Sistem dubbing video otomatis dari bahasa Inggris ke bahasa Arab
Proyek ini menyajikan studi komprehensif tentang teknik dubbing video dan pengembangan sistem pelepasan video khusus. Tujuannya adalah untuk menggantikan suara asli dalam video bahasa asing dengan suara -suara pemain yang berbicara bahasa audiens target, sambil memastikan sinkronisasi antara gerakan bibir dan pidato yang dijuluki.
Pentingnya Dubbing Video Otomatis
Dubbing video bertujuan untuk membuat konten video invarian di seluruh budaya di seluruh dunia. Sistem dubbing video otomatis biasanya melibatkan tiga sub-tugas:
- Pengenalan Pidato Otomatis (ASR), yang menyalin pidato asli ke dalam teks dalam bahasa sumber.
- Neural Machine Translation (NMT), yang menerjemahkan teks bahasa sumber ke bahasa target.
- Text-to-speech (TTS), yang mensintesis teks yang diterjemahkan ke dalam pidato target.
Dubbing video meningkatkan aksesibilitas, keterlibatan, dan distribusi global konten multibahasa sambil menjaga integritas visual untuk komunikasi lintas budaya.
Tantangan
Dubbing video otomatis menghadapi beberapa tantangan:
- Akurasi sinkronisasi bibir
- Kealamian suara yang dijuluki
- Adaptasi budaya dan lokalisasi
- Pertimbangan multibahasa dan multikultural
- Switching kode.
Metodologi
Metodologi yang diusulkan melibatkan:
- Memisahkan audio dan video dari sumber video bahasa Inggris
- Menerjemahkan audio bahasa Inggris ke pidato bahasa Arab menggunakan penerjemah ucapan
- Melestarikan bingkai video asli
- Menggabungkan pidato bahasa Arab yang diterjemahkan dengan bingkai video untuk membuat video yang dijuluki bahasa Arab
Untuk meningkatkan hasilnya, dua model tambahan digunakan dalam penerjemah wicara:
- Model tanda baca untuk menambahkan tanda baca pada subtitle bahasa Inggris
- Model Tashkeel untuk menambahkan tanda diakritik ke teks Arab
| Pipa untuk Dubbing Video | 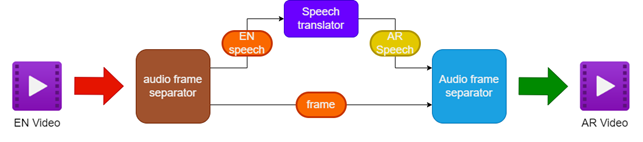 |
|---|
| Pidato Tarnslator | 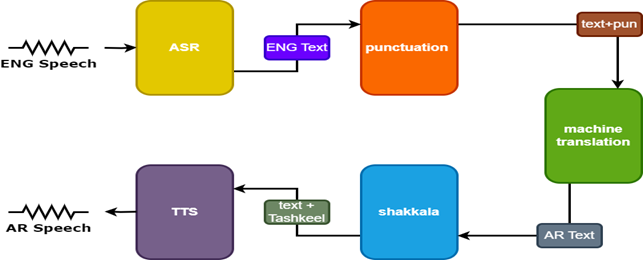 |
Arsitektur Sistem
Sistem ini mengikuti arsitektur modular yang terdiri dari:
- Aplikasi yang Menghadapi Pengguna (Aplikasi Flutter)
- Server Aplikasi (LocalHost dan Herouku)
- Server Database (Firebase)
- Jalur pipa pembelajaran mesin untuk ASR, NMT, TTS (Pytorch, Tensorflow dan Huggingface)
| Sistem Main ComponeNet | 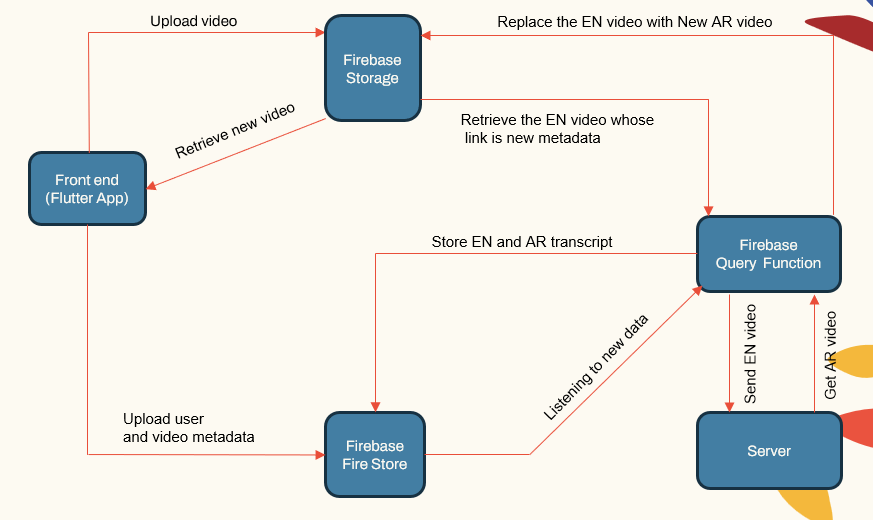 |
|---|
Server aplikasi menangani manajemen pengguna, unggahan video/unduhan, dan berinteraksi dengan pipa ML. Basis data menyimpan data pengguna, metadata video, transkrip, dll.
