英語からアラビア語への自動ビデオ吹き替えシステム
このプロジェクトでは、ビデオ吹き替えのテクニックと特殊なビデオ吹き替えシステムの開発に関する包括的な研究を提示します。目的は、外国語ビデオの元の声を、ターゲットオーディエンスの言語を話すパフォーマーの声に置き換えることでありながら、唇の動きと吹き替えのスピーチを確保することです。
自動ビデオダビングの重要性
ビデオダビングは、世界の文化全体でビデオコンテンツを不変にすることを目的としています。自動ビデオダビングシステムには、通常、3つのサブタスクが含まれます。
- 自動音声認識(ASR)は、元の音声をソース言語のテキストに転写します。
- ソース言語のテキストをターゲット言語に変換するニューラルマシン翻訳(NMT)。
- 翻訳されたテキストをターゲットスピーチに合成するテキストツースピーチ(TTS)。
ビデオダビングは、異文化コミュニケーションのための視覚的完全性を維持しながら、多言語コンテンツのアクセシビリティ、エンゲージメント、グローバルな分布を強化します。
課題
自動ビデオダビングはいくつかの課題に直面しています:
- リップシンクの精度
- 吹き替えの声の自然さ
- 文化的適応とローカライズ
- 多言語と多文化の考慮事項
- コードの切り替え。
方法論
提案された方法論には以下が含まれます。
- オーディオとビデオをソース英語ビデオから分離する
- スピーチ翻訳者を使用して、英語の音声をアラビア語のスピーチに翻訳する
- 元のビデオフレームを保存します
- 翻訳されたアラビア語のスピーチをビデオフレームとマージして、アラビア語の吹き替えビデオを作成します
結果を改善するために、音声翻訳者で2つの追加モデルが使用されます。
- 句読点を英語字幕に追加する句読点モデル
- アラビア語のテキストに異なるマークを追加するTashkeelモデル
| ダビングビデオのパイプライン | 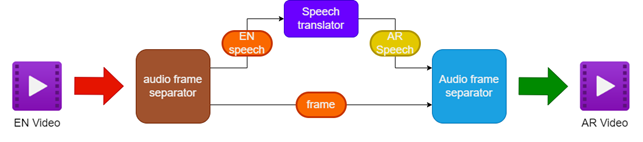 |
|---|
| 音声ターンスレーター | 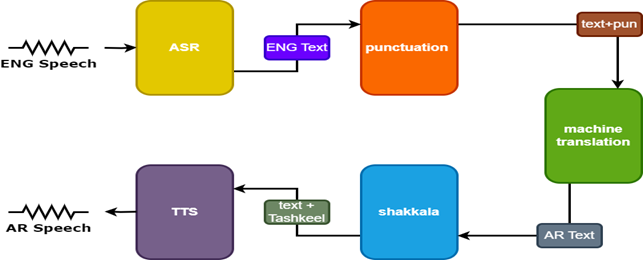 |
システムアーキテクチャ
システムは、次のようなモジュラーアーキテクチャに従います。
- ユーザーに対応するアプリ(フラッターアプリ)
- アプリケーションサーバー(LocalHostおよびHerouku)
- データベースサーバー(FireBase)
- ASR、NMT、TTS用の機械学習パイプライン(Pytorch、Tensorflow、Huggingface)
| システムメインコンポネット | 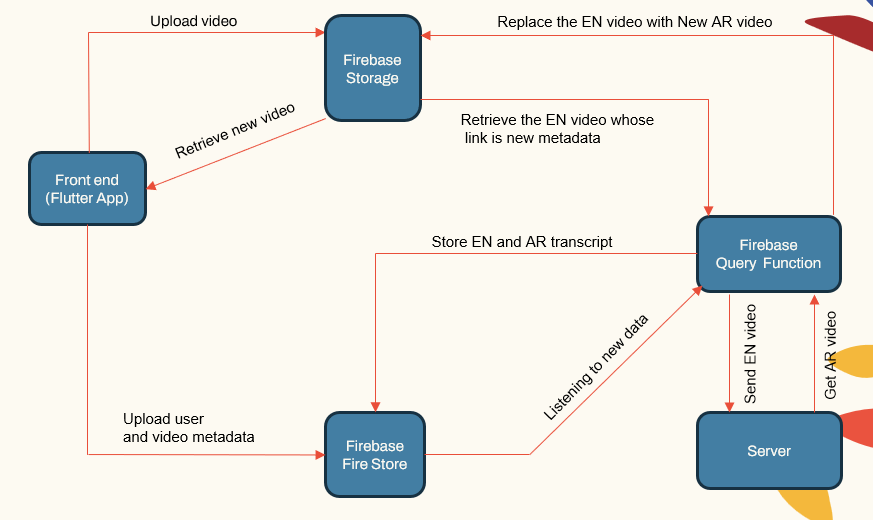 |
|---|
アプリケーションサーバーは、ユーザー管理、ビデオのアップロード/ダウンロード、およびMLパイプラインとのインターフェースを処理します。データベースは、ユーザーデータ、ビデオメタデータ、トランスクリプトなどを保存します。
