ระบบการทำสำเนาวิดีโออัตโนมัติจากภาษาอังกฤษเป็นภาษาอาหรับ
โครงการนี้นำเสนอการศึกษาที่ครอบคลุมเกี่ยวกับเทคนิคการทำสำเนาวิดีโอและการพัฒนาระบบการทำสำเนาวิดีโอพิเศษ วัตถุประสงค์คือเพื่อแทนที่เสียงต้นฉบับในวิดีโอภาษาต่างประเทศด้วยเสียงของนักแสดงที่พูดภาษาของกลุ่มเป้าหมายในขณะที่มั่นใจว่าการซิงโครไนซ์ระหว่างการเคลื่อนไหวของริมฝีปากและคำพูดที่ขนานนาม
ความสำคัญของการทำสำเนาวิดีโออัตโนมัติ
การทำสำเนาวิดีโอมีจุดมุ่งหมายเพื่อสร้างเนื้อหาวิดีโอที่ไม่เปลี่ยนแปลงทั่วทั้งวัฒนธรรมทั่วโลก ระบบการพากย์วิดีโออัตโนมัติมักจะเกี่ยวข้องกับงานย่อยสามชิ้น:
- การรู้จำเสียงพูดอัตโนมัติ (ASR) ซึ่งถอดความคำพูดดั้งเดิมเป็นข้อความในภาษาต้นฉบับ
- Neural Machine Translation (NMT) ซึ่งแปลข้อความภาษาต้นฉบับเป็นภาษาเป้าหมาย
- Text-to-Speech (TTS) ซึ่งสังเคราะห์ข้อความที่แปลเป็นคำพูดเป้าหมาย
การทำสำเนาวิดีโอช่วยเพิ่มความสามารถในการเข้าถึงการมีส่วนร่วมและการกระจายเนื้อหาหลายภาษาในขณะที่รักษาความสมบูรณ์ของภาพสำหรับการสื่อสารข้ามวัฒนธรรม
ความท้าทาย
การทำสำเนาวิดีโออัตโนมัติต้องเผชิญกับความท้าทายหลายประการ:
- ความแม่นยำในการซิงค์ของริมฝีปาก
- ความเป็นธรรมชาติของเสียงที่ขนานนาม
- การปรับตัวทางวัฒนธรรมและการแปล
- การพิจารณาหลายภาษาและหลากหลายวัฒนธรรม
- การสลับรหัส
วิธีการ
วิธีการที่เสนอเกี่ยวข้องกับ:
- การแยกเสียงและวิดีโอจากวิดีโอภาษาอังกฤษแหล่งที่มา
- การแปลเสียงภาษาอังกฤษเป็นคำพูดภาษาอาหรับโดยใช้นักแปลคำพูด
- รักษาเฟรมวิดีโอดั้งเดิม
- การรวมคำพูดภาษาอาหรับที่แปลเข้ากับเฟรมวิดีโอเพื่อสร้างวิดีโอที่ขนานนามว่าเป็นภาษาอาหรับ
เพื่อปรับปรุงผลลัพธ์จะใช้โมเดลเพิ่มเติมสองแบบในการแปลคำพูด:
- รูปแบบเครื่องหมายวรรคตอนเพื่อเพิ่มเครื่องหมายวรรคตอนเป็นคำบรรยายภาษาอังกฤษ
- Tashkeel Model เพื่อเพิ่มเครื่องหมาย diacritical ลงในข้อความภาษาอาหรับ
