Sistema automático de doblaje de video del inglés al árabe
Este proyecto presenta un estudio exhaustivo sobre técnicas de doblaje de video y el desarrollo de un sistema de doblaje de video especializado. El objetivo es reemplazar las voces originales en videos de idiomas extranjeros con las voces de los artistas que hablan el lenguaje del público objetivo, al tiempo que garantizan la sincronización entre los movimientos de los labios y el discurso doblado.
Importancia del doblaje automático de video
Video Dubbing tiene como objetivo hacer que el contenido de video sea invariante en las culturas mundiales. Los sistemas automáticos de doblaje de videos generalmente involucran tres subtareas:
- Reconocimiento de voz automático (ASR), que transcribe el discurso original al texto en el lenguaje de origen.
- Traducción de la máquina neural (NMT), que traduce el texto del lenguaje de origen al idioma de destino.
- Texto a voz (TTS), que sintetiza el texto traducido al discurso objetivo.
El doblaje de video mejora la accesibilidad, la participación y la distribución global del contenido multilingüe al tiempo que preserva la integridad visual para la comunicación intercultural.
Desafíos
El doblaje automático de video enfrenta varios desafíos:
- Precisión de sincronización de labios
- Naturalidad de la voz doblada
- Adaptación cultural y localización
- Consideraciones multilingües y multiculturales
- Cambio de código.
Metodología
La metodología propuesta implica:
- Separar el audio y el video del video de origen inglés
- Traducir el audio en inglés al discurso árabe usando un traductor de discursos
- Preservar los marcos de video originales
- Fusionando el discurso árabe traducido con los marcos de video para crear un video de doblaje en árabe
Para mejorar los resultados, se utilizan dos modelos adicionales en el traductor del habla:
- Modelo de puntuación para agregar puntuación a los subtítulos en inglés
- Modelo de tashkeel para agregar marcas diacríticas al texto árabe
| Tubería para el video de doblaje | 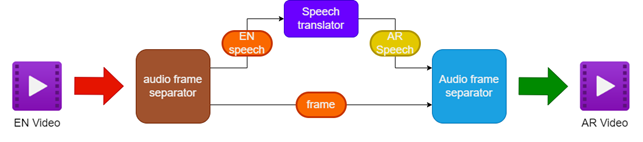 |
|---|
| Tarnslator del habla | 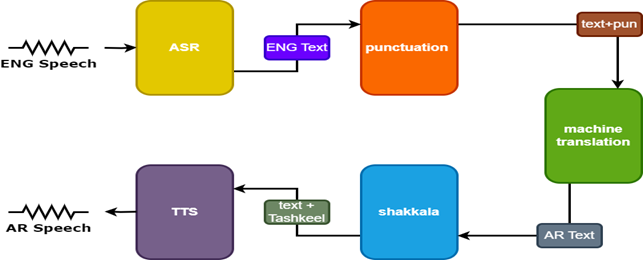 |
Arquitectura del sistema
El sistema sigue una arquitectura modular que consiste en:
- Aplicaciones que enfrentan el usuario (aplicación Flutter)
- Servidor de aplicaciones (Localhost e Herouku)
- Servidor de base de datos (Firebase)
- Tuberías de aprendizaje automático para ASR, NMT, TTS (Pytorch, TensorFlow y Huggingface)
| Componente principal del sistema | 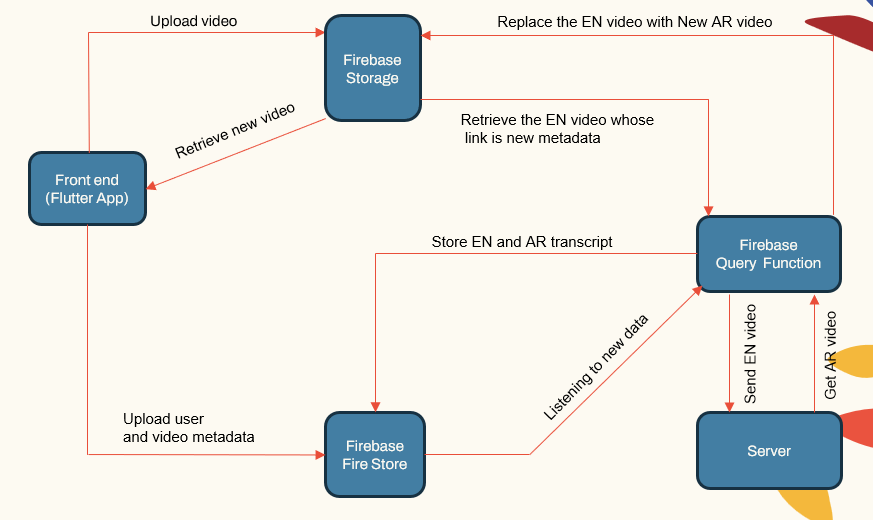 |
|---|
El servidor de aplicaciones maneja la administración de usuarios, las cargas/descargas de video e interfaz con las tuberías ML. La base de datos almacena datos de usuario, metadatos de video, transcripciones, etc.
