WhisperSpeech
1.0.0
Wenn Sie Fragen haben oder Ihnen helfen möchten, können Sie uns auf dem Laion Discord-Server auf dem #Audio-Generation-Kanal finden.
Ein Open-Source-Text-zu-Sprach-System, das von Inverting Whisper erstellt wurde. Früher als Spear-TTS-Pytorch bekannt.
Wir möchten, dass dieses Modell wie eine stabile Diffusion ist, aber für die Sprache - sowohl leistungsstark als auch leicht anpassbar.
Wir arbeiten nur mit ordnungsgemäß lizenzierten Sprachaufzeichnungen und der gesamte Code ist Open Source, sodass das Modell für kommerzielle Anwendungen immer sicher zu verwenden ist.
Derzeit werden die Modelle im englischen Datensatz von Lubinight geschult. In der nächsten Veröffentlichung möchten wir mehrere Sprachen ansprechen (Whisper und Encodec sind beide Multilanguage).
Probe der synthetisierten Stimme:
Wir haben ein tiny S2A -Modell erfolgreich auf einem EN+PL+FR -Datensatz ausgebildet, und es kann das Klonen von Sprachklonen auf Französisch machen:
Wir konnten dies mit gefrorenen semantischen Token tun, die nur auf Englisch und Politur trainiert wurden. Dies unterstützt die Idee, dass wir in der Lage sein werden, ein einziges semantisches Token -Modell zu schulen, um alle Sprachen der Welt zu unterstützen. Sehr wahrscheinlich sogar solche, die vom Whisper -Modell derzeit nicht gut unterstützt werden. Weitere Updates an dieser Front. :)
Wir verbringen die letzte Woche damit, die Inferenzleistung zu optimieren. Wir haben torch.compile integriert, KV-Caching hinzugefügt und einige der Schichten abgestimmt-wir arbeiten jetzt schneller als in Echtzeit bei einem Verbraucher 4090!
Wir können Sprachen in einem einzigen Satz mischen (hier werden die hervorgehobenen englischen Projektnamen nahtlos in die polnische Sprache gemischt):
Zum Scherz Pierwszy Test Wielojęzycznego
Whisper SpeechModelu Zamieniającego tekst na Mowę, KtóryCollaboraiLaionnauczyli na SuperkomputerzeJewels.
Wir haben auch eine einfache Möglichkeit hinzugefügt, das Sprachkloning zu testen. Hier ist eine Beispielstimme, die von einer berühmten Rede von Winston Churchill (The Radio Static ist ein Merkmal, kein Fehler;) - sie ist Teil der Referenzaufzeichnung) geklont: es ist Teil der Referenzaufzeichnung):
Sie können all dies auf Colab testen (wir haben die Abhängigkeiten optimiert, sodass die Installation weniger als 30 Sekunden dauert). In Kürze kommt ein Umarmungsraum.
Wir haben ein neues SD S2A-Modell vorangetrieben, das viel schneller ist und gleichzeitig eine hochwertige Sprache erzeugt. Wir haben auch ein Beispiel für das Sprachklonen auf der Grundlage einer Referenz -Audio -Datei hinzugefügt.
Wie immer können Sie unser Colab überprüfen, um es selbst zu probieren!
Ein weiteres Trio von Models, diesmal, unterstützen sie mehrere Sprachen (Englisch und Politur). Hier sind zwei neue Muster für einen kleinen Einblick. Sie können unser Colab überprüfen, um es selbst zu probieren!
Englische Sprache, weibliche Stimme (übertragen aus einem polnischen Sprachdatensatz):
Eine polnische Probe, männliche Stimme:
Ältere Fortschrittsaktualisierungen werden hier archiviert
Wir empfehlen Ihnen, mit dem Google Colab -Link oben zu beginnen oder das bereitgestellte Notebook lokal auszuführen. Wenn Sie manuell herunterladen oder die Modelle von Grund auf neu trainieren möchten, sind sowohl die vorgebildeten Modelle von WhisperSpeech als auch die konvertierten Datensätze auf Huggingface verfügbar.
Die allgemeine Architektur ähnelt Audiolm, Speer -TTs von Google und MusicGen von Meta. Wir haben das NIH-Syndrom vermieden und auf leistungsstarken Open Source-Modellen: Whisper von OpenAI gebaut, um semantische Token zu erzeugen und Transkription aus Meta für akustische Modellierung und Vocos von Charactr Inc als hochwertiger Vokoder durchzuführen.
Wir gaben zwei Präsentationen, die tiefer in Whisperspeech tauchten. Der erste spricht über die Herausforderungen des großen Trainings:
Tricks, die aus Skaling -Whisperspeech -Modellen bis zu 80 km+ Stunden Sprache gelernt werden - Videoaufzeichnung von Jakub Cłapa, COMPOSELA
Der andere ist ein bisschen mehr in die architektonischen Entscheidungen, die wir getroffen haben:
Open-Source-Text-zu-Sprach-Projekte: Whisperspeech-Tiefe Diskussion
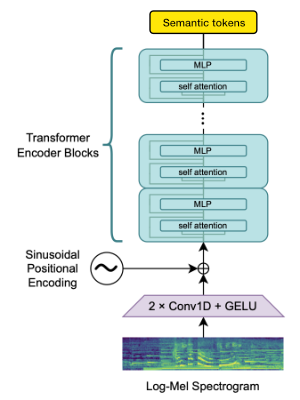
Wir verwenden den Openai Whisper -Encoder -Block, um Einbettungen zu erzeugen, die wir dann quantisieren, um semantische Token zu erhalten.
