WhisperSpeech
1.0.0
궁금한 점이 있거나 Laion Discord 서버의 #Audio-Generation Channel에서 우리를 찾을 수 있도록 도와 드리겠습니다.
Whisper를 반전하여 구축 된 오픈 소스 텍스트 음성 시스템. 이전에는 Spear-Tts-Pytorch 로 알려져 있습니다.
우리는이 모델이 안정된 확산과 같지만 강력하고 쉽게 사용자 정의 할 수있는 연설을 원합니다.
우리는 적절하게 라이센스가 부여 된 음성 녹음만으로 작업하고 있으며 모든 코드는 오픈 소스이므로 모델은 항상 상용 애플리케이션에 안전합니다.
현재 모델은 English LibreLight 데이터 세트에서 교육을받습니다. 다음 릴리스에서는 여러 언어를 타겟팅하려고합니다 (Whisper 및 Encodec은 다중 언어입니다).
합성 된 음성의 샘플 :
EN+PL+FR 데이터 세트에서 tiny S2A 모델을 성공적으로 교육했으며 프랑스어로 음성 복제를 수행 할 수 있습니다.
우리는 영어와 폴란드어로만 훈련 된 냉동 시맨틱 토큰으로 이것을 할 수있었습니다. 이것은 우리가 전 세계의 모든 언어를 지원하기 위해 단일 시맨틱 토큰 모델을 훈련시킬 수 있다는 아이디어를 지원합니다. Whisper Model에서 현재 잘 지원되지 않는 것들조차도 가능합니다. 이 앞에서 더 많은 업데이트를 보려면 계속 지켜봐 주시기 바랍니다. :)
우리는 지난주 추론 성능을 최적화합니다. 우리는 torch.compile 통합하고 KV 캐싱을 추가하고 일부 레이어를 조정했습니다. 이제 소비자 4090에서 실시간보다 12 배 이상 빠르게 작업하고 있습니다!
우리는 언어를 한 문장으로 혼합 할 수 있습니다 (여기서 강조 표시된 영어 프로젝트 이름은 폴란드어 연설에 원활하게 혼합되어 있습니다) :
Jest Pierwszy 테스트 wielojęzycznego
Whisper Speechmodelu zamieniającego tekst na mowę, któryCollaboraiLaionnauczyli na superkomputerzeJewels.
또한 음성 클로닝을 테스트하는 쉬운 방법을 추가했습니다. 다음은 Winston Churchill의 유명한 연설에서 복제 된 샘플 음성입니다 (Radio Static은 버그가 아닌 기능입니다.) - 참조 녹음의 일부입니다).
Colab 에서이 모든 것을 테스트 할 수 있습니다 (종속성을 최적화하므로 이제 설치하는 데 30 초 미만이 소요됩니다). 포옹 페이스 공간이 곧 올 것입니다.
우리는 고품질의 음성을 생성하면서 훨씬 더 빠른 새로운 SD S2A 모델을 추진했습니다. 또한 참조 오디오 파일을 기반으로 음성 복제의 예를 추가했습니다.
언제나 그렇듯이, 당신은 우리의 콜랩을 확인하여 직접 시도 할 수 있습니다!
또 다른 모델의 트리오, 이번에는 여러 언어 (영어 및 광택)를 지원합니다. 몰래 엿보기를위한 두 가지 새로운 샘플이 있습니다. 당신은 우리의 colab을 확인하여 직접 시도 할 수 있습니다!
영어 연설, 여성 목소리 (폴란드 언어 데이터 세트에서 전송) :
폴란드 샘플, 남성 음성 :
이전 진행 상황 업데이트는 여기에 보관됩니다
위의 Google Colab 링크부터 시작하거나 제공된 노트를 로컬로 실행하는 것이 좋습니다. 수동으로 다운로드하거나 처음부터 모델을 훈련하려면 Whisperspeech 사전 훈련 된 모델과 변환 된 데이터 세트를 Huggingface에서 사용할 수 있습니다.
