Automatisches Video -Synchronisierungssystem von Englisch bis Arabisch
Dieses Projekt präsentiert eine umfassende Studie zu Video -Synchronisationstechniken und der Entwicklung eines speziellen Video -Synchronisationssystems. Ziel ist es, die ursprünglichen Stimmen in Fremdsprachenvideos durch die Stimmen der Darsteller zu ersetzen, die die Sprache der Zielgruppe sprechen, und gleichzeitig die Synchronisation zwischen Lippenbewegungen und der synchronisierten Sprache sicherzustellen.
Bedeutung des automatischen Video -Synchronisierens
Video -Synchronisation zielt darauf ab, Videoinhalte in weltweiten Kulturen invariant zu machen. Automatische Video-Synchronisationssysteme umfassen in der Regel drei Unterbereitungen:
- Automatische Spracherkennung (ASR), die die ursprüngliche Sprache in den Text in der Quellsprache transkribiert.
- Neuronal Machine Translation (NMT), die den Quellsprachentext in die Zielsprache übersetzt.
- Text-to-Speech (TTS), das den übersetzten Text in die Zielrede synthetisiert.
Das Video-Synchronisation verbessert die Zugänglichkeit, das Engagement und die globale Verteilung mehrsprachiger Inhalte und erhalten gleichzeitig die visuelle Integrität für die interkulturelle Kommunikation.
Herausforderungen
Automatische Video -Synchronisation steht vor verschiedenen Herausforderungen:
- Genauigkeit der Lippensynchronisation
- Natürlichkeit der synchronisierten Stimme
- Kulturelle Anpassung und Lokalisierung
- Mehrsprachige und multikulturelle Überlegungen
- Codewechsel.
Methodik
Die vorgeschlagene Methodik umfasst:
- Trennende Audio und Video vom englischen Video -Video
- Übersetzen des englischen Audios in arabische Sprache mit einem Sprachübersetzer in die arabische Sprache
- Erhalt der Originalvideo -Rahmen
- Zusammenführen der übersetzten arabischen Sprache mit den Videorahmen, um ein arabisch synchronisiertes Video zu erstellen
Um die Ergebnisse zu verbessern, werden im Sprachübersetzer zwei zusätzliche Modelle verwendet:
- Interpunktionsmodell zum Hinzufügen von Interpunktion zu englischen Untertiteln
- Tashkeel -Modell, um arabischem Text diakritische Markierungen hinzuzufügen
| Pipeline zum Synchronisieren von Videos | 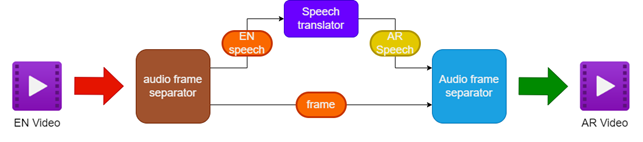 |
|---|
| Sprache Tarnslator | 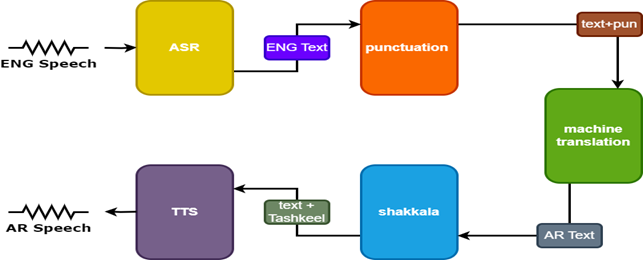 |
Systemarchitektur
Das System folgt einer modularen Architektur, die aus:
- Benutzer -Apps (Flutter App)
- Anwendungsserver (Localhost und Herouku)
- Datenbankserver (Firebase)
- Pipelines für maschinelles Lernen für ASR, NMT, TTS (Pytorch, Tensorflow und Huggingface)
| System Hauptkomponenten | 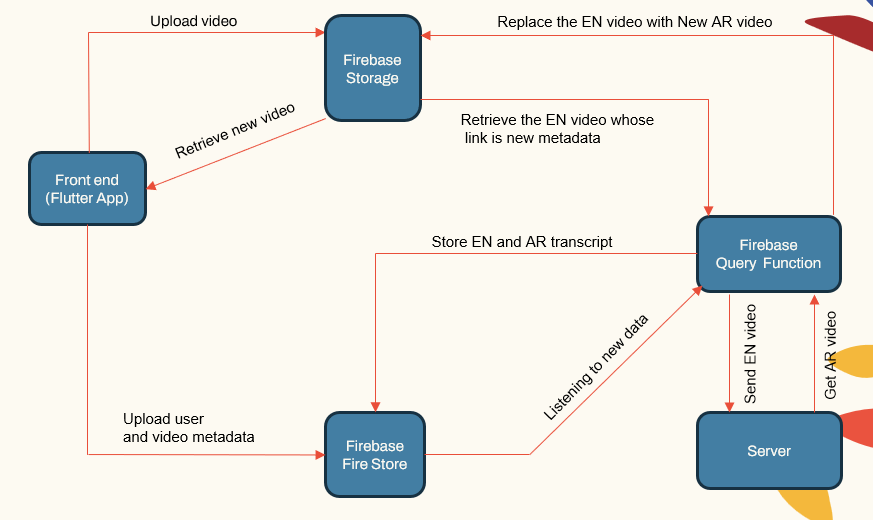 |
|---|
Der Anwendungsserver kümmert sich um Benutzerverwaltung, Video -Uploads/-downloads und Schnittstellen mit den ML -Pipelines. Die Datenbank speichert Benutzerdaten, Videometadaten, Transkripte usw.