Wenn die Sprache bereits von Whisper unterstützt wird, erfordert dieser Vorgang nur Audiodateien (ohne Grundwahrheitsübertragungen).
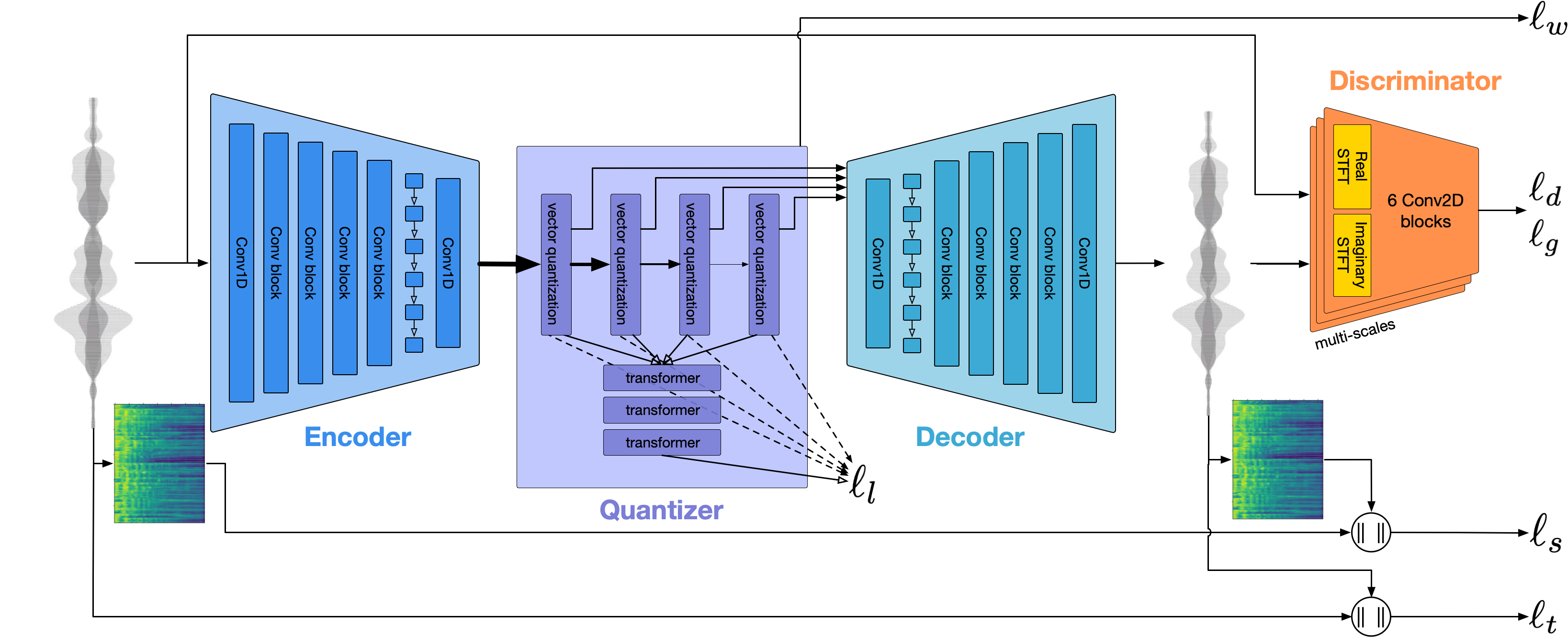
Wir verwenden CCODEC, um die Audio -Wellenform zu modellieren. Aus der Schachtel liefert es eine angemessene Qualität bei 1,5 kbit / s, und wir können diese mit Vocos-einem Vocoder-Vocer-Vocoder, der auf CCODEC-Token vorbereitet ist, auf hohe Qualität bringen.


Diese Arbeit wäre ohne die großzügigen Sponsoring von:
Wir danken dem Gauß-Zentrum für Supercomputing EV (www.gauss-centre.eu) für die Finanzierung eines Teils dieser Arbeiten, indem wir über das John von Neumann Institute for Computing (NIC) in der GCS-Supercomputer-Juwels-Booster-Booster bei Jüloich Supercomputing Center (JSCS-Supercomputer-Supercomputer-Supercomputer-Juwels-Juwel-Cooperations-Modell-Forschungsarbeiten) eine Rechenzeit bereitstellen.
Wir möchten auch den individuellen Mitwirkenden für ihre große Hilfe beim Aufbau dieses Modells danken:
qwerty_qwer über Discord) für die Datensatzkuration Wir können Ihnen sowohl bei Open Source- als auch bei proprietären KI -Projekten helfen. Sie können uns über die Collabora -Website oder auf Discord (und) erreichen
Wir verlassen uns auf viele erstaunliche Open -Source -Projekte und Forschungsarbeiten:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