| ไปป์ไลน์สำหรับวิดีโอพากย์ | 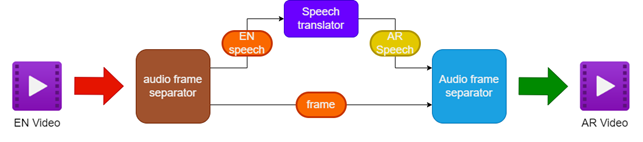 |
|---|
| คำพูด tarnslator | 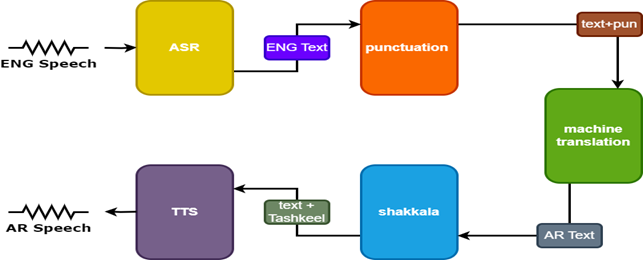 |
สถาปัตยกรรมระบบ
ระบบดังต่อไปนี้สถาปัตยกรรมแบบแยกส่วนประกอบด้วย:
- แอพพลิเคชั่นผู้ใช้หันหน้าไปทาง (แอพพลิเคชั่น Flutter)
- แอปพลิเคชันเซิร์ฟเวอร์ (LocalHost และ Herouku)
- เซิร์ฟเวอร์ฐานข้อมูล (Firebase)
- ท่อการเรียนรู้ของเครื่องจักรสำหรับ ASR, NMT, TTS (Pytorch, Tensorflow และ HuggingFace)
| ระบบหลัก | 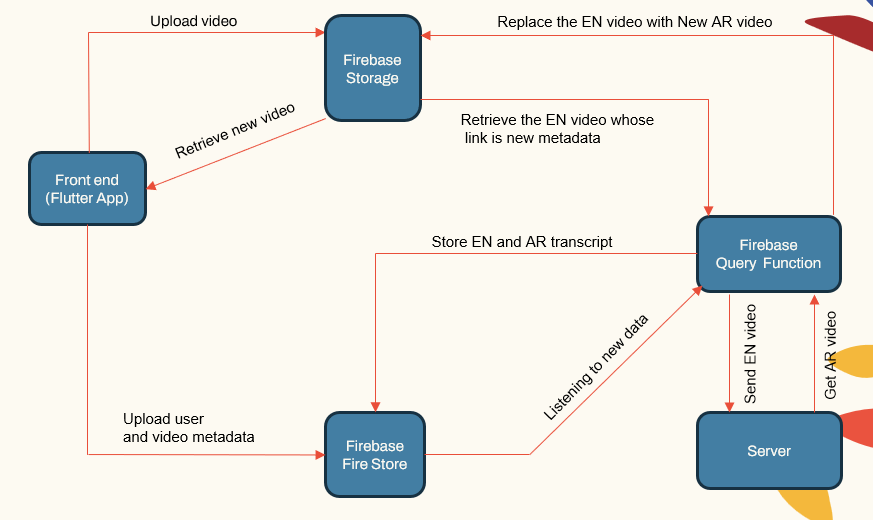 |
|---|
แอปพลิเคชันเซิร์ฟเวอร์จัดการการจัดการผู้ใช้การอัปโหลด/ดาวน์โหลดวิดีโอและการเชื่อมต่อกับท่อ ML ฐานข้อมูลจัดเก็บข้อมูลผู้ใช้ข้อมูลเมตาวิดีโอการถอดเสียง ฯลฯ
การรู้จำเสียงพูด
การทดลองเปรียบเทียบ Wave2Vec2.0 และ API การรู้จำเสียงพูดของ Google Wave2Vec2.0 ให้อัตราข้อผิดพลาดคำที่ต่ำกว่าโดยการเตรียมข้อมูลคำพูดที่ไม่มีป้ายกำกับขนาดใหญ่ตามด้วย finetuning บนชุดข้อมูลขนาดเล็กที่มีป้ายกำกับ ฟังก์ชั่นการสูญเสีย CTC ใช้ในการฝึกแบบจำลองอะคูสติกเพื่อแปลงคุณสมบัติการพูดให้เป็นความน่าจะเป็นของตัวละคร
| wave2vec2.0 พร้อมการถอดรหัส CTC | 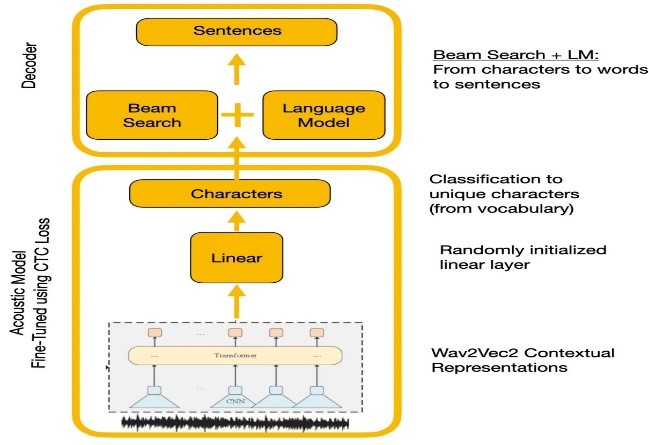 |
|---|
การแปลเครื่องจักร
สถาปัตยกรรม NMT ของ Google ใช้เลเยอร์ LSTM พร้อมกลไกความสนใจ:
- ENCODER LSTM แปลงข้อความต้นฉบับเป็นตัวแทนเวกเตอร์
- โมดูลความสนใจจัดเรียงการแสดงแหล่งที่มากับแต่ละคำเป้าหมาย
- ตัวถอดรหัส LSTM ทำนายคำเป้าหมายตามลำดับตามบริบทของเวกเตอร์
การเพิ่มประสิทธิภาพที่สำคัญ ได้แก่ :
- การเข้ารหัสคำไบต์คู่เป็นคำย่อยเพื่อจัดการกับคำที่หายาก
- การเชื่อมต่อที่เหลืออยู่ในเลเยอร์ LSTM แบบซ้อนเพื่อปรับปรุงการไหลของการไล่ระดับสี
- การถอดรหัสการค้นหาลำแสงเพื่อลดข้อผิดพลาดและค้นหาการแปลที่ดีที่สุด
| ตัวถอดรหัสสำหรับ MT | 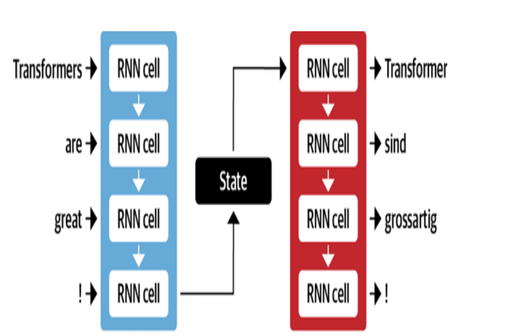 |
|---|
ส่งข้อความถึงการพูด