Spracherkennung
Experimente verglichen Wave2VEC2.0 und Google Spracherkennungs -APIs. Wave2VEC2.0 ergab niedrigere Wortfehlerraten, indem große, unbezeichnete Sprachdaten gefolgt von Finetuning auf einem kleinen gekennzeichneten Datensatz gefolgt wurden. Die CTC -Verlustfunktion wurde verwendet, um das akustische Modell zu trainieren, um Sprachmerkmale in Zeichenwahrscheinlichkeiten umzuwandeln.
| Wave2VEC2.0 mit CTC -Dekodierung | 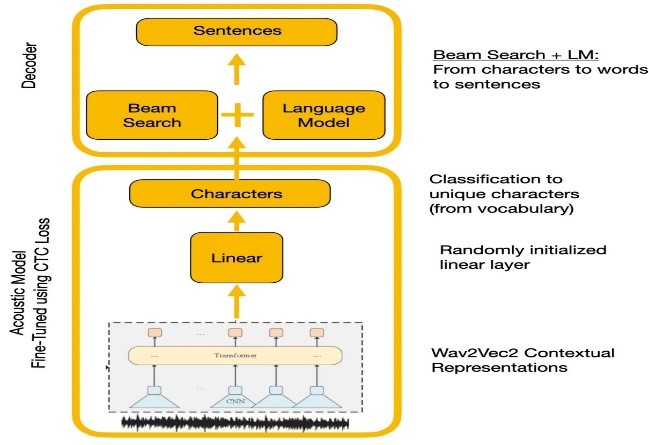 |
|---|
Maschinelle Übersetzung
Die NMT -Architektur von Google verwendet LSTM -Schichten mit Aufmerksamkeitsmechanismus:
- Encoder LSTM wandelt Quelltext in Vektordarstellungen um
- Das Aufmerksamkeitsmodul richtet Quellendarstellungen auf jedes Zielwort aus
- Decoder LSTM sagt Zielwörter nacheinander an, basierend auf Kontextvektoren
Zu den wichtigsten Optimierungen gehören:
- Byte-Pair-Codierung von Wörtern in Subwords, um seltene Wörter zu bewältigen
- Restverbindungen in gestapelten LSTM -Schichten zur Verbesserung des Gradientenflusss
- Strahlensuchdecodierung, um Fehler zu reduzieren und optimale Übersetzungen zu finden
| Encoder -Decoder für MT | 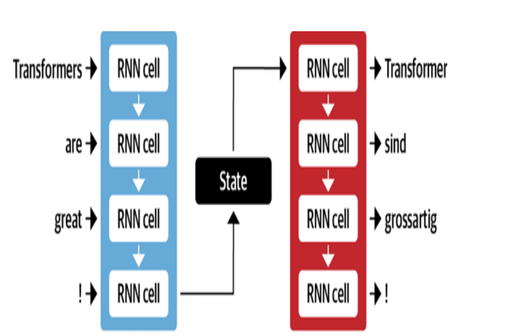 |
|---|
Text zur Sprache
Fastspeech2 ist ein nicht autoregressives TTS-Modell, das eine schnellere Synthese im Vergleich zu autoregressiven Modellen wie Wavenet während der Inferenz ermöglicht. Das Modell nimmt Text als Eingabe an und sagt melspektrogramm akustische Merkmale mithilfe einer Transformator-Encoder-Decoder-Architektur voraus. Anstelle von erweiterten Konvolutionen werden in der Modellarchitektur mehrschichtige Perzeptrons (MLPs) mit Faltungsverarbeitung verwendet. Dies bietet eine lokale Merkmalsmodellierung. Zusätzliche Varianz -Prädiktoren sind in Modell -Sprachattribute wie Tonhöhe, Dauer und Energieprofile integriert. Dies verbessert Prosodie und Natürlichkeit.
