WhisperSpeech
1.0.0
Jika Anda memiliki pertanyaan atau Anda ingin membantu Anda dapat menemukan kami di saluran #audio-generasi di server Laion Discord.
Sistem teks-ke-ucapan sumber terbuka yang dibangun dengan membalikkan bisikan. Sebelumnya dikenal sebagai Spear-Tts-Pytorch .
Kami ingin model ini menjadi seperti difusi yang stabil tetapi untuk ucapan - baik yang kuat dan mudah disesuaikan.
Kami hanya bekerja dengan rekaman pidato berlisensi dengan benar dan semua kode adalah open source sehingga model akan selalu aman digunakan untuk aplikasi komersial.
Saat ini model dilatih pada dataset perpustakaan bahasa Inggris. Dalam rilis berikutnya kami ingin menargetkan beberapa bahasa (Whisper dan EncodeC keduanya multilanguage).
Sampel suara yang disintesis:
Kami berhasil melatih model S2A tiny pada dataset EN+PL+FR dan dapat melakukan kloning suara dalam bahasa Prancis:
Kami dapat melakukan ini dengan token semantik beku yang hanya dilatih dalam bahasa Inggris dan Polandia. Ini mendukung gagasan bahwa kami akan dapat melatih model token semantik tunggal untuk mendukung semua bahasa di dunia. Kemungkinan besar bahkan yang saat ini tidak didukung dengan baik oleh model Whisper. Nantikan lebih banyak pembaruan di bagian depan ini. :)
Kami menghabiskan minggu terakhir mengoptimalkan kinerja inferensi. Kami mengintegrasikan torch.compile .
Kami dapat mencampur bahasa dalam satu kalimat (di sini nama proyek bahasa Inggris yang disorot dengan mulus dicampur menjadi pidato Polandia):
Untuk bercanda tes pierwszy wielojęzycznego
Whisper Speechmodelu zamieniającego na mowę, któryCollaboraiLaionnauczyli na superkomputerzeJewels.
Kami juga menambahkan cara mudah untuk menguji kloning suara. Berikut adalah sampel suara yang dikloning dari pidato terkenal oleh Winston Churchill (Radio Static adalah fitur, bukan bug;) - itu adalah bagian dari rekaman referensi):
Anda dapat menguji semua ini di Colab (kami mengoptimalkan dependensi sehingga sekarang dibutuhkan kurang dari 30 detik untuk menginstal). Ruang permukaan pelukan akan segera hadir.
Kami telah mendorong model SD S2A baru yang jauh lebih cepat saat masih menghasilkan pidato berkualitas tinggi. Kami juga telah menambahkan contoh kloning suara berdasarkan file audio referensi.
Seperti biasa, Anda dapat memeriksa Colab kami untuk mencobanya sendiri!
Trio model lain, kali ini mereka mendukung berbagai bahasa (Inggris dan Polandia). Berikut adalah dua sampel baru untuk mengintip. Anda dapat memeriksa Colab kami untuk mencobanya sendiri!
Pidato Bahasa Inggris, Suara Wanita (ditransfer dari dataset bahasa Polandia):
Sampel Polandia, Suara Pria:
Pembaruan kemajuan yang lebih tua diarsipkan di sini
Kami mendorong Anda untuk memulai dengan tautan Google Colab di atas atau menjalankan notebook yang disediakan secara lokal. Jika Anda ingin mengunduh secara manual atau melatih model dari awal maka baik model pra-terlatih Whisperspeech serta dataset yang dikonversi tersedia di Huggingface.
Arsitektur umumnya mirip dengan Audiolm, tts tts dari Google dan Musicgen dari meta. Kami menghindari sindrom NIH dan membangunnya di atas model open source yang kuat: Whisper dari openai untuk menghasilkan token semantik dan melakukan transkripsi, encodec dari meta untuk pemodelan akustik dan voko dari ChARACTR Inc sebagai vokoder berkualitas tinggi.
Kami memberikan dua presentasi menyelam lebih dalam ke Whisperspeech. Yang pertama berbicara tentang tantangan pelatihan skala besar:
Trik yang dipelajari dari menskalakan model wisperspeech ke 80k+ jam pidato - perekaman video oleh Jakub Cłapa, Collabora
Yang lain sedikit lebih ke pilihan arsitektur yang kami buat:
Proyek teks-ke-ucapan open source: Whisperspeech-dalam diskusi mendalam
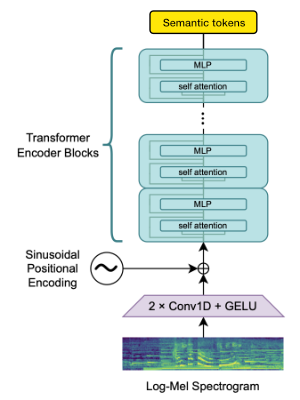
Kami menggunakan blok encoder Whisper Openai untuk menghasilkan embeddings yang kemudian kami kuantisasi untuk mendapatkan token semantik.