FastSpeech2 เป็นแบบจำลอง TTS ที่ไม่ใช่ระบบประสาทแบบ Autoregressive ช่วยให้การสังเคราะห์เร็วขึ้นเมื่อเทียบกับแบบจำลองอัตโนมัติเช่น Wavenet ในระหว่างการอนุมาน โมเดลใช้ข้อความเป็นอินพุตและทำนายคุณสมบัติอะคูสติก mel-spectrogram โดยใช้สถาปัตยกรรมตัวเข้ารหัสตัวเข้ารหัสหม้อแปลง แทนที่จะใช้การขยายตัวของหลายชั้น perceptrons (MLPs) ที่มีการประมวลผล convolutional ถูกใช้ในสถาปัตยกรรมแบบจำลอง สิ่งนี้ให้การสร้างแบบจำลองคุณสมบัติในท้องถิ่น ตัวทำนายความแปรปรวนเพิ่มเติมถูกรวมเข้ากับคุณลักษณะการพูดแบบจำลองเช่นพิทช์ระยะเวลาและโปรไฟล์พลังงาน สิ่งนี้ช่วยปรับปรุงฉันทลักษณ์และความเป็นธรรมชาติ
โดยสรุปประเด็นสำคัญคือ:
- การสังเคราะห์แบบขนานที่ไม่ใช่แบบไม่ได้
- ตัวเข้ารหัส Transformer
- เลเยอร์ MLP สำหรับบริบทท้องถิ่น
- ตัวทำนายความแปรปรวนจับโปรไฟล์คำพูด
สิ่งนี้ช่วยให้ FastSpeech2 สามารถสร้าง mel-spectrograms คุณภาพสูงจากข้อความในแบบขนานระหว่างการอนุมานในขณะที่ยังคงรักษาลักษณะของฉันเองตามธรรมชาติและลักษณะเสียง
| FastSpeech2 | 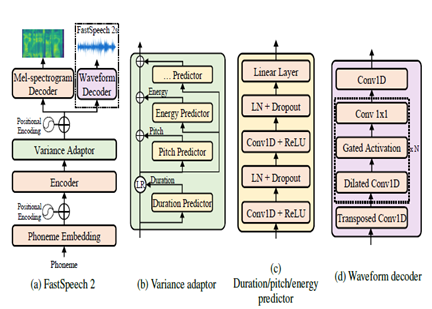 |
|---|
ผลลัพธ์
ขึ้นอยู่กับการประเมินอัตนัยที่ทำเป็นส่วนหนึ่งของกระบวนการทดสอบบางพื้นที่สำคัญที่ระบุไว้สำหรับการปรับปรุงเพิ่มเติมในการแปลและคุณภาพการทำสำเนาคือ:
- การซิงโครไนซ์ริมฝีปาก: ต้องทำงานมากขึ้นเพื่อปรับแต่งเวลาและระยะเวลาของการพูดที่ขนานนามเพื่อให้ตรงกับการเคลื่อนไหวของริมฝีปากที่ดีขึ้น
- การแสดงออก: การจับอารมณ์และการเน้นในคำพูดดั้งเดิมผ่านน้ำเสียงที่เหมาะสมและฉันทลักษณ์ในคำพูดที่ขนานนาม
- ความคล่องแคล่ว: ตรวจพบความผิดธรรมชาติบางอย่างในคำพูดภาษาอาหรับที่แปลในแง่ของความลื่นไหลของประโยค
- คำศัพท์: คำศัพท์เฉพาะของโดเมนทำให้เกิดความท้าทายโดยเฉพาะศัพท์แสงทางเทคนิค ประสิทธิภาพลดลงสำหรับโดเมนเฉพาะ
- ความคล้ายคลึงกันของลำโพง: ในขณะที่มีการสร้างแบบจำลองลำโพงหลายรุ่นจำเป็นต้องมีการปรับแต่งให้เป็นส่วนตัวมากขึ้นเพื่อเลียนแบบเสียงลำโพงดั้งเดิม
