영어에서 아랍어까지 자동 비디오 더빙 시스템
이 프로젝트는 비디오 더빙 기술과 특수 비디오 더빙 시스템의 개발에 대한 포괄적 인 연구를 제시합니다. 목표는 외국어 비디오의 원래 음성을 대상 청중의 언어를 말하는 공연자의 목소리로, 입술 움직임과 더빙 된 연설 사이의 동기화를 보장하는 것입니다.
자동 비디오 더빙의 중요성
비디오 더빙은 전 세계 문화에서 비디오 콘텐츠를 변하지 않는 것을 목표로합니다. 자동 비디오 더빙 시스템에는 일반적으로 3 개의 하위 작업이 포함됩니다.
- 원본 음성을 소스 언어로 텍스트로 전사하는 자동 음성 인식 (ASR).
- NMT (Neural Machine Translation). 소스 언어 텍스트를 대상 언어로 변환합니다.
- 번역 된 텍스트를 대상 음성으로 합성하는 텍스트 음성 (TTS).
비디오 더빙은 문화 간 커뮤니케이션을위한 시각적 무결성을 유지하면서 다국어 콘텐츠의 접근성, 참여 및 글로벌 배포를 향상시킵니다.
도전
자동 비디오 더빙은 몇 가지 과제에 직면 해 있습니다.
- 립싱크 정확도
- 더빙 된 목소리의 자연성
- 문화적 적응 및 현지화
- 다국어 및 다문화 고려 사항
- 코드 전환.
방법론
제안 된 방법론에는 다음이 포함됩니다.
- 소스 영어 비디오에서 오디오 및 비디오 분리
- 언어 번역기를 사용하여 영어 오디오를 아랍어 연설로 번역
- 원래 비디오 프레임을 보존합니다
- 번역 된 아랍어 연설을 비디오 프레임과 병합하여 아랍어 더빙 비디오를 만듭니다.
결과를 개선하기 위해 Speech Translator에는 두 가지 추가 모델이 사용됩니다.
- 영어 자막에 문장 부호를 추가하는 구두점 모델
- Tashkeel 모델은 아랍어 텍스트에 Diacritical Mark를 추가합니다
| 더빙 비디오를위한 파이프 라인 | 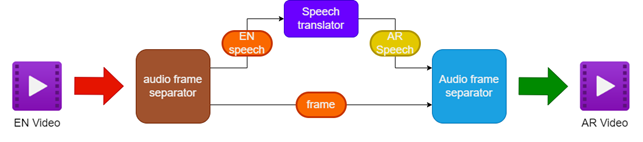 |
|---|
| 연설 tarnslator | 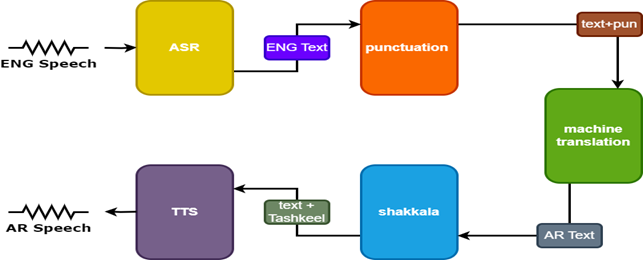 |
시스템 아키텍처
이 시스템은 다음으로 구성된 모듈 식 아키텍처를 따릅니다.
- 사용자가 직면하는 앱 (Flutter App)
- 응용 프로그램 서버 (LocalHost 및 Herouku)
- 데이터베이스 서버 (FireBase)
- ASR, NMT, TTS 용 머신 러닝 파이프 라인 (Pytorch, Tensorflow 및 Huggingface)
| 시스템 메인 ComponeNet | 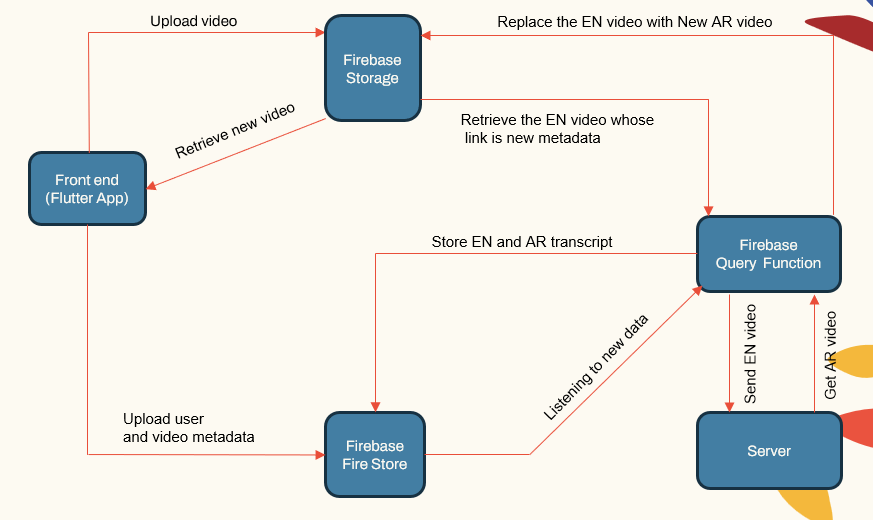 |
|---|
응용 프로그램 서버는 사용자 관리, 비디오 업로드/다운로드 및 ML 파이프 라인과 인터페이스를 처리합니다. 데이터베이스는 사용자 데이터, 비디오 메타 데이터, 전사장 등을 저장합니다.
