WhisperSpeech
1.0.0
質問がある場合、またはサポートしたい場合は、Laion Discordサーバーの#Audio-Generationチャネルで私たちを見つけることができます。
ささやきを反転させることによって構築されたオープンソースのテキストからスピーチシステム。以前はSpear-Tts-Pytorchとして知られていました。
このモデルは、安定した拡散のように、スピーチのために、強力で簡単にカスタマイズ可能であることを望んでいます。
私たちは適切にライセンスされたスピーチの録音でのみ作業しており、すべてのコードはオープンソースであるため、モデルは商業用アプリケーションに常に安全に使用できます。
現在、モデルはEnglish Librelightデータセットでトレーニングされています。次のリリースでは、複数の言語をターゲットにしたいと考えています(WhisperとEncodecはどちらも多言語です)。
合成された音声のサンプル:
EN+PL+FRデータセットでtiny S2Aモデルを正常にトレーニングし、フランス語で音声クローニングを行うことができます。
英語とポーランド語でのみ訓練された冷凍セマンティックトークンでこれを行うことができました。これは、世界のすべての言語をサポートするために単一のセマンティックトークンモデルをトレーニングできるという考えをサポートしています。現在、ささやきモデルによって十分にサポートされていないものでさえもおそらくそうです。この面での最新情報をお楽しみに。 :)
先週、推論のパフォーマンスを最適化します。 torch.compileを統合し、KVキャッシングを追加し、いくつかのレイヤーを調整しました。現在、消費者4090でリアルタイムよりも12倍以上作業しています。
言語を単一の文で混ぜることができます(ここでは、ハイライトされた英語のプロジェクト名はシームレスにポーランド語のスピーチに混ざり合っています):
Pierwszy Test toWielojęZycznegoWhisper
Whisper SpeechModeluZamieniającegoTekst NaMowę、CollaboraLaionnauczyli na superkomputerzeJewels。
また、音声クローニングをテストする簡単な方法も追加しました。ウィンストンチャーチルによる有名なスピーチからクローン化されたサンプル音声は次のとおりです(ラジオスタティックはバグではなく機能です;) - それは参照録音の一部です):
これらすべてをColabでテストできます(依存関係を最適化したため、インストールに30秒未満かかります)。ハギングフェイススペースがまもなく登場します。
高品質のスピーチを生成しながら、はるかに高速な新しいSD S2Aモデルをプッシュしました。また、参照オーディオファイルに基づいて音声クローニングの例を追加しました。
いつものように、あなたは私たちのコラブをチェックして自分で試してみることができます!
モデルの別のトリオ、今回は複数の言語(英語とポーランド)をサポートしています。スニークピーク用の2つの新しいサンプルを次に示します。あなたは私たちのcolabをチェックして自分で試してみることができます!
英語のスピーチ、女性の声(ポーランド語のデータセットから転送):
ポーランドのサンプル、男性の声:
