自動視頻配音系統從英語到阿拉伯語
該項目介紹了一項有關視頻配音技術的全面研究和專門視頻配音系統的開發。目的是用外語視頻中的原始聲音替換出演員的聲音,同時確保唇部動作和被稱為語音之間的同步。
自動視頻配音的重要性
視頻配音旨在使整個世界文化的視頻內容不變。自動視頻配音系統通常涉及三個子任務:
- 自動語音識別(ASR),將原始語音轉錄為源語言。
- 神經機器翻譯(NMT),將源語言文本轉換為目標語言。
- 文本到語音(TTS),將翻譯的文本綜合為目標語音。
視頻配音可以增強多語言內容的可訪問性,參與度和全球分佈,同時保留跨文化交流的視覺完整性。
挑戰
自動視頻配音面臨幾個挑戰:
- 嘴唇同步精度
- 稱為聲音的自然性
- 文化適應和本地化
- 多語言和多元文化的考慮
- 代碼切換。
方法論
提出的方法涉及:
- 將音頻和視頻與源英文視頻分開
- 使用語音翻譯將英語音頻翻譯成阿拉伯語
- 保留原始視頻幀
- 將翻譯的阿拉伯語演講與視頻框架合併,以創建一個名為阿拉伯語的視頻
為了改善結果,語音翻譯器中使用了另外兩個模型:
- 標點符號模型,以增加標點符號
- Tashkeel模型為阿拉伯文字添加了音調標記
| 配音視頻的管道 | 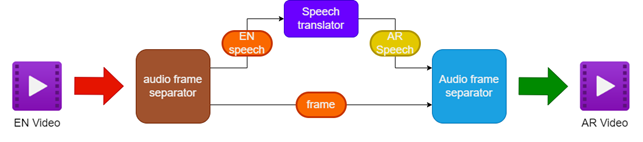 |
|---|
| 言語塔恩斯洛斯 | 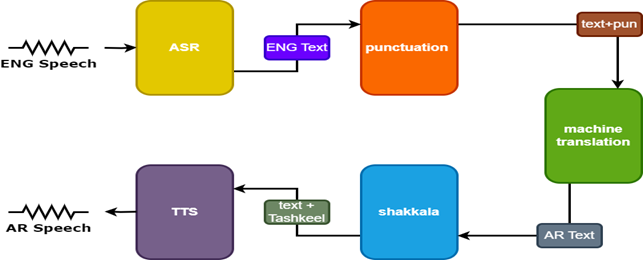 |
系統體系結構
該系統遵循一個模塊化體系結構,該體系結構包括:
- 用戶面對應用程序(Flutter App)
- 應用程序服務器(Localhost和Herouku)
- 數據庫服務器(firebase)
- ASR,NMT,TTS的機器學習管道(Pytorch,TensorFlow和HuggingFace)
| 系統主組合 | 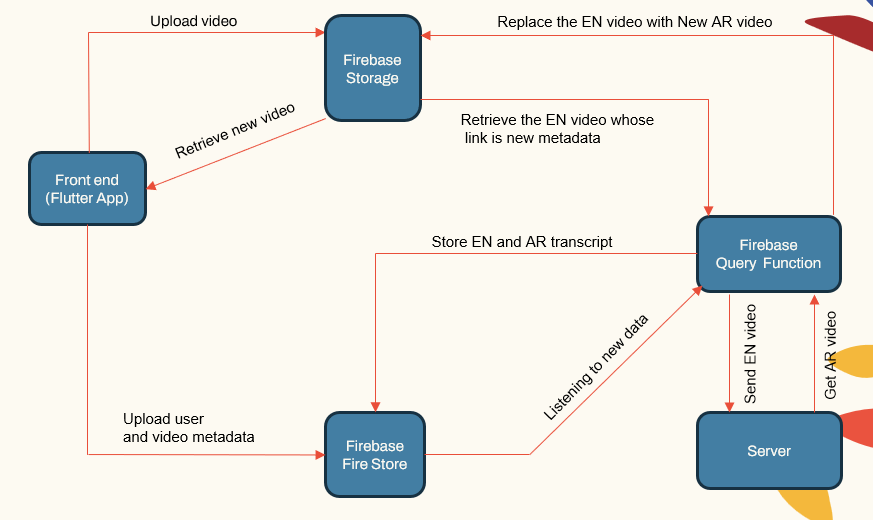 |
|---|
應用程序服務器處理用戶管理,視頻上傳/下載以及與ML管道的接口。數據庫存儲用戶數據,視頻元數據,成績單等。
語音識別
實驗比較了Wave2VEC2.0和Google語音識別API。 Wave2Vec2.0通過在大型未標記的語音數據上進行預處理,然後在一個小標記的數據集上進行填充,從而給出了較低的單詞錯誤率。 CTC損失函數用於訓練聲學模型,以將語音特徵轉換為字符概率。
| wave2vec2.0與CTC解碼 | 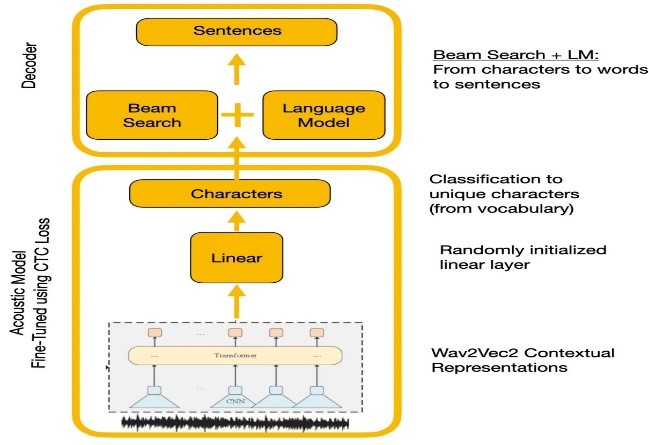 |
|---|
機器翻譯
Google的NMT體系結構利用具有註意機制的LSTM層:
- 編碼器LSTM將源文本轉換為向量表示
- 注意模塊將源表示與每個目標單詞對齊
- 解碼器LSTM根據上下文向量依次預測目標單詞
關鍵優化包括:
- 字節對編碼單詞中的子詞來處理稀有單詞
- 堆疊LSTM層中的殘留連接以改善梯度流量
- 梁搜索解碼以減少錯誤並找到最佳翻譯
| MT的編碼器解碼器 | 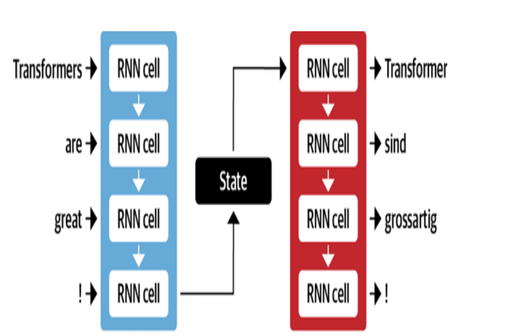 |
|---|
文字到語音
