Автоматическая система видеоподавления от английского до арабского языка
В этом проекте представлено всестороннее исследование по методам видеоизоля и разработке специализированной видео -системы. Цель состоит в том, чтобы заменить оригинальные голоса в видео на иностранном языке голосами исполнителей, говорящих на языке целевой аудитории, обеспечивая при этом синхронизацию между движениями губ и дублированной речью.
Важность автоматического видео
Видео -дублирование направлено на то, чтобы сделать видеоконтент инвариантным во всемирных культурах. Автоматические системы видеоролики обычно включают три подзадачи:
- Автоматическое распознавание речи (ASR), которое транскрибирует исходную речь в текст на исходном языке.
- Нейронная машина перевод (NMT), который переводит текст исходного языка на целевой язык.
- Текст-речь (TTS), который синтезирует переведенный текст в целевую речь.
Video Dubbing повышает доступность, вовлечение и глобальное распространение многоязычного контента, сохраняя при этом визуальную целостность для межкультурной коммуникации.
Проблемы
Автоматическое видео, дабирующее, сталкивается с несколькими проблемами:
- Точность синхронизации губ
- Естественность дублированного голоса
- Культурная адаптация и локализация
- Многоязычные и многокультурные соображения
- Переключение кода.
Методология
Предлагаемая методология включает в себя:
- Отделение аудио и видео от исходного английского видео
- Перевод английского звука на арабский речь с использованием переводчика речи
- Сохранение оригинальных видео кадров
- Объединение переведенной арабской речи с помощью видео кадров, чтобы создать арабское видео
Чтобы улучшить результаты, две дополнительные модели используются в речевом переводчике:
- Модель пунктуации, чтобы добавить пунктуацию в английские субтитры
- Модель ташкила, чтобы добавить диаклитические знаки в арабский текст
| Трубопровод для дублирования видео | 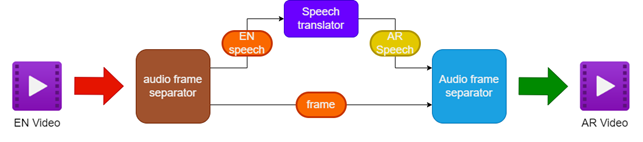 |
|---|
| Речь Тарнслейтор | 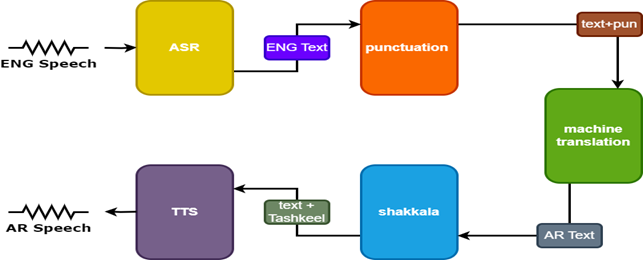 |
Системная архитектура
Система следует модульной архитектуре, состоящей из:
- Приложения для пользователя (приложение Flutter)
- Сервер приложений (Localhost и Herouku)
- Сервер базы данных (Firebase)
- Трубопроводы машинного обучения для ASR, NMT, TTS (Pytorch, Tensorflow и Huggingface)
| Система Main ComponeNet | 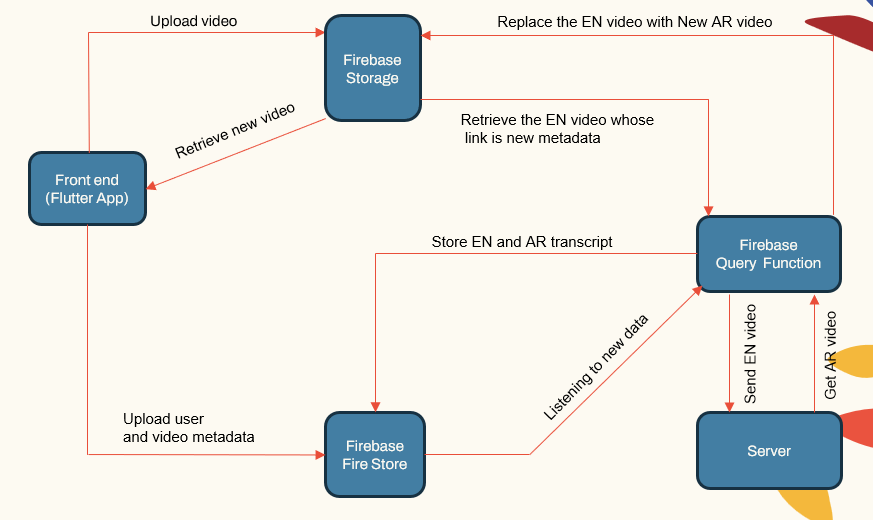 |
|---|
Сервер приложений обрабатывает управление пользователями, загрузки/загрузки видео и взаимодействие с трубопроводами ML. В базе данных хранится пользовательские данные, видео метаданные, транскрипты и т. Д.