Reconocimiento de voz
Los experimentos compararon Wave2Vec2.0 y las API de reconocimiento de voz de Google. Wave2VEC2.0 dio tasas de error de palabras más bajas al realizar previamente los datos del habla no etiquetados grandes seguidos de la sintonización de finet en un pequeño conjunto de datos etiquetado. La función de pérdida de CTC se utilizó para entrenar el modelo acústico para convertir las características del habla en probabilidades de caracteres.
| Wave2vec2.0 con decodificación de CTC | 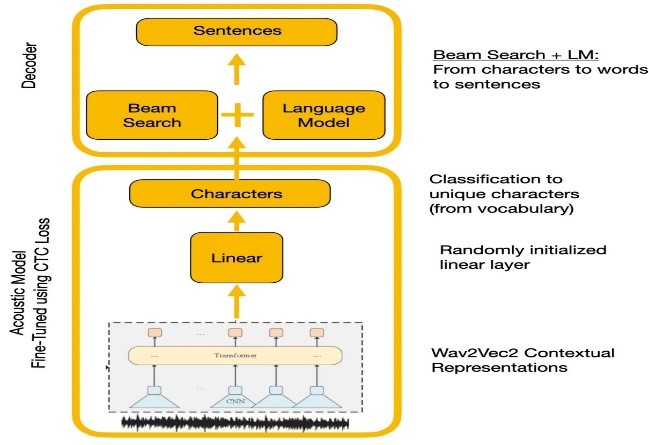 |
|---|
Traducción automática
La arquitectura NMT de Google utiliza capas LSTM con mecanismo de atención:
- El codificador LSTM convierte el texto fuente en representaciones vectoriales
- El módulo de atención alinea las representaciones de origen a cada palabra de destino
- Decoder LSTM predice palabras objetivo basadas secuencialmente en vectores de contexto
Las optimizaciones clave incluyen:
- Byte-Pair Codificación de palabras en subvenciones para manejar palabras raras
- Conexiones residuales en capas LSTM apiladas para mejorar el flujo de gradiente
- Decodificación de búsqueda de haz para reducir los errores y encontrar traducciones óptimas
| Decodificador de codificadores para MT | 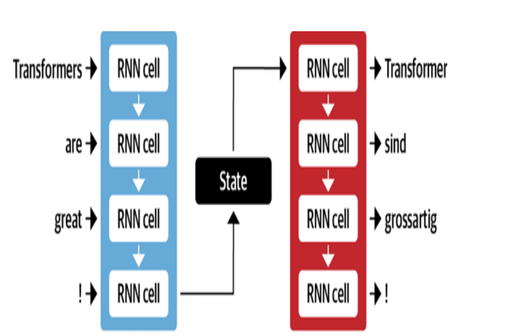 |
|---|
Texto a discurso
FastSpeech2 es un modelo TTS neural no autorgresivo, que permite una síntesis más rápida en comparación con modelos autorregresivos como Wavenet durante la inferencia. El modelo toma el texto como entrada y predice las características acústicas del espectrograma MEL utilizando una arquitectura de codificador del codificador del transformador. En lugar de convoluciones dilatadas, se utilizan perceptrones de múltiples capas (MLP) con procesamiento convolucional en la arquitectura del modelo. Esto proporciona modelos de características locales. Se incorporan predictores de varianza adicional para modelar atributos del habla como perfiles de tono, duración y energía. Esto mejora la prosodia y la naturalidad.
