نظام دبلجة الفيديو التلقائي من اللغة الإنجليزية إلى اللغة العربية
يقدم هذا المشروع دراسة شاملة حول تقنيات دبلجة الفيديو وتطوير نظام دبلجة الفيديو المتخصص. الهدف من ذلك هو استبدال الأصوات الأصلية في مقاطع فيديو اللغة الأجنبية بأصوات الفنانين الذين يتحدثون لغة الجمهور المستهدف ، مع ضمان التزامن بين حركات الشفاه والكلام الدبلج.
أهمية الفيديو التلقائي
يهدف الفيديو Dubbing إلى جعل محتوى الفيديو ثابتًا عبر الثقافات العالمية. تتضمن أنظمة Dubbing التلقائية عادة ثلاثة مهام فرعية:
- التعرف على الكلام التلقائي (ASR) ، الذي ينسخ الكلام الأصلي إلى نص بلغة المصدر.
- ترجمة الآلة العصبية (NMT) ، والتي تترجم نص لغة المصدر إلى اللغة المستهدفة.
- النص إلى الكلام (TTS) ، والذي يتجمع النص المترجم في الكلام المستهدف.
يعزز الفيديو Dubbing إمكانية الوصول والمشاركة والتوزيع العالمي للمحتوى متعدد اللغات مع الحفاظ على النزاهة البصرية للاتصال بين الثقافات.
التحديات
يواجه الفيديو التلقائي ، العديد من التحديات:
- دقة مزامنة الشفاه
- طبيعية الصوت المدبل
- التكيف الثقافي والتوطين
- اعتبارات متعددة اللغات ومتعددة الثقافات
- رمز تبديل.
المنهجية
تتضمن المنهجية المقترحة:
- فصل الصوت والفيديو عن مصدر الفيديو الإنجليزي
- ترجمة الصوت الإنجليزي إلى الخطاب العربي باستخدام مترجم خطاب
- الحفاظ على إطارات الفيديو الأصلية
- دمج الخطاب العربي المترجم مع إطارات الفيديو لإنشاء مقطع فيديو عربي يطلق عليه
لتحسين النتائج ، يتم استخدام نموذجين إضافيين في مترجم الكلام:
- نموذج علامات الترقيم لإضافة علامات الترقيم إلى ترجمات اللغة الإنجليزية
- طراز Tashkeel لإضافة علامات التشكيل إلى النص العربي
| خط أنابيب للفيديو Dubbing | 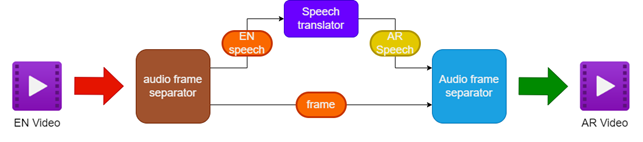 |
|---|
| الكلام تارنسلور | 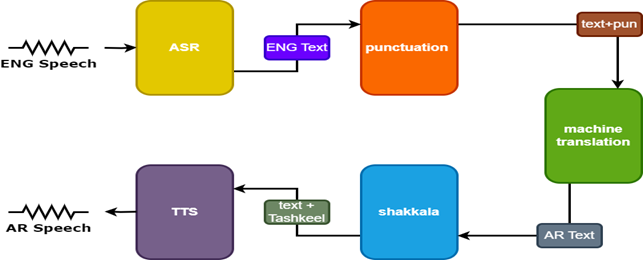 |
بنية النظام
يتبع النظام بنية معيارية تتكون من:
- المستخدم الذي يواجه التطبيقات (تطبيق Flutter)
- خادم التطبيق (LocalHost و Herouku)
- خادم قاعدة البيانات (Firebase)
- خطوط أنابيب التعلم الآلي لـ ASR و NMT و TTS (Pytorch و TensorFlow و Huggingface)
| النظام الرئيسي componenet | 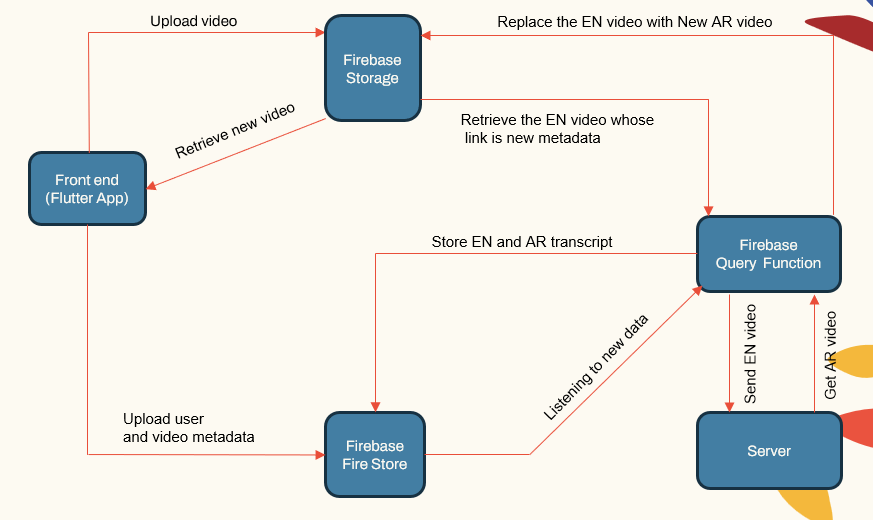 |
|---|
يعالج خادم التطبيق إدارة المستخدم ، وتحميل/تنزيلات الفيديو ، والتواصل مع خطوط أنابيب ML. تقوم قاعدة البيانات بتخزين بيانات المستخدم ، وبيانات تعريف الفيديو ، والنصوص ، إلخ.
