Système de doublage vidéo automatique de l'anglais à l'arabe
Ce projet présente une étude complète sur les techniques de doublage vidéo et le développement d'un système de doublage vidéo spécialisé. L'objectif est de remplacer les voix originales dans des vidéos en langue étrangère par les voix des artistes parlant la langue du public cible, tout en assurant la synchronisation entre les mouvements des lèvres et la parole doublée.
Importance du doublage vidéo automatique
Le doublage vidéo vise à rendre le contenu vidéo invariant à travers les cultures mondiales. Les systèmes de doublage vidéo automatique impliquent généralement trois sous-tâches:
- Reconnaissance automatique de la parole (ASR), qui transcrit le discours original en texte dans la langue source.
- Traduction de machine neuronale (NMT), qui traduit le texte de la langue source par la langue cible.
- Texte à dispection (TTS), qui synthétise le texte traduit en discours cible.
Le doublage vidéo améliore l'accessibilité, l'engagement et la distribution globale du contenu multilingue tout en préservant l'intégrité visuelle pour la communication interculturelle.
Défis
Doublage vidéo automatique fait face à plusieurs défis:
- Précision de synchronisation des lèvres
- Naturel de la voix doublée
- Adaptation culturelle et localisation
- Considérations multilingues et multiculturelles
- Commutation de code.
Méthodologie
La méthodologie proposée implique:
- Séparer l'audio et la vidéo de la vidéo anglaise source
- Traduction de l'audio anglais en discours arabe à l'aide d'un traducteur de la parole
- Préserver les cadres vidéo originaux
- Fusion du discours arabe traduit avec les cadres vidéo pour créer une vidéo doublée arabe
Pour améliorer les résultats, deux modèles supplémentaires sont utilisés dans le traducteur de la parole:
- Modèle de ponctuation pour ajouter la ponctuation aux sous-titres anglais
- Modèle Tashkeel pour ajouter des marques diacritiques au texte arabe
| Pipeline pour le doublage de la vidéo | 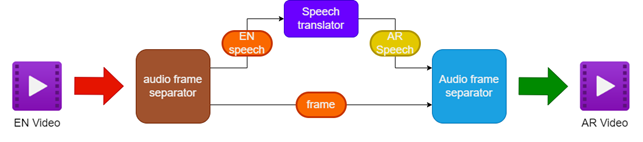 |
|---|
| Tarnslator de la parole | 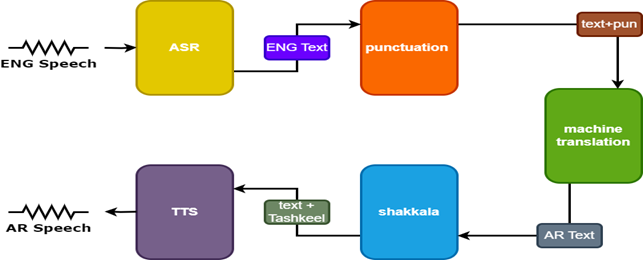 |
Architecture du système
Le système suit une architecture modulaire composée de:
- Applications face à l'utilisateur (application Flutter)
- Serveur d'applications (LocalHost et Herouku)
- Serveur de base de données (Firebase)
- Pipelines d'apprentissage automatique pour ASR, NMT, TTS (Pytorch, Tensorflow et HuggingFace)
| Componnet principal du système | 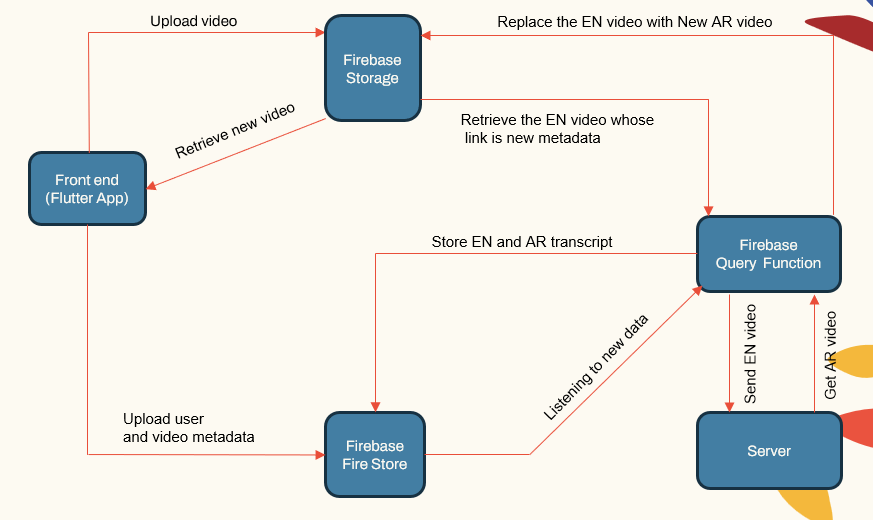 |
|---|
Le serveur d'applications gère la gestion des utilisateurs, les téléchargements / téléchargements vidéo et l'interfaçage avec les pipelines ML. La base de données stocke les données utilisateur, les métadonnées vidéo, les transcriptions, etc.
