WhisperSpeech
1.0.0
إذا كانت لديك أسئلة أو تريد مساعدتك في العثور علينا في قناة #Audio Generation على خادم Discord Laion.
نظام نص إلى كلام مفتوح المصدر مصمم عن طريق تقلب الهمس. المعروف سابقا باسم سبير tts-pytorch .
نريد أن يكون هذا النموذج مثل الانتشار المستقر ولكن بالنسبة للكلام - على حد سواء قوي وقابل للتخصيص بسهولة.
نحن نعمل فقط مع تسجيلات الكلام المرخصة بشكل صحيح وجميع الكود مفتوح المصدر ، وبالتالي فإن النموذج سيكون آمنًا دائمًا للاستخدام للتطبيقات التجارية.
يتم تدريب النماذج حاليًا على مجموعة بيانات Librelight الإنجليزية. في الإصدار التالي ، نريد أن نستهدف لغات متعددة (همسة و encodec كلاهما متعدد اللغات).
عينة من الصوت المركب:
لقد قمنا بتدريب نموذج S2A tiny على مجموعة بيانات EN+PL+FR ويمكنه القيام بالاستنساخ الصوتي باللغة الفرنسية:
كنا قادرين على القيام بذلك مع الرموز الدلالية المجمدة التي تم تدريبها فقط على اللغة الإنجليزية والبولندية. هذا يدعم فكرة أننا سنكون قادرين على تدريب نموذج رمزي دلالي واحد لدعم جميع اللغات في العالم. من المحتمل جدًا حتى تلك التي لا تدعمها حاليًا نموذج Whisper. ترقبوا المزيد من التحديثات على هذه الجبهة. سائدا
نقضي الأسبوع الماضي في تحسين أداء الاستدلال. قمنا بدمج torch.compile ، وأضفنا التثبيت KV وضبطنا بعض الطبقات-نعمل الآن أكثر من 12x بشكل أسرع من الوقت الفعلي على مستهلك 4090!
يمكننا مزج اللغات في جملة واحدة (هنا يتم خلط أسماء المشروع باللغة الإنجليزية المميزة بسلاسة في الكلام البولندي):
إلى Jest Pierwszy Test Wielojęzycznego
Whisper SpeechModelu Zamieniajągo Tekst Na Mowę ، KtóryCollaboraILaionnauczyli na superkomputerzeJewels.
لقد أضفنا أيضًا طريقة سهلة لاختبار النطاق الصوتي. فيما يلي عينة صوت مستنسخ من خطاب مشهور من قبل وينستون تشرشل (الراديو الثابت هو ميزة ، وليس خطأ ؛) - إنه جزء من التسجيل المرجعي):
يمكنك اختبار كل هذه على كولاب (قمنا بتحسين التبعيات ، لذا يستغرق التثبيت أقل من 30 ثانية). مساحة معانقة ستأتي قريبًا.
لقد دفعنا نموذجًا جديدًا لـ SD S2A أسرع بكثير بينما لا يزال يولد خطابًا عالي الجودة. لقد أضفنا أيضًا مثالًا على الاستنساخ الصوتي بناءً على ملف صوتي مرجعي.
كما هو الحال دائمًا ، يمكنك التحقق من كولاب لدينا لتجربته بنفسك!
الثلاثي آخر من النماذج ، هذه المرة يدعمون لغات متعددة (اللغة الإنجليزية والبولندية). فيما يلي عينتان جديدتان لإلقاء نظرة خاطفة على التسلل. يمكنك التحقق من كولاب لدينا لتجربته بنفسك!
خطاب اللغة الإنجليزية ، صوت أنثى (تم نقله من مجموعة بيانات اللغة البولندية):
عينة تلميع ، صوت ذكر:
تحديثات التقدم الأقدم يتم أرشفة هنا
نحن نشجعك على البدء برابط Google Colab أعلاه أو تشغيل دفتر الملاحظات المقدم محليًا. إذا كنت ترغب في تنزيل النماذج يدويًا أو تدريب النماذج من نقطة الصفر ، فستتوفر كل من النماذج التي تم تدريبها مسبقًا وكذلك مجموعات البيانات المحولة على Luggingface.