Распознавание речи
Эксперименты сравнивали API WAVE2VEC2.0 и Google. WAVE2VEC2.0 дал более низкие частоты ошибок слова путем предварительной подготовки на крупных немеченых речевых данных, за которыми следуют создание на небольшом помеченном наборе данных. Функция потерь CTC использовалась для обучения акустической модели для преобразования речевых функций в характерные вероятности.
| WAVE2VEC2.0 с декодированием CTC | 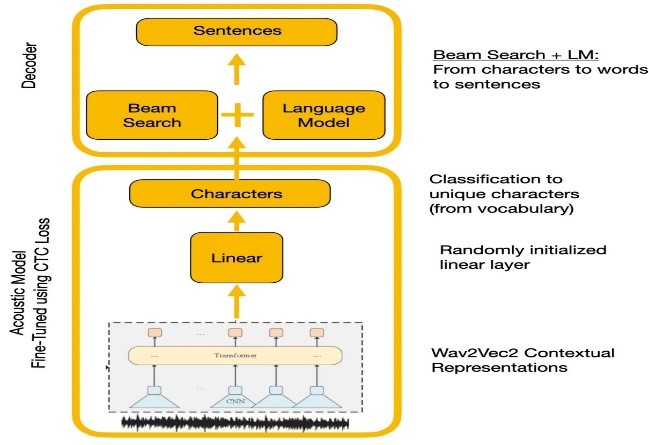 |
|---|
Машинный перевод
Архитектура Google NMT использует слои LSTM с механизмом внимания:
- Encoder LSTM преобразует исходный текст в векторные представления
- Модуль внимания выравнивает источники с каждым целевым словом
- Декодер LSTM прогнозирует целевые слова последовательно на основе контекстных векторов
Ключевые оптимизации включают:
- Байтовая паста кодирование слов в подчинки для обработки редких слов
- Остаточные соединения в слоях сложенных LSTM для улучшения потока градиента
- Декодирование поиска луча, чтобы уменьшить ошибки и найти оптимальные переводы
| Декодер энкодера для MT | 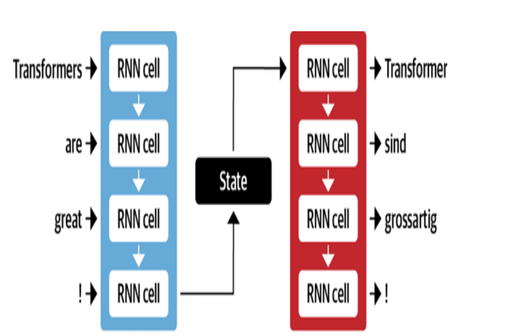 |
|---|
Текст на речь
Fastspeech2-это неавторегрессивная нейронная модель TTS, позволяющая более быстрый синтез по сравнению с авторегрессивными моделями, такими как Wavenet во время вывода. Модель принимает текст в качестве входного и прогнозирует акустические особенности мель-спектрограммы с использованием архитектуры энкодера трансформатора. Вместо расширенных свертков, многослойные персептроны (MLP) с сверточной обработкой используются в модельной архитектуре. Это обеспечивает локальное моделирование функций. Дополнительные предикторы дисперсии включены в модельные речевые атрибуты, такие как профили высоты, продолжительность и энергия. Это улучшает просодию и естественность.