Reconnaissance de la parole
Les expériences ont comparé les API Wave2Vec2.0 et Google de reconnaissance vocale. WAVE2VEC2.0 a donné des taux d'erreur de mots inférieurs en pré-formation sur de grandes données vocales non marquées, suivis d'une fin de finetun sur un petit ensemble de données étiqueté. La fonction de perte CTC a été utilisée pour former un modèle acoustique pour convertir les caractéristiques de la parole en probabilités de caractère.
| Wave2vec2.0 avec décodage CTC | 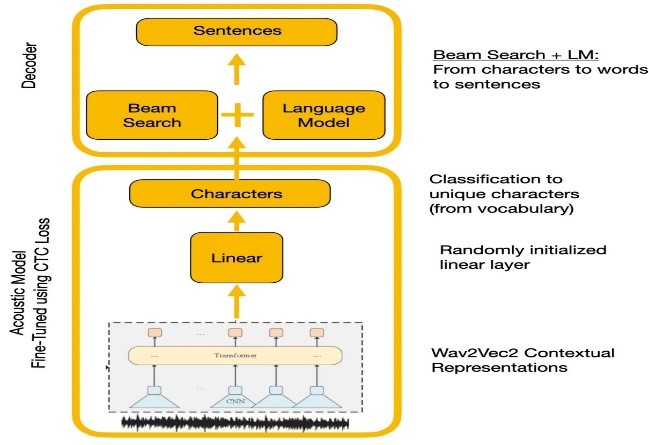 |
|---|
Traduction automatique
L'architecture NMT de Google utilise les couches LSTM avec mécanisme d'attention:
- L'encodeur LSTM convertit le texte de la source en représentations vectorielles
- Le module d'attention aligne les représentations de la source sur chaque mot cible
- Decoder LSTM prédit des mots cibles séquentiellement basés sur des vecteurs de contexte
Les optimisations clés comprennent:
- Encodage de paires d'octets de mots en sous-mots pour gérer les mots rares
- Connexions résiduelles dans les couches LSTM empilées pour améliorer le flux de gradient
- Décodage de recherche de faisceau pour réduire les erreurs et trouver des traductions optimales
| Décodeur d'encodeur pour MT | 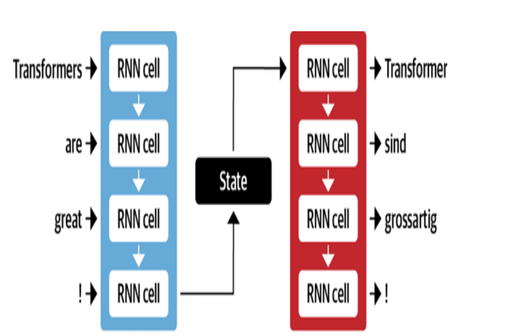 |
|---|
Texte à la parole
FastSpeech2 est un modèle TTS neuronal non autorégressif, permettant une synthèse plus rapide par rapport aux modèles autorégressifs comme WAVENET pendant l'inférence. Le modèle prend le texte comme entrée et prédit des caractéristiques acoustiques de spectrogramme MEL à l'aide d'une architecture de coder de transformateur. Au lieu de convolutions dilatées, les perceptrons multicouches (MLP) avec traitement convolutionnel sont utilisés dans l'architecture du modèle. Cela fournit une modélisation des fonctionnalités locales. Des prédicteurs de variance supplémentaires sont incorporés pour modéliser les attributs de la parole tels que les profils de hauteur, de durée et d'énergie. Cela améliore la prosodie et le naturel.