일반 아키텍처는 Audiolm, Google의 Spear TT 및 Meta의 MusicGen과 유사합니다. 우리는 NIH 증후군을 피하고 강력한 오픈 소스 모델 위에 구축했습니다. Openai에서 속삭임을 위해 Semantic Tokens를 생성하고 전사, 음향 모델링을위한 메타의 Encodec 및 Charact Inc의 고품질 보코더로서 Vocos를 수행합니다.
우리는 Whisperspeech에 더 깊이 다이빙을 주었다. 첫 번째는 대규모 훈련의 도전에 대해 이야기합니다.
Whisperspeech 모델을 80k 이상의 음성으로 스케일링하여 배운 트릭 - jakub cłapa, 콜라보라의 비디오 녹화
다른 하나는 우리가 만든 건축 선택에 조금 더 많이 들어갑니다.
오픈 소스 텍스트 음성 연설 프로젝트 : Whisperspeech- 깊이있는 토론
Openai Whisper Encoder 블록을 사용하여 임베딩을 생성 한 다음 의미 론적 토큰을 얻기 위해 정량화합니다.
언어가 이미 Whisper에 의해 지원되는 경우이 프로세스에는 오디오 파일 만 필요합니다 (Ground Truth 전사없이).
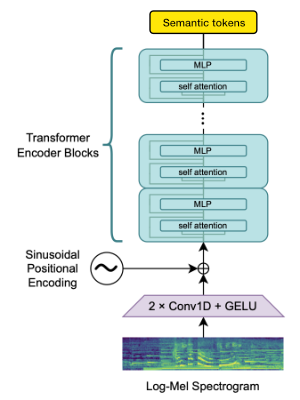
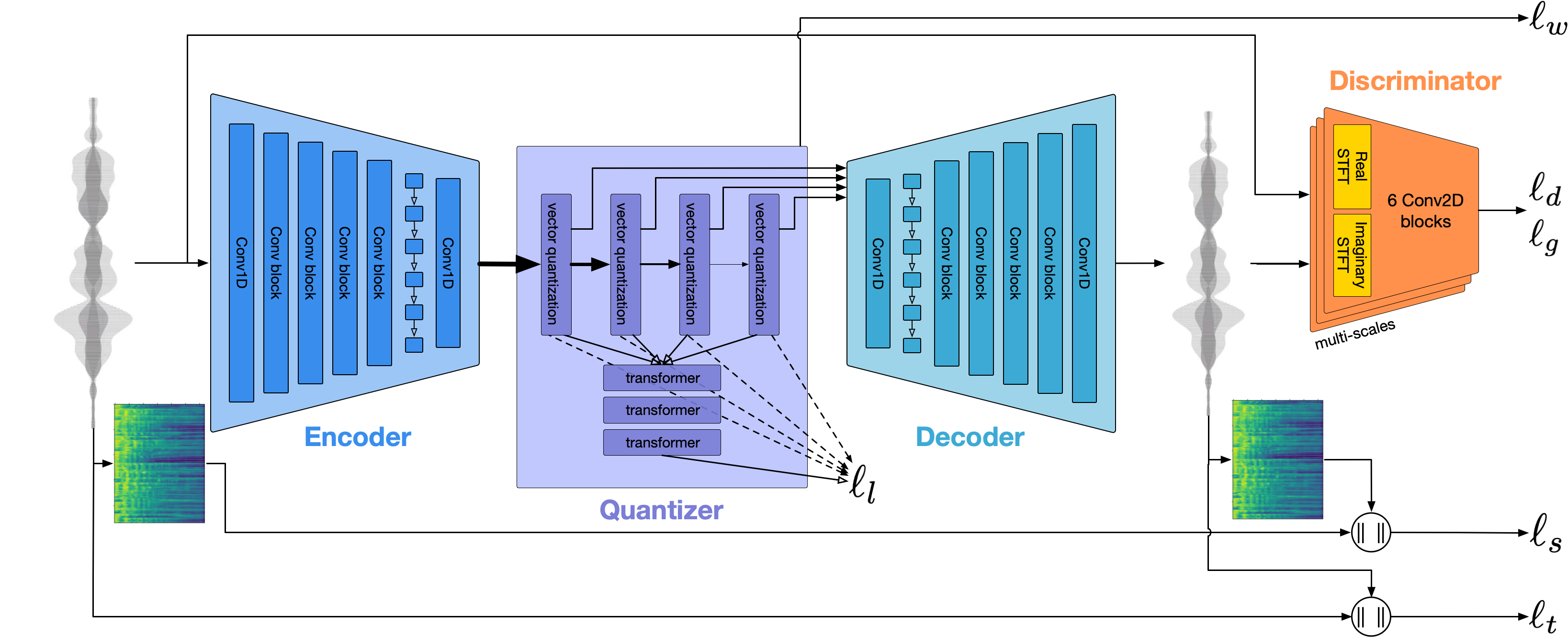
우리는 encodec을 사용하여 오디오 파형을 모델링합니다. 상자에서 1.5kbps에서 합리적인 품질을 제공하며 Encodec 토큰에 전망 된 보코더 인 Vocos를 사용하여 고품질로 가져올 수 있습니다.


이 작업은 다음과 같은 관대 한 후원 없이는 불가능할 것입니다.
우리는 John Von Neumann Computing Institute for Computing Institute for Computing Institute (NIC)를 통해 Computing Time을 제공하여 JULICH SUPERCOMPETING CENTRE (JSC)의 JULICH SUPERCOMPETING CENCE (JSC)를 통해 컴퓨팅 시간을 제공 함으로써이 작업의 일부를 제공 함으로써이 작업의 일부를 제공 함으로써이 작업의 일부를 제공함으로써 SuperComputing EV (www.gauss-centre.eu)를위한 가우스 센터에 감사의 말을 전합니다.
또한이 모델을 구축하는 데 큰 도움을 주신 개인 기고자들에게도 감사의 말씀을 전합니다.
qwerty_qwer ) 오픈 소스 및 독점 AI 프로젝트를 모두 도와 드릴 수 있습니다. Collabora 웹 사이트 또는 Discord (및)를 통해 우리에게 연락 할 수 있습니다.
우리는 많은 놀라운 오픈 소스 프로젝트 및 연구 논문에 의존합니다.