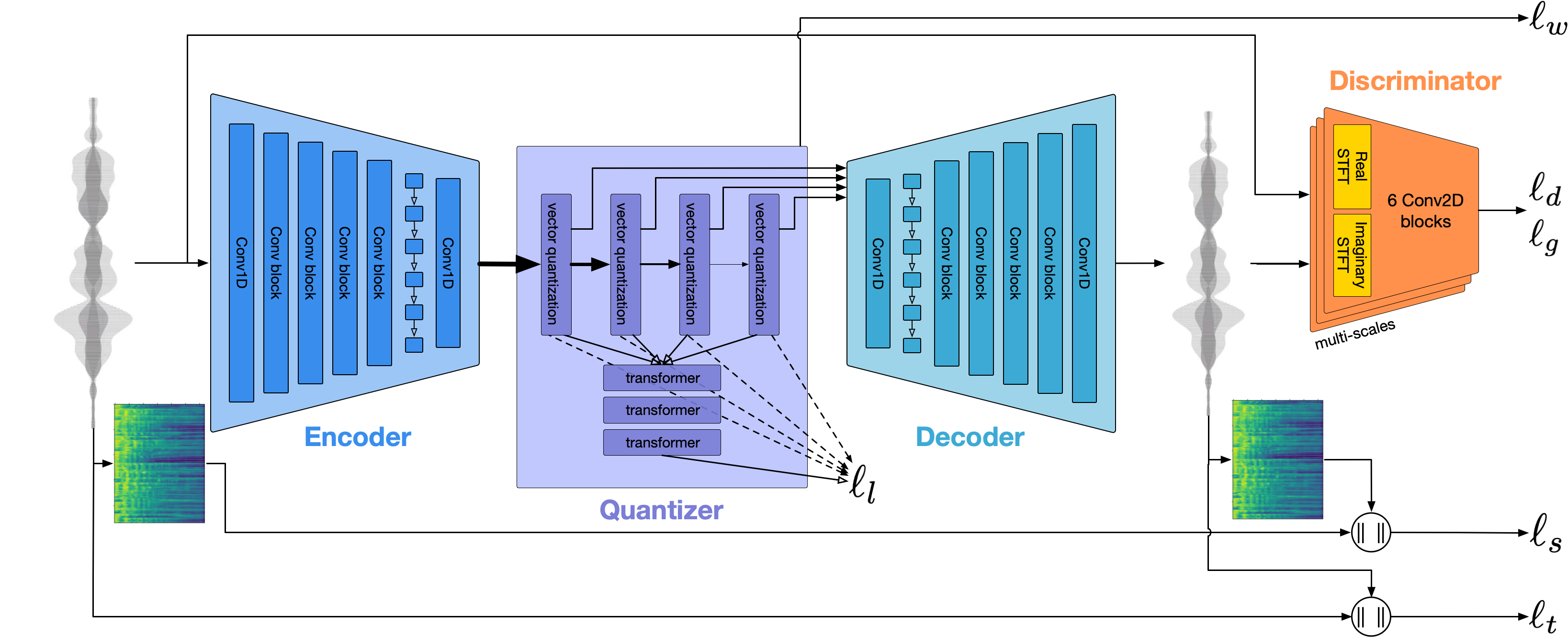
تشبه الهندسة المعمارية العامة Audiolm و Spear TTS من Google و MusicGen من Meta. لقد تجنبنا متلازمة المعاهد الوطنية للصحة وقمنا ببناءها فوق نماذج مصدر مفتوحة قوية: تهمس من Openai لتوليد الرموز الدلالية وأداء النسخ ، وترميز من META للنمذجة الصوتية و Vocos من Charactr Inc باعتبارها الموجود عالي الجودة.
قدمنا عرضين تقديميين أعمق في الإرهاق. يتحدث أول واحد عن تحديات التدريب على نطاق واسع:
تعلمت الحيل من تحجيم نماذج الإرهاق إلى 80K+ ساعة من الكلام - تسجيل الفيديو بواسطة Jakub Cłapa ، Collabora
الآخر يذهب أكثر قليلاً في الخيارات المعمارية التي اتخذناها:
مشاريع النص إلى الكلام مفتوح المصدر: whisperspeech-مناقشة متعمقة
نحن نستخدم كتلة تشفير Whisper Openai لتوليد التضمينات التي نقوم بعدها بعد ذلك بتقديمها للحصول على الرموز الدلالية.
إذا كانت اللغة مدعومة بالفعل من قبل Whisper ، فإن هذه العملية لا تتطلب سوى ملفات صوتية (بدون نسخ الحقيقة الأرضية).
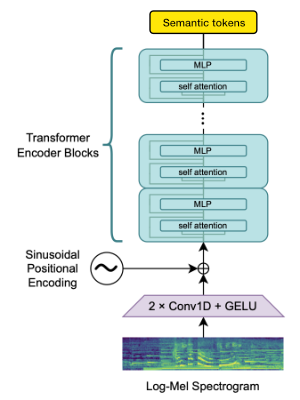
نستخدم Encodec لتصميم شكل الموجة الصوتية. من خارج الصندوق ، يوفر جودة معقولة عند 1.5 كيلو بايت في الثانية ويمكننا أن نجلب هذا إلى جودة عالية باستخدام VOCOs-صوتي مسبق على رموز Encodec.


لن يكون هذا العمل ممكنًا بدون رعاية سخية من:
نعترف بامتنان بمركز Gauss لـ SuperCerging EV (www.gauss-centre.eu) لتمويل جزء من هذا العمل من خلال توفير وقت الحوسبة من خلال مركز John Von Neumann للمعهد (NIC) في مجال الأبحاث GCS Superjuter Juwels Booster في Jülich SuperComputing Center (JSC) ، مع الوصول إلى Compute to Layion On Fooderation.
نود أيضًا أن نشكر المساهمين الأفراد على مساعدتهم الرائعة في بناء هذا النموذج:
qwerty_qwer على Discord) لتركيب مجموعة البيانات نحن متاحون لمساعدتك في كل من مشاريع الذكاء الاصطناعى المصدر والملكية. يمكنك الوصول إلينا عبر موقع Collabora أو على Discord (و)
نعتمد على العديد من المشاريع المذهلة مفتوحة المصدر والأوراق البحثية:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