En résumé, les aspects clés sont:
- Synthèse parallèle non autorégressive
- Encodeur de transformateur
- Couches MLP pour le contexte local
- Les prédicteurs de variance capturent les profils de discours
Cela permet à FastSpeech2 de générer des spectrogrammes de MEL de haute qualité à partir de texte en parallèle pendant l'inférence tout en maintenant la prosodie naturelle et les caractéristiques vocales.
| FastSpeech2 | 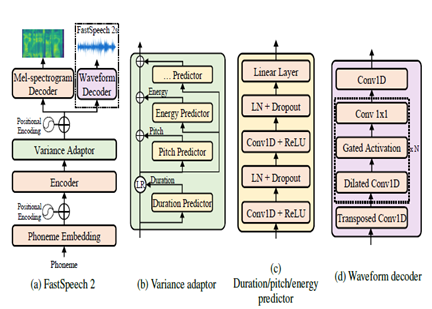 |
|---|
Résultats
Sur la base des évaluations subjectives effectuées dans le cadre du processus de test, certains des domaines clés identifiés pour une amélioration supplémentaire de la qualité de la traduction et du doublage étaient:
- Synchronisation des lèvres: plus de travail nécessaire pour régler finement le timing et la durée de la parole doublée pour mieux correspondre aux mouvements des lèvres.
- Expression: capturer l'émotion et l'accent dans le discours original par l'intonation et la prosodie appropriées dans le discours doublé.
- Fluence: Une certaine imprécision détectée dans le discours arabe traduit en termes de fluidité des phrases.
- Terminologie: Le vocabulaire spécifique au domaine a posé des défis, en particulier le jargon technique. Les performances ont diminué pour les domaines spécialisés.
- Similité des conférenciers: Bien que plusieurs modèles de haut-parleurs aient été créés, une plus grande personnalisation est nécessaire pour mieux imiter la voix de haut-parleurs d'origine.
- Bruit de fond: réduction des artefacts de fond et amélioration de la clarté audio pour le discours doublé.
- Grammaire: meilleure analyse grammaticale lors de la traduction nécessaire pour produire des phrases arabes parfaitement cohérentes.
- Discours dialectal: gestion du langage informel, dialectes et argot.
Références
- Alexei Baevski, Hz-R. (2020). WAV2VEC 2.0: Un cadre pour l'apprentissage auto-supervisé des représentations de la parole. Neurips. Méta.
- Anmol Gulati, JQ-C. (2020). Conformer: Transformateur augmenté de la convolution pour la reconnaissance de la parole. Neurips.
- Ashish Vaswani, NS (2017). L'attention est tout ce dont vous avez besoin. Neurips.
- Chenxu Hu1, Qt (2021). Neural Dubber: Doublage des vidéos selon les scripts. Neurips.
- Marcello Federico, re-c. (2020). De la traduction de la parole à la parole au doublage automatique. Actes de la 17e Conférence internationale sur la traduction en langue parlée (pp. 257-264). Association pour la linguistique informatique.
- Nigel G. Ward, JE (2022). Dialogues reconstituées entre les langues. UTEP-CS-22-108.
- Rong Ye, MW (2022). Apprentissage contrastif transformatique pour la traduction de la parole. Naacl.
- Wei-ning hsu, bb-h. (2021). Hubert: Représentation de la parole auto-supervisée par la prédiction masquée des unités cachées. NIRIPS (p. 10). Méta.
- Yifan Peng, SD (2022). BranchFormer: Architectures parallèles de l'attention MLP pour capturer le contexte local et mondial pour la reconnaissance et la compréhension de la parole. Icml.
- Yihan Wu, JG (2023). VideoDubber: Traduction automatique avec contrôle de la longueur consacrée à la parole pour le doublage vidéo. Aaai.
- Projet Klaam
- Nemo Toolkit de Nvidia
- étreinte
- L'article de transformateur illustré
- Le transformateur annoté
- S'auto-entraîner et pré-formation, compréhension de la série WAV2VEC
- Bert a expliqué: modèle de langue de pointe pour PNL