音声認識
実験では、Wave2Vec2.0とGoogleの音声認識APIを比較しました。 wave2vec2.0は、小さなラベルの付いたデータセットで微調整された大規模なラベルのない音声データを事前に移動することにより、より低い単語エラー率を示しました。 CTC損失関数を使用して、音響機能をキャラクターの確率に変換するために音響モデルをトレーニングしました。
| CTCデコード付きWAVE2VEC2.0 | 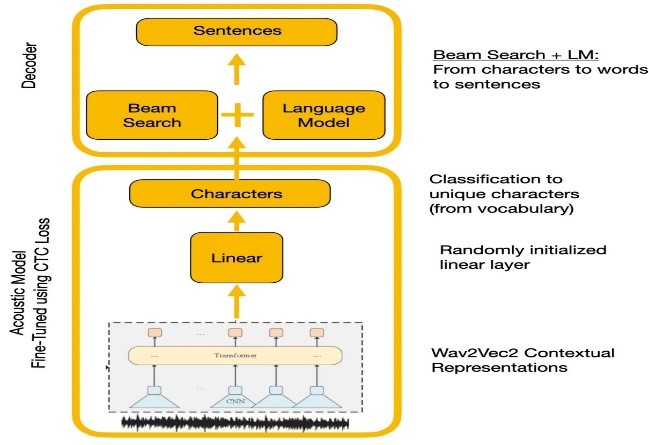 |
|---|
機械翻訳
GoogleのNMTアーキテクチャは、注意メカニズムを備えたLSTMレイヤーを利用しています。
- エンコーダLSTMは、ソーステキストをベクトル表現に変換します
- 注意モジュールは、各ターゲットワードにソース表現を調整します
- デコーダーLSTMは、コンテキストベクトルに基づいてターゲットワードを順番に予測します
重要な最適化には次のものがあります。
- 珍しい単語を処理するためにサブワードに単語をエンコードするバイトペアエンコード
- 勾配の流れを改善するための積み重ねられたLSTM層の残留接続
- エラーを減らし、最適な翻訳を見つけるためのビーム検索デコード
| MT用のエンコーダーデコーダー | 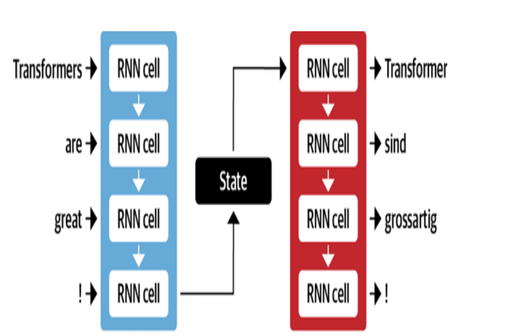 |
|---|
テキストからスピーチ
FastSpeech2は、非自動性神経TTSモデルであり、推論中のWavenetのような自己回帰モデルと比較してより速い合成を可能にします。このモデルは、テキストを入力として取得し、変圧器エンコーダーデコダーアーキテクチャを使用してメルスペクトルグラムのアコースティック機能を予測します。拡張畳み込みの代わりに、モデルアーキテクチャでは、畳み込み処理を伴う多層パーセプトロン(MLP)が使用されます。これにより、ローカル機能モデリングが提供されます。追加の分散予測子は、ピッチ、持続時間、エネルギープロファイルなどの音声属性をモデル化するために組み込まれています。これにより、韻律と自然さが向上します。
要約すると、重要な側面は次のとおりです。
- 非自動性並列合成
- トランスエンコーダーデコーダー
- ローカルコンテキスト用のMLPレイヤー
- 分散予測子は音声プロファイルをキャプチャします
これにより、FastSpeech2は、自然な韻律と音声の特性を維持しながら、推論中に並行してテキストから高品質のメルスペクトルグラムを生成できます。
| fastspeech2 | 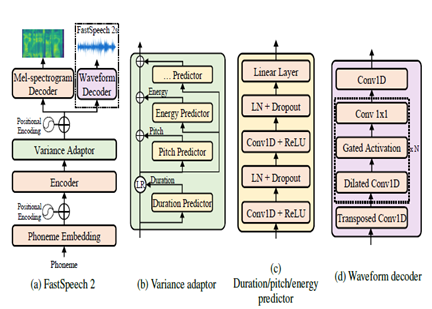 |
|---|
結果
テストプロセスの一部として行われた主観的評価に基づいて、翻訳と吹き替え品質のさらなる改善のために特定された重要な領域のいくつかは次のとおりです。
