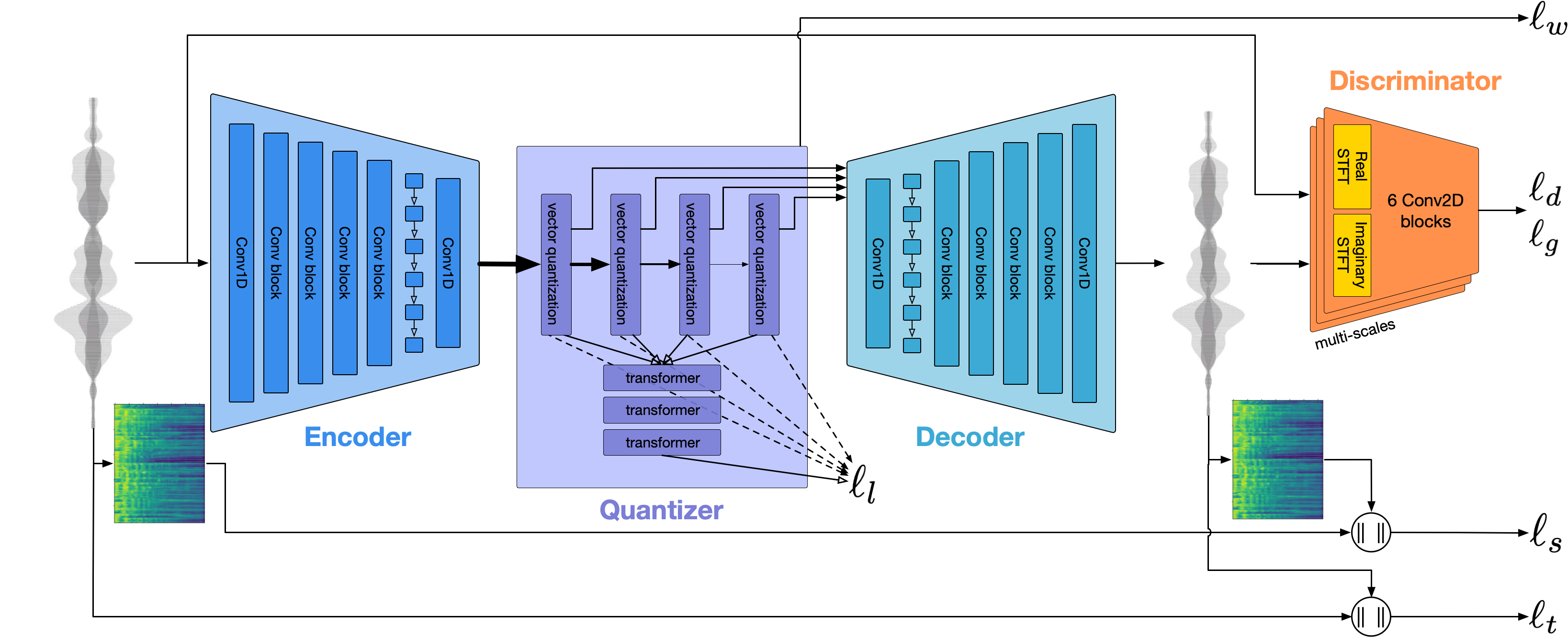
Usamos o Encodec para modelar a forma de onda de áudio. Fora da caixa, oferece qualidade razoável a 1,5kbps e podemos levar isso à alta qualidade usando o VOCOS-um vocoder pré-levado em tokens do Encodec.


Este trabalho não seria possível sem os generosos patrocínios de:
Agradecemos o Gauss Center for Supercomputing EV (www.gauss-centre.eu) por financiar parte deste trabalho, fornecendo tempo de computação através do Instituto de Computação de John von Neumann para computação (NIC) no GCS Supercomputer Oferece, por meio de computadores, o Modelatomputing da Jülich em computação.
Gostaríamos de agradecer também a colaboradores individuais por sua grande ajuda na construção deste modelo:
qwerty_qwer na discórdia) para curadoria de dados Estamos disponíveis para ajudá -lo com projetos de IA de código aberto e proprietários. Você pode entrar em contato conosco no site da Collabora ou na discórdia (e)
Contamos com muitos projetos incríveis de código aberto e trabalhos de pesquisa:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