Pengakuan ucapan
Eksperimen membandingkan API WAVE2VEC2.0 dan Google Ecanan. WAVE2VEC2.0 memberikan tingkat kesalahan kata yang lebih rendah dengan pretraining pada data ucapan besar yang tidak berlabel diikuti dengan finetuning pada dataset berlabel kecil. Fungsi kerugian CTC digunakan untuk melatih model akustik untuk mengubah fitur ucapan menjadi probabilitas karakter.
| WAVE2VEC2.0 dengan decoding CTC | 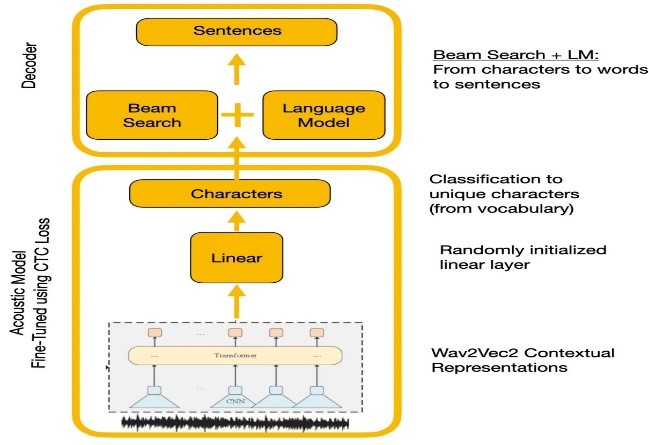 |
|---|
Terjemahan mesin
Arsitektur NMT Google menggunakan lapisan LSTM dengan mekanisme perhatian:
- Encoder LSTM mengubah teks sumber menjadi representasi vektor
- Modul perhatian menyelaraskan representasi sumber ke setiap kata target
- Decoder LSTM memprediksi kata target secara berurutan berdasarkan vektor konteks
Optimalisasi utama meliputi:
- Pengkodean kata-kata byte ke subwords untuk menangani kata-kata langka
- Koneksi residual dalam lapisan LSTM bertumpuk untuk meningkatkan aliran gradien
- Decoding pencarian balok untuk mengurangi kesalahan dan menemukan terjemahan yang optimal
| Encoder Decoder untuk MT | 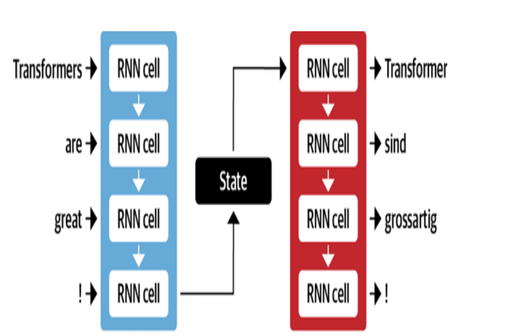 |
|---|
Teks untuk berbicara
FastSpeech2 adalah model TTS neural non-autoregresif, memungkinkan sintesis yang lebih cepat dibandingkan dengan model autoregresif seperti WaveNet selama inferensi. Model ini mengambil teks sebagai input dan memprediksi fitur akustik Mel-Spectrogram menggunakan arsitektur encoder-decoder transformer. Alih-alih konvolusi yang melebar, multi-layer perceptrons (MLP) dengan pemrosesan konvolusional digunakan dalam arsitektur model. Ini menyediakan pemodelan fitur lokal. Prediktor varians tambahan dimasukkan ke model atribut ucapan seperti pitch, durasi dan profil energi. Ini meningkatkan prosodi dan kealamian.