En resumen, los aspectos clave son:
- Síntesis paralela no autorgresiva
- Transformador codificador
- Capas de MLP para contexto local
- Los predictores de varianza capturan perfiles de habla
Esto permite que FastSpeech2 genere espectrogramas MEL de alta calidad del texto en paralelo durante la inferencia mientras mantiene las características de la prosodia y la voz naturales.
| FastSpeech2 | 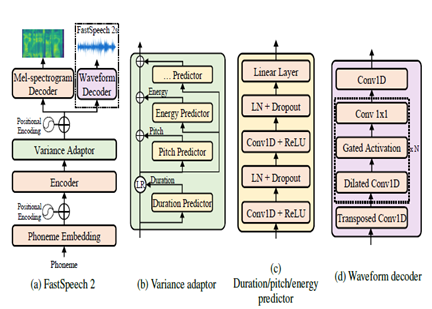 |
|---|
Resultados
Basado en las evaluaciones subjetivas realizadas como parte del proceso de prueba, algunas de las áreas clave identificadas para una mayor mejora en la traducción y la calidad del doblaje fueron:
- Sincronización de labios: se necesita más trabajo para sintonizar finamente el tiempo y la duración del discurso doblado para combinar mejor los movimientos de los labios.
- Expresión: capturar la emoción y el énfasis en el discurso original a través de la entonación y la prosodia apropiadas en el discurso doblado.
- Fluidez: cierta antinatural detectada en el discurso árabe traducido en términos de fluidez de las oraciones.
- Terminología: el vocabulario específico del dominio planteó desafíos, especialmente la jerga técnica. El rendimiento disminuyó para dominios especializados.
- Similitud del altavoz: si bien se crearon múltiples modelos de altavoces, se requiere más personalización para imitar mejor la voz original del altavoz.
- Ruido de fondo: reducción de artefactos de fondo y mejora de la claridad de audio para el discurso doblado.
- Gramática: mejor análisis gramatical durante la traducción requerida para producir oraciones árabes perfectamente coherentes.
- Discurso dialectal: manejo de lenguaje informal, dialectos y jerga.
Referencias
- Alexei Baevski, Hz-R. (2020). WAV2VEC 2.0: Un marco para el aprendizaje auto-supervisado de las representaciones del habla. Neuripas. META.
- Anmol Gulati, JQ-C. (2020). Conformador: Transformador acuático de convolución para el reconocimiento de voz. Neuripas.
- Ashish Vaswani, NS (2017). La atención es todo lo que necesitas. Neuripas.
- Chenxu Hu1, Qt (2021). Dubber neural: doblaje para videos según los guiones. Neuripas.
- Marcello Federico, RE-C. (2020). Desde la traducción de voz a la voz hasta el doblaje automático. Actas de la 17ª Conferencia Internacional sobre Traducción de Lenguajes hablados (pp. 257–264). Asociación de Lingüística Computacional.
- Nigel G. Ward, JE (2022). Los diálogos recrearon en todos los idiomas. UTEP-CS-22-108.
- Rong Ye, MW (2022). Aprendizaje contrastante intermodal para la traducción del habla. Naacl.
- Wei -ning Hsu, BB-H. (2021). Hubert: aprendizaje de la representación del habla auto-supervisada mediante la predicción enmascarada de las unidades ocultas. Neurips (p. 10). META.
- Yifan Peng, SD (2022). Branchformer: arquitecturas de atención MLP paralela para capturar el contexto local y global para el reconocimiento y la comprensión del habla. ICML.
- Yihan Wu, JG (2023). VideoDubber: traducción automática con control de longitud consciente del habla para el doblaje de video. Aaai.
- Proyecto Klaam
- Nemo Toolkit de Nvidia
- cara de abrazo
- El artículo ilustrado del transformador
- El transformador anotado
- Autodenrayamiento y pretruento, comprensión de la serie WAV2VEC
- Bert explicado: Modelo de lenguaje de última generación para la PNL


