Sistema automático de dublagem de vídeo do inglês para o árabe
Este projeto apresenta um estudo abrangente sobre técnicas de dublagem de vídeo e o desenvolvimento de um sistema especializado de dublagem de vídeo. O objetivo é substituir as vozes originais em vídeos de idiomas estrangeiros com as vozes dos artistas falando o idioma do público -alvo, garantindo a sincronização entre os movimentos labiais e o discurso chamado.
Importância da dublagem de vídeo automático
A dublagem de vídeo tem como objetivo tornar o conteúdo de vídeo invariável em culturas mundiais. Os sistemas automáticos de dublagem de vídeo geralmente envolvem três subtarefas:
- Reconhecimento automático de fala (ASR), que transcreve o discurso original para o texto no idioma de origem.
- Tradução da máquina neural (NMT), que traduz o texto da linguagem de origem para o idioma de destino.
- Texto-fala (TTS), que sintetiza o texto traduzido para a fala de destino.
A dublagem de vídeo aprimora a acessibilidade, o engajamento e a distribuição global do conteúdo multilíngue, preservando a integridade visual para a comunicação transcultural.
Desafios
A dublagem de vídeo automática enfrenta vários desafios:
- Precisão da sincronização labial
- Naturalidade da voz dublada
- Adaptação e localização cultural
- Considerações multilíngues e multiculturais
- Comutação de código.
Metodologia
A metodologia proposta envolve:
- Separando o áudio e o vídeo do vídeo em inglês de origem
- Traduzindo o áudio inglês para o discurso árabe usando um tradutor de fala
- Preservando os quadros de vídeo originais
- Fusão do discurso árabe traduzido com os quadros de vídeo para criar um vídeo dublado em árabe
Para melhorar os resultados, dois modelos adicionais são usados no tradutor de fala:
- Modelo de pontuação para adicionar pontuação às legendas em inglês
- Modelo Tashkeel para adicionar marcas diacríticas ao texto em árabe
| Oleoduto para dublagem de vídeo | 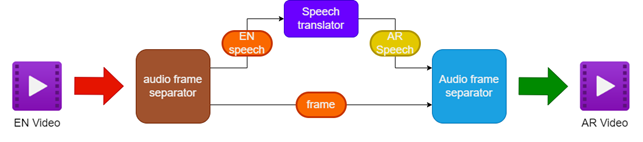 |
|---|
| Tarnslator de fala | 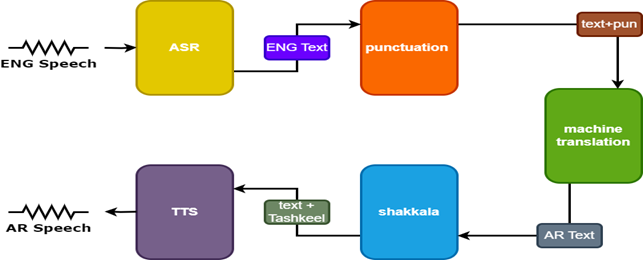 |
Arquitetura do sistema
O sistema segue uma arquitetura modular que consiste em:
- Aplicativos voltados para o usuário (aplicativo Flutter)
- Servidor de aplicativos (localhost e herouku)
- Servidor de banco de dados (Firebase)
- Dipelines de aprendizado de máquina para ASR, NMT, TTS (Pytorch, Tensorflow e Huggingface)
| Sistema Principal Comtonenet | 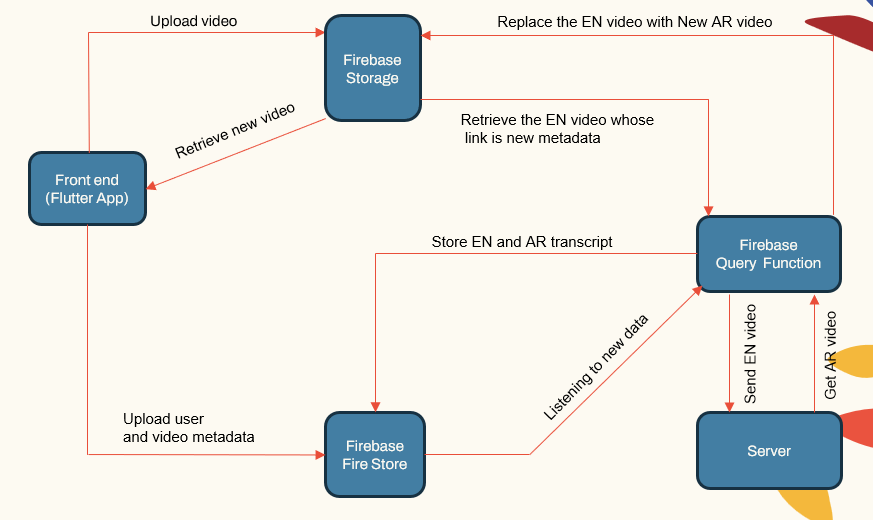 |
|---|
O servidor de aplicativos lida com gerenciamento de usuários, uploads/downloads de vídeo e interface com os pipelines ML. O banco de dados armazena dados do usuário, metadados de vídeo, transcrições, etc.