Singkatnya, aspek kuncinya adalah:
- Sintesis paralel non-otegresif
- Transformer Encoder-Decoder
- Lapisan MLP untuk konteks lokal
- Prediktor varians menangkap profil ucapan
Hal ini memungkinkan FastSpeech2 untuk menghasilkan spektrogram Mel berkualitas tinggi dari teks secara paralel selama inferensi sambil mempertahankan karakteristik prosodi dan suara alami.
| Fastspeech2 | 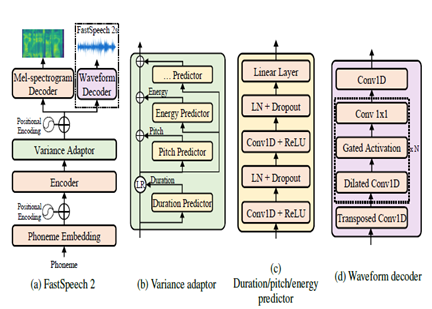 |
|---|
Hasil
Berdasarkan evaluasi subyektif yang dilakukan sebagai bagian dari proses pengujian, beberapa bidang utama yang diidentifikasi untuk peningkatan lebih lanjut dalam terjemahan dan kualitas dubbing adalah:
- Sinkronisasi bibir: Lebih banyak pekerjaan yang diperlukan untuk menyetel waktu dan durasi pidato yang dijuluki dengan baik untuk lebih cocok dengan gerakan bibir.
- Ekspresi: Menangkap emosi dan penekanan dalam pidato asli melalui intonasi dan prosodi yang tepat dalam pidato yang dijuluki.
- Kelancaran: Beberapa tidak wajar yang terdeteksi dalam pidato Arab yang diterjemahkan dalam hal kelancaran kalimat.
- Terminologi: Kosakata khusus domain menimbulkan tantangan, terutama jargon teknis. Kinerja menurun untuk domain khusus.
- Kesamaan pembicara: Sementara beberapa model pembicara dibuat, lebih banyak personalisasi diperlukan untuk lebih meniru suara speaker asli.
- Latar belakang kebisingan: Pengurangan artefak latar belakang dan peningkatan kejelasan audio untuk pidato yang dijuluki.
- Tata bahasa: Analisis tata bahasa yang lebih baik selama terjemahan yang diperlukan untuk menghasilkan kalimat -kalimat Arab yang koheren sempurna.
- Pidato dialek: Menangani bahasa informal, dialek, dan bahasa gaul.
Referensi
- Alexei Baevski, HZ-R. (2020). WAV2VEC 2.0: Kerangka kerja untuk pembelajaran representasi pidato yang diawasi sendiri. Neurips. Meta.
- Anmol Gulati, JQ-C. (2020). Conformer: Transformator Augmented Convolution untuk pengenalan suara. Neurips.
- Ashish Vaswani, NS (2017). Perhatian adalah semua yang Anda butuhkan. Neurips.
- Chenxu Hu1, Qt (2021). Dubber Neural: Dubbing untuk video menurut skrip. Neurips.
- Marcello Federico, Re-C. (2020). Dari terjemahan ucapan-ke-speech ke dubbing otomatis. Prosiding Konferensi Internasional ke -17 tentang Terjemahan Bahasa Lisan (hlm. 257–264). Asosiasi Linguistik Komputasi.
- Nigel G. Ward, JE (2022). Dialog diperkuat kembali di seluruh bahasa. UTEP-CS-22-108.
- Rong Ye, MW (2022). Pembelajaran kontras lintas modal untuk terjemahan bicara. Naacl.
- Wei-Ning Hsu, BB-H. (2021). Hubert: Pembelajaran representasi pidato yang di-swadaya dengan prediksi bertopeng unit tersembunyi. Neurips (hlm. 10). Meta.
- Yifan Peng, SD (2022). Cabang: Arsitektur MLP-perhatian paralel untuk menangkap konteks lokal dan global untuk pengakuan dan pemahaman suara. ICML.
- Yihan Wu, JG (2023). VideOdubber: Terjemahan mesin dengan kontrol panjang yang sadar ucapan untuk dubbing video. Aaai.
- Proyek Klaam
- Nemo Toolkit dari NVIDIA
- Huggingface
- Artikel Transformer Illustrated
- Transformator beranotasi
- Pelatihan dan pra-pelatihan, memahami seri WAV2VEC
- Bert Dijelaskan: Model Bahasa Canggih untuk NLP