Jika bahasa sudah didukung oleh Whisper maka proses ini hanya membutuhkan file audio (tanpa transkripsi kebenaran ground).
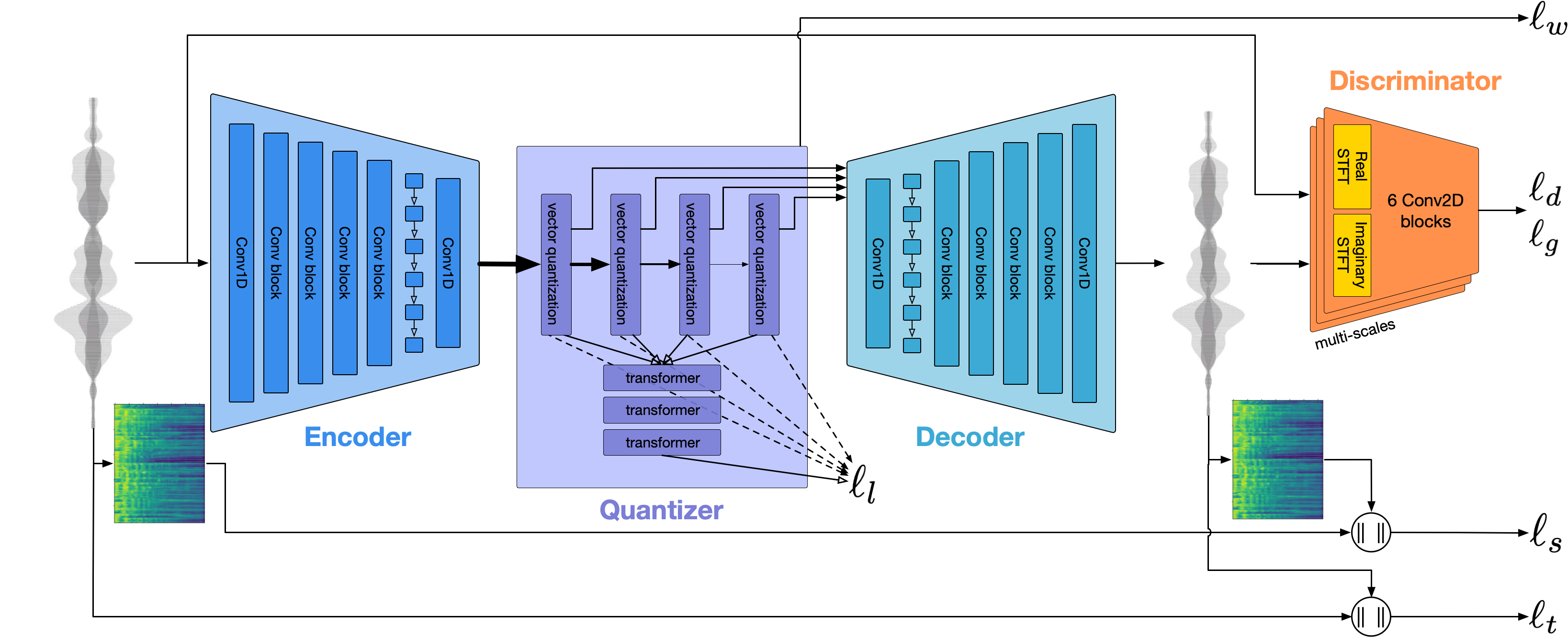
Kami menggunakan EncodeC untuk memodelkan bentuk gelombang audio. Di luar kotak itu memberikan kualitas yang wajar pada 1.5kbps dan kami dapat membawa ini ke kualitas tinggi dengan menggunakan voco-vokoder yang diproduksi pada token encodec.


Pekerjaan ini tidak akan mungkin terjadi tanpa sponsor yang murah hati dari:
Kami berterima kasih atas Gauss Center for Supercomputing EV (www.gauss-centre.eu) untuk mendanai bagian dari pekerjaan ini dengan menyediakan waktu komputasi melalui John von Neumann Institute for Computing (NIC) pada model superkomputer GCS yang disediakan melalui Compute Booster di Jülich Supercomputing Center (JSC), dengan akses ke Compute Booster di Jülich Supercomputing Center (JSC), dengan akses ke Compute Booster di Jülich Courecomputing Center (JSC), dengan akses ke Compute Booster di Jülich Supercomputing Center.
Kami juga ingin mengucapkan terima kasih kepada kontributor individu atas bantuannya dalam membangun model ini:
qwerty_qwer on discord) untuk kurasi dataset Kami tersedia untuk membantu Anda dengan proyek AI open source dan eksklusif. Anda dapat menghubungi kami melalui situs web collabora atau di perselisihan (dan)
Kami mengandalkan banyak proyek open source yang luar biasa dan makalah penelitian:
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