Reconhecimento de fala
Experimentos compararam as APIs WAVE2VEC2.0 e Google Reconhecimento de fala. Wave2vec2.0 forneceu taxas de erro de palavras mais baixas por pré -treinamento em grandes dados de fala não marcados, seguidos de finetuning em um pequeno conjunto de dados rotulado. A função de perda de CTC foi usada para treinar o modelo acústico para converter recursos de fala em probabilidades de caracteres.
| Wave2vec2.0 com decodificação de CTC | 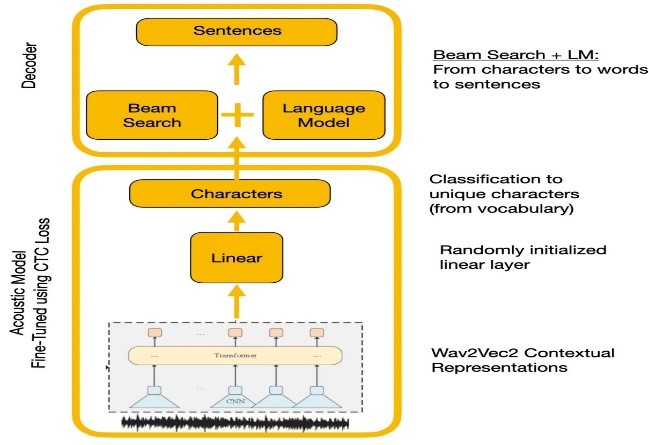 |
|---|
Tradução da máquina
A arquitetura NMT do Google utiliza camadas LSTM com mecanismo de atenção:
- Encoder LSTM converte texto de origem em representações vetoriais
- Módulo de atenção alinha representações de origem a cada palavra de destino
- O decodificador LSTM prevê palavras -alvo sequencialmente com base em vetores de contexto
As principais otimizações incluem:
- Codificação de byte par de palavras em subpainhas para lidar com palavras raras
- Conexões residuais em camadas LSTM empilhadas para melhorar o fluxo de gradiente
- Decodificação de pesquisa de feixe para reduzir erros e encontrar traduções ideais
| Decodificador do codificador para MT | 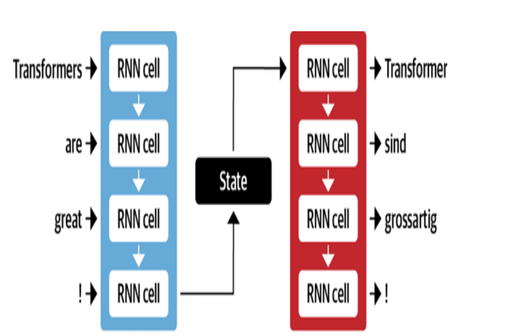 |
|---|
Texto para fala
O FastSpeech2 é um modelo TTS neural não autorregressivo, permitindo uma síntese mais rápida em comparação com modelos autoregressivos como WaveNet durante a inferência. O modelo toma o texto como entrada e prevê recursos acústicos de espectro do espectro MEL usando uma arquitetura do codificador de transformador. Em vez de convoluções dilatadas, os perceptrons de várias camadas (MLPs) com processamento convolucional são usados na arquitetura do modelo. Isso fornece modelagem de recursos locais. Preditores adicionais de variação são incorporados para modelar atributos de fala, como perfis de pitch, duração e energia. Isso melhora a prosódia e a naturalidade.