古い進行状況の更新はここにアーカイブされています
上記のGoogle Colabリンクから開始するか、提供されたノートをローカルに実行することをお勧めします。手動でダウンロードするか、モデルをゼロからトレーニングする場合は、WhisperSpeechの事前訓練モデルと変換されたデータセットの両方がHuggingfaceで利用できます。
一般的なアーキテクチャは、Googleの槍TTS、MetaのMusicGenに似ています。 NIH症候群を避け、強力なオープンソースモデルの上に構築しました。Openaiからささやき、セマンティックトークンを生成し、Transcription、Acoustic Modeling for Acoustic ModelingのEncodec、および高品質のボコーダーとしてCharstr IncのVocosを実行します。
WhisperSpeechに2つのプレゼンテーションダイビングを掘り下げました。最初のものは、大規模なトレーニングの課題について説明しています。
スケーリングされたwhisperspeechモデルから80k以上の音声まで学んだトリック - jakubcłapa、collaboraによるビデオ録画
もう1つは、私たちが行った建築の選択にもう少し入ります。
オープンソースのテキストからスピーチプロジェクト:WhisperSpeech-詳細な議論
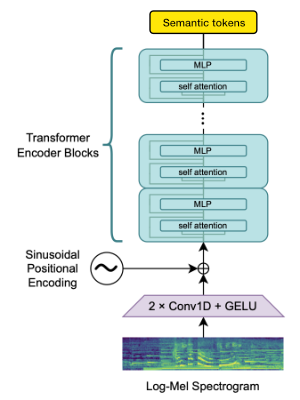
Openai Whisperエンコーダブロックを利用して、埋め込みを生成し、それを計量してセマンティックトークンを取得します。
言語が既にwhisperによってサポートされている場合、このプロセスにはオーディオファイルのみが必要です(グラウンドトゥルースの転写なし)。
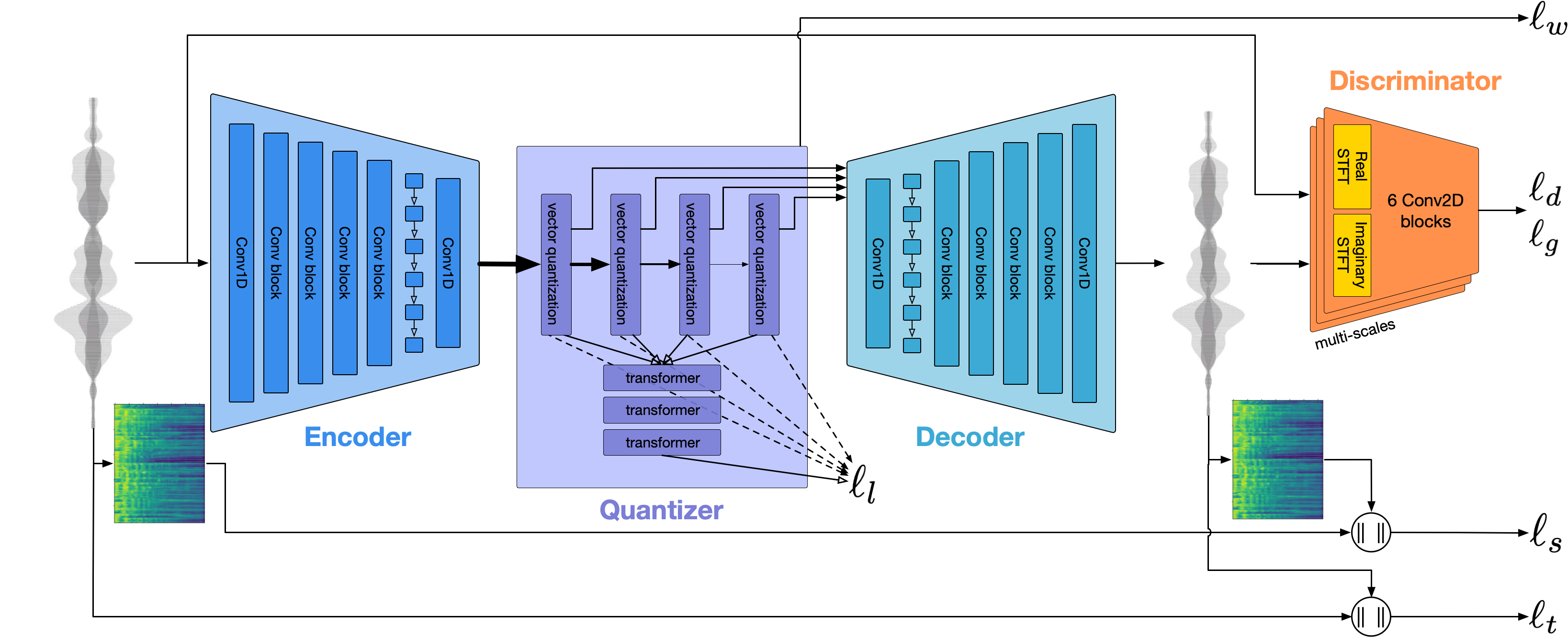
Encodecを使用して、オーディオ波形をモデル化します。箱から出して、1.5kbpsでリーズナブルな品質を提供し、Encodec Tokensで事前に処理されたボコーダーであるVocosを使用して、これを高品質にすることができます。


この作業は、次の寛大なスポンサーシップなしでは不可能です。
GAUSS Center for Supercomputing EV(www.gauss-centre.eu)は、Jolich Supercuting Center(JSC)のGCSスーパーコンピューターJuwels Booster(JSC)のGCSスーパーコンピューターJuwels Booster(JSC)のコンピューティング(NIC)を通じてコンピューティング時間を通じてコンピューティング時間を提供することにより、この作業の一部に資金を提供してくれたことに感謝しています。
また、このモデルの構築に大きな支援をしてくれた個々の貢献者にも感謝したいと思います。
qwerty_qwer on discord on discord) オープンソースと独自のAIプロジェクトの両方を支援することができます。 CollaboraのWebサイトまたはDiscord(および)を介して私たちに連絡することができます
私たちは、多くの驚くべきオープンソースプロジェクトや研究論文に依存しています。
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