التعرف على الكلام
قارنت التجارب WAVE2VEC2.0 و APIs التعرف على الكلام Google. أعطى WAVE2VEC2.0 معدلات خطأ في الكلمات الأدنى عن طريق التدريب على بيانات الكلام الكبيرة غير المسماة تليها FINETUNING على مجموعة بيانات صغيرة المسمى. تم استخدام وظيفة فقدان CTC لتدريب النموذج الصوتي لتحويل ميزات الكلام إلى احتمالات الأحرف.
| Wave2Vec2.0 مع فك تشفير CTC | 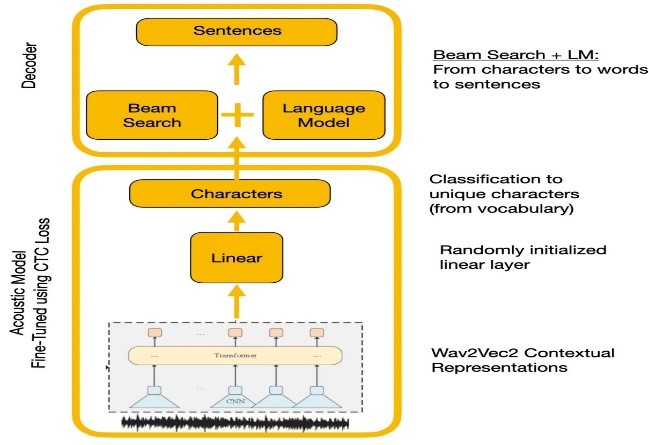 |
|---|
الترجمة الآلية
تستخدم بنية NMT من Google طبقات LSTM مع آلية الانتباه:
- يشفر LSTM النص المصدر إلى تمثيلات متجه
- وحدة الانتباه توافق على تمثيل المصدر لكل كلمة مستهدفة
- يتنبأ Decoder LSTM بالكلمات المستهدفة بشكل متتابع بناءً على متجهات السياق
تشمل التحسينات الرئيسية:
- ترميز البايت للكلمات إلى كلمات فرعية للتعامل مع الكلمات النادرة
- الاتصالات المتبقية في طبقات LSTM مكدسة لتحسين تدفق التدرج
- فك تشفير بحث الشعاع لتقليل الأخطاء وإيجاد الترجمات المثلى
| وحدة فك ترميز تشفير MT | 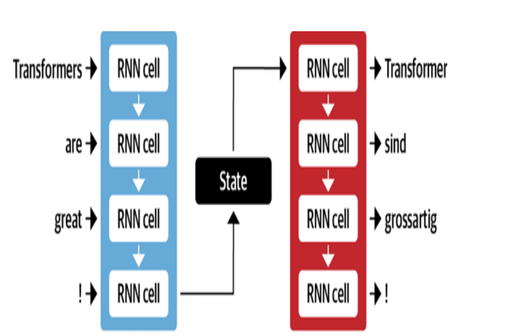 |
|---|
رسالة نصية إلى الكلام
Fastspeade2 هو نموذج TTS العصبي غير الذاتي ، مما يتيح توليفًا أسرع مقارنةً بنماذج الانحدار الذاتي مثل Wavenet أثناء الاستدلال. يأخذ النموذج نصًا كمدخل ويتوقع ميزات صوتية طيفية باستخدام بنية ترميز تشفير المحولات. بدلاً من الملاحقات المتوسعة ، يتم استخدام إدراكي متعدد الطبقات (MLPs) مع المعالجة التلافيفية في بنية النموذج. هذا يوفر نمذجة الميزات المحلية. يتم دمج تنبؤات التباين الإضافية لنمذجة سمات الكلام مثل ملامح الملعب والمدة وملامح الطاقة. هذا يحسن الايجابي والطبيعية.