Em resumo, os principais aspectos são:
- Síntese paralela não autorregressiva
- Codificador do transformador decodificador
- Camadas MLP para contexto local
- Preditores de variação capturam perfis de fala
Isso permite que o FastSpeech2 gere espectrogramas MEL de alta qualidade a partir do texto em paralelo durante a inferência, mantendo as características de prosódia natural e voz.
| FastSpeech2 | 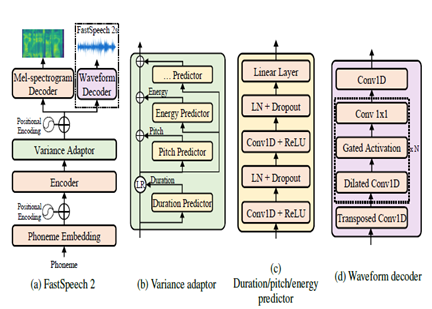 |
|---|
Resultados
Com base nas avaliações subjetivas realizadas como parte do processo de teste, algumas das principais áreas identificadas para melhorias na tradução e na qualidade da dublagem foram:
- Sincronização labial: mais trabalho necessário para ajustar finamente o tempo e a duração da fala dublada para combinar melhor os movimentos labiais.
- Expressão: captura a emoção e ênfase no discurso original através de entonação e prosódia apropriadas no discurso chamado.
- Fluência: Alguma não natura detectada no discurso árabe traduzido em termos de fluidez das sentenças.
- Terminologia: O vocabulário específico do domínio apresentou desafios, especialmente o jargão técnico. O desempenho diminuiu para domínios especializados.
- Similaridade do alto -falante: Embora vários modelos de alto -falantes tenham sido criados, é necessária mais personalização para imitar melhor a voz original do alto -falante.
- Ruído de fundo: redução de artefatos de fundo e melhoria da clareza de áudio para o discurso chamado.
- Gramática: Melhor análise gramatical durante a tradução necessária para produzir sentenças árabes perfeitamente coerentes.
- Fala dialectal: lidando com linguagem informal, dialetos e gírias.
Referências
- Alexei Baevski, Hz-R. (2020). WAV2VEC 2.0: Uma estrutura para o aprendizado auto-supervisionado das representações de fala. Neurips. Meta.
- Anmol Gulati, JQ-C. (2020). Conformador: Transformador agitado por convolução para reconhecimento de fala. Neurips.
- Ashish Vaswani, NS (2017). Atenção é tudo o que você precisa. Neurips.
- Chenxu Hu1, Qt (2021). Dubber neural: dublagem para vídeos de acordo com scripts. Neurips.
- Marcello Federico, Re-C. (2020). Da tradução de fala para fala para dublagem automática. Anais da 17ª Conferência Internacional sobre Tradução de Língua Falada (pp. 257–264). Associação para Linguística Computacional.
- Nigel G. Ward, JE (2022). Diálogos reencenados entre os idiomas. UTEP-CS-22-108.
- Rong Ye, MW (2022). Aprendizagem contrastiva cruzada para tradução da fala. Naacl.
- WEI-NING HSU, BB-H. (2021). Hubert: Aprendizagem de representação de fala auto-supervisionada por previsão mascarada de unidades ocultas. Neurips (p. 10). Meta.
- Yifan Peng, SD (2022). Filial de filial: Arquiteturas paralelas de atendimento ao MLP para capturar o contexto local e global para reconhecimento e compreensão da fala. ICML.
- Yihan Wu, JG (2023). Videodubber: Tradução da máquina com controle de comprimento da fala para dublagem de vídeo. Aaai.
- Projeto Klaam
- Nemo Toolkit da NVIDIA
- huggingface
- O artigo do transformador ilustrado
- O transformador anotado
- Auto-treinamento e pré-treinamento, compreendendo a série WAV2VEC
- Bert explicou: Modelo de idioma de última geração para PNL