- เสียงรบกวนจากพื้นหลัง: การลดสิ่งประดิษฐ์พื้นหลังและการปรับปรุงความชัดเจนของเสียงสำหรับคำพูดที่ขนานนาม
- ไวยากรณ์: การวิเคราะห์ทางไวยากรณ์ที่ดีขึ้นในระหว่างการแปลที่จำเป็นในการสร้างประโยคภาษาอาหรับที่สอดคล้องกันอย่างสมบูรณ์
- คำพูดภาษาถิ่น: การจัดการภาษาที่ไม่เป็นทางการภาษาถิ่นและสแลง
การอ้างอิง
- Alexei Baevski, Hz-R (2020) WAV2VEC 2.0: กรอบสำหรับการเรียนรู้ด้วยตนเองของการเรียนรู้ด้วยตนเอง ประสาท เมตา
- Anmol Gulati, JQ-C (2020) conformer: หม้อแปลงที่มีความสุขสำหรับการรู้จำเสียงพูด ประสาท
- Ashish Vaswani, NS (2017) ความสนใจคือสิ่งที่คุณต้องการ ประสาท
- Chenxu Hu1, Qt (2021) Neural Dubber: Dubbing สำหรับวิดีโอตามสคริปต์ ประสาท
- Marcello Federico, Re-C (2020) จากการแปลคำพูดเป็นคำพูดไปจนถึงการทำสำเนาอัตโนมัติ การดำเนินการประชุมนานาชาติครั้งที่ 17 เรื่องการแปลภาษาพูด (หน้า 257–264) การเชื่อมโยงสำหรับภาษาศาสตร์เชิงคำนวณ
- Nigel G. Ward, JE (2022) กล่องโต้ตอบซ้ำกันข้ามภาษา UTEP-CS-22-108
- Rong Ye, MW (2022) การเรียนรู้แบบตัดกันข้ามโมดอลสำหรับการแปลคำพูด NAACL
- wei-ning hsu, bb-h (2021) ฮิวเบิร์ต: การเรียนรู้การเป็นตัวแทนการพูดด้วยตนเองโดยการทำนายการสวมหน้ากากของหน่วยที่ซ่อนอยู่ NEURIPS (หน้า 10) เมตา
- Yifan Peng, SD (2022) BranchFormer: สถาปัตยกรรมการแทรกแซง MLP แบบขนานเพื่อจับบริบทในระดับท้องถิ่นและระดับโลกเพื่อการรู้จำเสียงพูดและความเข้าใจ ICML
- Yihan Wu, JG (2023) Videodubber: การแปลด้วยเครื่องด้วยการควบคุมความยาวของเสียงพูดสำหรับการทำสำเนาวิดีโอ Aaai.
- โครงการ Klaam
- Nemo Toolkit จาก Nvidia
- กอด
- บทความ Transformer ภาพประกอบ
- หม้อแปลงหมายเหตุ
- การฝึกอบรมตนเองและการฝึกอบรมก่อนทำความเข้าใจซีรีส์ WAV2VEC
- Bert อธิบาย: รูปแบบภาษาที่ทันสมัยสำหรับ NLP