Таким образом, ключевыми аспектами являются:
- Неавторегрессивный параллельный синтез
- Трансформатор-энкодер-декодер
- Слои MLP для локального контекста
- Предикторы дисперсии захватывают профили речи
Это позволяет Fastspeech2 генерировать высококачественные мель-спектрограммы от текста параллельно при выводе при сохранении естественной просодии и характеристик голоса.
| Fastspeech2 | 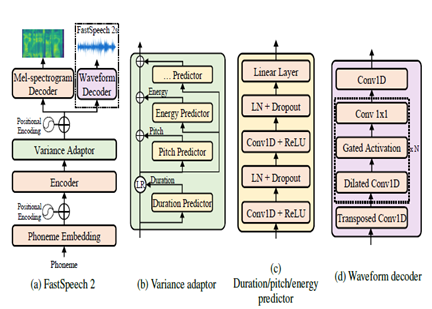 |
|---|
Результаты
Основываясь на субъективных оценках, проведенных в рамках процесса тестирования, некоторые из ключевых областей, выявленных для дальнейшего улучшения перевода и качества дублирования:
- Синхронизация губ: больше работы, необходимого для мелкой настройки времени и продолжительности дублированной речи, чтобы лучше соответствовать движениям губ.
- Выражение: захват эмоции и акцент в первоначальной речи посредством соответствующей интонации и просодии в дублированной речи.
- Свободное владение: некоторая неестественность, обнаруженная в переведенной арабской речи с точки зрения текучести предложений.
- Терминология: специфичный от домена словарный запас задал проблемы, особенно технический жаргон. Производительность снизилась для специализированных доменов.
- Сходство динамиков: хотя было создано несколько моделей динамиков, требуется больше персонализации, чтобы лучше имитировать оригинальный голос динамика.
- Фоновый шум: уменьшение фоновых артефактов и улучшение ясности звука для дублированной речи.
- Грамматика: Лучший грамматический анализ во время перевода, необходимой для создания совершенно согласованных арабских предложений.
- Диалектальная речь: обработка неформального языка, диалектов и сленга.
Ссылки
- Алексей Баевски, HZ-R. (2020). WAV2VEC 2.0: основа для самоуверенного изучения речевых представлений. Невра. МЕТА.
- Anmol Gulati, JQ-C. (2020). Конформер: свершение-август-трансформер для распознавания речи. Невра.
- Ashish Vaswani, NS (2017). Внимание - это все, что вам нужно. Невра.
- Chenxu Hu1, Qt (2021). Нейронный даббер: дублирование для видео в соответствии со сценариями. Невра.
- Marcello Federico, Re-C. (2020). От перевода речи к речи до автоматического дублирования. Материалы 17 -й Международной конференции по переводу разговорного языка (стр. 257–264). Ассоциация вычислительной лингвистики.
- Найджел Дж. Уорд, JE (2022). Диалоги повторно проработали между языками. UTEP-CS-22-108.
- Rong Ye, MW (2022). Кросс-модальное контрастное обучение для перевода речи. Наакл.
- Wei-nen Hsu, Bb-h. (2021). Хьюберт: самоотверженное речевое представление, обучение в масках, предсказание скрытых подразделений. Neurips (стр. 10). МЕТА.
- Йифан Пэн, SD (2022). Branpalformer: параллельные архитектуры MLP-привлекательного для захвата локального и глобального контекста для распознавания речи и понимания. ICML.
- Yihan Wu, JG (2023). VideoDubber: машинный перевод с управлением речью для длины для видео. Ааай.
- Klaam Project
- Nemo Toolkit из Nvidia
- объятие
- Иллюстрированная статья трансформатора
- Аннотированный трансформатор
- Самоуничивание и предварительное обучение, понимание серии Wav2VEC
- Берт объяснил: Состояние модели художественного языка для NLP