@article { SpearTTS ,
title = { Speak, Read and Prompt: High-Fidelity Text-to-Speech with Minimal Supervision } ,
url = { https://arxiv.org/abs/2302.03540 } ,
author = { Kharitonov, Eugene and Vincent, Damien and Borsos, Zalán and Marinier, Raphaël and Girgin, Sertan and Pietquin, Olivier and Sharifi, Matt and Tagliasacchi, Marco and Zeghidour, Neil } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { MusicGen ,
title = { Simple and Controllable Music Generation } ,
url = { https://arxiv.org/abs/2306.05284 } ,
author = { Jade Copet and Felix Kreuk and Itai Gat and Tal Remez and David Kant and Gabriel Synnaeve and Yossi Adi and Alexandre Défossez } ,
publisher = { arXiv } ,
year = { 2023 } ,
} @article { Whisper
title = { Robust Speech Recognition via Large-Scale Weak Supervision } ,
url = { https://arxiv.org/abs/2212.04356 } ,
author = { Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { EnCodec
title = { High Fidelity Neural Audio Compression } ,
url = { https://arxiv.org/abs/2210.13438 } ,
author = { Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi } ,
publisher = { arXiv } ,
year = { 2022 } ,
} @article { Vocos
title = { Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis } ,
url = { https://arxiv.org/abs/2306.00814 } ,
author = { Hubert Siuzdak } ,
publisher = { arXiv } ,
year = { 2023 } ,
}