FastSpeech2是一種非自動回歸神經TTS模型,與推理期間的WaveNet這樣的自回歸模型相比,可以更快地合成。該模型將文本視為輸入,並使用變壓器編碼器解碼器體系結構來預測MEL-SPECTROGRAM聲學特徵。模型體系結構中使用了帶有捲積處理的多層感知器(MLP),而不是擴張的捲積。這提供了本地功能建模。將其他方差預測變量納入模型語音屬性,例如音高,持續時間和能量曲線。這改善了韻律和自然。
總而言之,關鍵方面是:
- 非自動收益平行合成
- 變形金剛編碼器
- 本地上下文的MLP層
- 差異預測因子捕獲語音概況
這允許FastSpeech2在推理過程中並行從文本產生高質量的MEL光譜圖,同時保持自然韻律和語音特徵。
| FastSpeech2 | 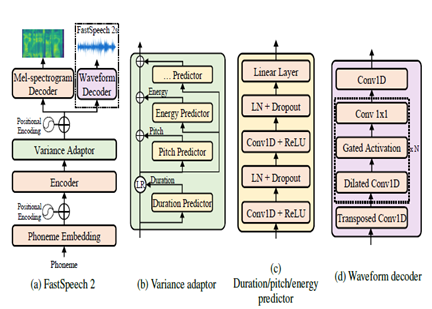 |
|---|
結果
根據作為測試過程的一部分進行的主觀評估,確定的一些關鍵領域可進一步改善翻譯和配音質量:
- 嘴唇同步:精心調整稱為語音的時間和持續時間以更好地匹配唇部運動所需的更多工作。
- 表達:通過在被稱為演講中的適當語調和韻律來捕捉原始演講中的情感和重點。
- 流利性:在句子的流動性方面,在翻譯的阿拉伯語語音中檢測到了一些不自然性。
- 術語:特定領域的詞彙提出了挑戰,尤其是技術術語。專用域的性能下降。
- 演講者的相似性:雖然創建了多個揚聲器模型,但需要更多個性化以更好地模仿原始揚聲器的聲音。
- 背景噪聲:降低背景工件的量和改善聲音的音頻清晰度。
- 語法:在翻譯過程中進行更好的語法分析,以產生完美的阿拉伯語句子。
- 辯證語音:處理非正式語言,方言和語。
參考
- Alexei Baevski,HZ-R。 (2020)。 WAV2VEC 2.0:一個自我監督語音表示學習的框架。神經。元。
- Anmol Gulati,JQ-C。 (2020)。構象體:捲捲動的變壓器,以供語音識別。神經。
- Ashish Vaswani,NS(2017)。注意就是您所需要的。神經。
- Chenxu Hu1,QT(2021)。神經配音:根據腳本為視頻配音。神經。
- Marcello Federico,Re-C。 (2020)。從語音到語音翻譯到自動配音。第17屆國際口語翻譯會議論文集(第257-264頁)。計算語言學協會。
- Nigel G. Ward,JE(2022)。跨語言重新制定對話。 UTEP-CS-22-108。
- MW(2022)。語音翻譯的跨模式對比度學習。 Naacl。
- Wei-ning HSU,BB-H。 (2021)。休伯特:通過掩蓋隱藏單位的掩蓋預測,自我監督的語音表示學習。神經(第10頁)。元。
- Yifan Peng,SD(2022)。分支機構:平行MLP注意體系結構,以捕獲語音識別和理解的本地和全球環境。 ICML。
- Yihan Wu,JG(2023)。 VideoDubber:帶有語音感知長度控制視頻配音的機器翻譯。 AAAI。
- 克拉姆項目
- NVIDIA的Nemo Toolkit
- 擁抱面
- 插圖的變壓器文章
- 帶註釋的變壓器
- 自我訓練和預訓練,了解WAV2VEC系列
- 伯特解釋了:NLP的最先進的語言模型