- リップの同期:リップの動きをよりよく合わせるために、吹き替えのスピーチのタイミングと期間を細かく調整するために必要な作業が必要です。
- 表現:吹き替えのスピーチにおける適切なイントネーションと韻律を通じて、元のスピーチの感情と強調を捉えます。
- 流ency:文の流動性の観点から、翻訳されたアラビア語のスピーチで検出された不自然さ。
- 用語:ドメイン固有の語彙が課題、特に技術的な専門用語でした。特殊なドメインのパフォーマンスは低下しました。
- スピーカーの類似性:複数のスピーカーモデルが作成されましたが、元のスピーカー音声をよりよく模倣するには、よりパーソナライズが必要です。
- バックグラウンドノイズ:バックグラウンドアーティファクトの削減と、吹き替えのスピーチのオーディオ透明度の改善。
- 文法:完全に一貫したアラビア語の文を作成するために必要な翻訳中のより良い文法分析。
- 方言のスピーチ:非公式の言語、方言、スラングの取り扱い。
参照
- Alexei Baevski、Hz-R。 (2020)。 WAV2VEC 2.0:音声表現の自己監視学習のためのフレームワーク。ニューリップ。メタ。
- Anmol Gulati、JQ-C。 (2020)。コンフォーマー:音声認識のための畳み込み熟成トランス。ニューリップ。
- Ashish Vaswani、NS(2017)。注意が必要です。ニューリップ。
- Chenxu Hu1、Qt(2021)。 Neural Dubber:スクリプトに従ってビデオのダビング。ニューリップ。
- Marcello Federico、re-c。 (2020)。音声への翻訳から自動吹き替えまで。第17回語言語翻訳に関する国際会議の議事録(pp。257–264)。計算言語学の協会。
- Nigel G. Ward、JE(2022)。言語間で再制定されたダイアログ。 UTEP-CS-22-108。
- Rong Ye、MW(2022)。音声翻訳のためのクロスモーダル対照学習。 Naacl。
- weining hsu、bb-h。 (2021)。 Hubert:隠されたユニットの仮面予測による自己教師の音声表現学習。ニューリップ(p。10)。メタ。
- Yifan Peng、SD(2022)。 Branchformer:音声認識と理解のためにローカルおよびグローバルなコンテキストをキャプチャするための並列MLPアテンションアーキテクチャ。 ICML。
- Yihan Wu、JG(2023)。 VideoDubber:ビデオ吹き替えのための音声認識の長さコントロールを備えた機械翻訳。 aaai。
- Klaamプロジェクト
- NvidiaのNemo Toolkit
- ハギングフェイス
- 図解された変圧器の記事
- 注釈付き変圧器
- 自己訓練とトレーニング前、WAV2VECシリーズの理解
- バート説明:NLPの最先端の言語モデル