Zusammenfassend lässt sich sagen, dass die Schlüsselaspekte:
- Nicht autoregressive parallele Synthese
- Transformator-Encoder-Decoder
- MLP -Ebenen für den lokalen Kontext
- Varianzprädiktoren erfassen Sprachprofile
Dies ermöglicht Fastspeech2, qualitativ hochwertige Melspektrogramme aus Text parallel während der Inferenz zu erzeugen und gleichzeitig die natürlichen Prosodien- und Sprachmerkmale aufrechtzuerhalten.
| Fastspeech2 | 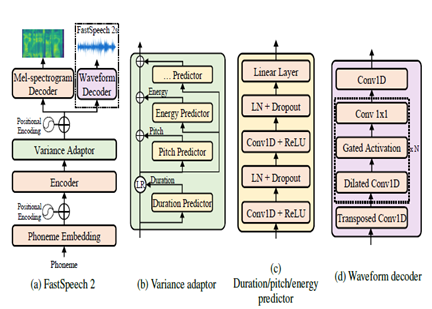 |
|---|
Ergebnisse
Basierend auf den subjektiven Bewertungen, die im Rahmen des Testprozesses durchgeführt wurden, waren einige der wichtigsten Bereiche, die zur weiteren Verbesserung der Übersetzung und der Synchronisation der Qualität identifiziert wurden,:
- Lippensynchronisation: Weitere Arbeiten, die erforderlich sind, um das Timing und die Dauer der synchronisierten Sprache fein einzustellen, um die Lippenbewegungen besser zu entsprechen.
- Ausdruck: Erfassen Sie die Emotionen und Betonung der ursprünglichen Sprache durch angemessene Intonation und Prosodie in der synchronisierten Sprache.
- Fluenz: In der übersetzten arabischen Sprache im Hinblick auf die Fließfähigkeit von Sätzen sind einige Unnatürlich festgelegt.
- Terminologie: Domänenspezifischer Vokabular stellte Herausforderungen, insbesondere technische Jargon. Die Leistung nahm bei spezialisierten Domänen ab.
- Lautsprecherähnlichkeit: Während mehrere Sprechermodelle erstellt wurden, ist mehr Personalisierung erforderlich, um die ursprüngliche Lautsprecherstimme besser nachzuahmen.
- Hintergrundrauschen: Reduzierung von Hintergrundartefakten und Verbesserung der Audioklarheit für die synchronisierte Sprache.
- Grammatik: Bessere grammatikalische Analyse während der Übersetzung, die zur Erzeugung perfekt kohärenter arabischer Sätze erforderlich ist.
- Dialektalrede: Informelle Sprache, Dialekte und Slang.
Referenzen
- Alexei Baevski, hz-r. (2020). WAV2VEC 2.0: Ein Rahmen für das selbstbewertete Erlernen von Sprachdarstellungen. Neurips. META.
- Anmol Gulati, JQ-C. (2020). Konformer: Faltungsverzinsungstransformator für die Spracherkennung. Neurips.
- Ashish Vaswani, NS (2017). Aufmerksamkeit ist alles, was Sie brauchen. Neurips.
- Chenxu Hu1, QT (2021). Neural Dubber: Synchronisieren von Videos nach Skripten. Neurips.
- Marcello Federico, Re-C. (2020). Von der Sprache zu Sprachübersetzung bis hin zur automatischen Synchronisation. Proceedings der 17. Internationalen Konferenz über die Übersetzung gesprochener Sprache (S. 257–264). Assoziation für Computer -Linguistik.
- Nigel G. Ward, JE (2022). Dialoge über Sprachen übernommen. UTEP-CS-22-108.
- Rong Ye, MW (2022). Kreuzmodales kontrastives Lernen für Sprachübersetzung. Naacl.
- Weii-nun Hsu, BB-H. (2021). Hubert: Lernen von selbstversorgunger Sprachrepräsentationen durch maskierte Vorhersage versteckter Einheiten. Neurips (S. 10). META.
- Yifan Peng, SD (2022). Branchformer: Parallele MLP-Begleitarchitekturen, um den lokalen und globalen Kontext für Spracherkennung und -verständnis zu erfassen. ICML.
- Yihan Wu, JG (2023). Videodubber: Maschinelle Übersetzung mit sprachbewusster Längensteuerung für Video-Synchronisation. Aaai.
- Klaam -Projekt
- Nemo -Toolkit aus Nvidia
- Umarmung
- Der illustrierte Transformator -Artikel
- Der kommentierte Transformator
- Selbsttraining und Vorabbildung, Verständnis der WAV2VEC-Serie
- Bert erklärte: hochmodernes Sprachmodell für NLP