باختصار ، الجوانب الرئيسية هي:
- التوليف غير المتوازي غير المتوازي
- محول التشفير decoder
- طبقات MLP للسياق المحلي
- تنبؤات التباين تلتقط ملفات تعريف الكلام
يتيح ذلك Fastspech2 توليد طيف الميل العالي الجودة من النص بالتوازي أثناء الاستدلال مع الحفاظ على الخصائص الطبيعية والصوت.
| Fastspeech2 | 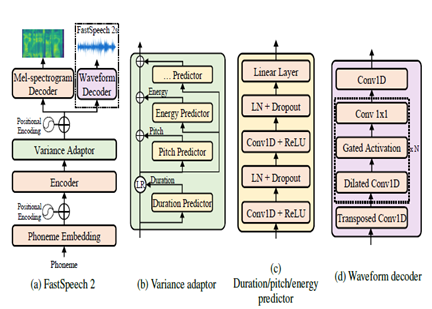 |
|---|
نتائج
بناءً على التقييمات الذاتية التي تم إجراؤها كجزء من عملية الاختبار ، كانت بعض المجالات الرئيسية المحددة لمزيد من التحسين في الترجمة وجودة الدبلجة:
- تزامن الشفاه: مزيد من العمل اللازم لضبط توقيت ومدة الكلام المدبلج بشكل جيد لمطابقة حركات الشفاه بشكل أفضل.
- التعبير: الاستيلاء على العاطفة والتركيز في الخطاب الأصلي من خلال التجويد المناسبين والاستمتاع في الخطاب المدبلج.
- الطلاقة: بعض غير طبيعي تم اكتشافه في الخطاب العربي المترجم من حيث سيولة الجمل.
- المصطلحات: تمثل المفردات الخاصة بالمجال تحديات ، وخاصة المصطلحات التقنية. انخفض الأداء للمجالات المتخصصة.
- تشابه المتحدث: بينما تم إنشاء نماذج مكبرات صوت متعددة ، يلزم إجراء مزيد من التخصيص لتقليد صوت المتحدث الأصلي بشكل أفضل.
- ضوضاء الخلفية: الحد من القطع الأثرية الخلفية وتحسين وضوح الصوت للحامول.
- القواعد: تحليل نحوي أفضل أثناء الترجمة اللازمة لإنتاج جمل عربية متماسكة تمامًا.
- الكلام الدليلي: التعامل مع اللغة غير الرسمية واللهجات واللهول العامية.
مراجع
- Alexei Baevski ، HZ-R. (2020). WAV2VEC 2.0: إطار للتعلم الخاضع للإشراف على تمثيلات الكلام. العصبية. ميتا.
- Anmol Gulati ، JQ-C. (2020). المطابقة: محول مقرّب في الالتفاف للتعرف على الكلام. العصبية.
- Ashish Vaswani ، NS (2017). الاهتمام هو كل ما تحتاجه. العصبية.
- Chenxu Hu1 ، QT (2021). Dubber العصبي: Dubbing لمقاطع الفيديو وفقًا للنصوص. العصبية.
- Marcello Federico ، RE-C. (2020). من ترجمة الكلام إلى الكلام إلى الدبلجة التلقائية. وقائع المؤتمر الدولي السابع عشر حول ترجمة اللغة المنطوقة (ص. 257-264). جمعية اللغويات الحسابية.
- نايجل ج. وارد ، جي (2022). يتم إعادة تفعيل الحوارات عبر اللغات. UTEP-CS-22-108.
- رونغ يي ، ميغاواط (2022). التعلم التباين عبر الوسائط لترجمة الكلام. naaCl.
- Wei-Gening HSU ، BB-H. (2021). هوبرت: تمثيل الكلام الخاضع للإشراف على التعلم من خلال التنبؤ المقنع للوحدات المخفية. Neupips (ص 10). ميتا.
- ييفان بينغ ، SD (2022). الفرع: بنية موازات MLP لتراجع MLP لالتقاط السياق المحلي والعالمي للتعرف على الكلام وفهمه. ICML.
- Yihan Wu ، JG (2023). VideOdubber: ترجمة آلية مع التحكم في طول الكلام للفيديو. aaai.
- مشروع كلام
- مجموعة أدوات Nemo من Nvidia
- luggingface
- مقالة المحول المصور
- المحول المشروح
- التدريب الذاتي والتدريب ، وفهم سلسلة WAV2VEC
- أوضح بيرت: نموذج اللغة الفنية لـ NLP