음성 인식
실험은 Wave2Vec2.0과 Google Speech 인식 API를 비교했습니다. Wave2Vec2.0은 대규모 표지되지 않은 음성 데이터에 대한 사전 변수에 의해 낮은 단어 오류율을 제공 한 다음 작은 라벨이 붙은 데이터 세트에서 미세 조정을 제공했습니다. CTC 손실 함수는 음성 기능을 캐릭터 확률로 변환하기 위해 음향 모델을 훈련시키는 데 사용되었습니다.
| CTC 디코딩을 사용한 Wave2Vec2.0 | 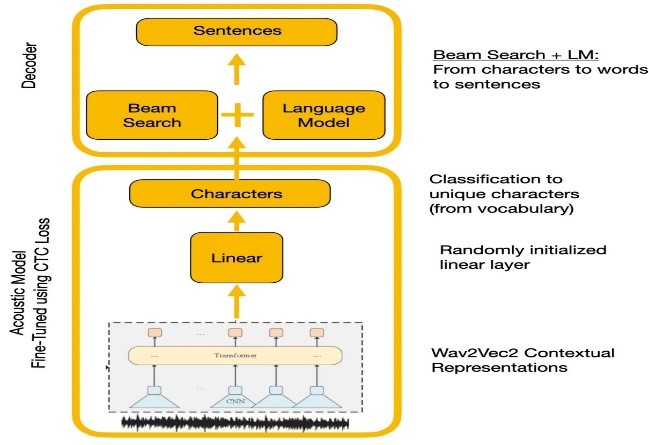 |
|---|
기계 번역
Google의 NMT 아키텍처는주의 메커니즘과 함께 LSTM 레이어를 사용합니다.
- 인코더 LSTM은 소스 텍스트를 벡터 표현으로 변환합니다
- 주의 모듈은 소스 표현을 각 대상 단어에 정렬합니다
- 디코더 LSTM은 컨텍스트 벡터를 기반으로 순차적으로 대상 단어를 예측합니다.
주요 최적화에는 다음이 포함됩니다.
- 희귀 단어를 처리하기 위해 단어를 서브 워드로 인코딩하는 바이트 쌍
- 구배 흐름을 개선하기 위해 스택 된 LSTM 층의 잔류 연결
- 오류를 줄이고 최적의 번역을 찾기위한 빔 검색 디코딩
| MT에 대한 엔코더 디코더 | 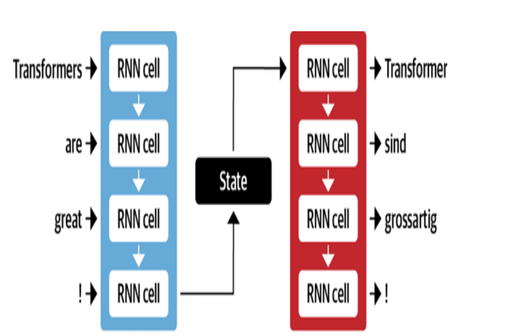 |
|---|
연설에 텍스트
FastSpeech2는 비 유포리 신경 TTS 모델로, 추론 중 Wavenet과 같은자가 회귀 모델에 비해 더 빠른 합성을 허용합니다. 이 모델은 텍스트를 입력으로 취하고 변압기 인코더 디코더 아키텍처를 사용하여 Mel-Spectrogram 음향 기능을 예측합니다. 확장 된 컨볼 루션 대신 컨볼 루션 처리를 갖춘 다층 퍼셉 트론 (MLP)이 모델 아키텍처에 사용됩니다. 이것은 로컬 기능 모델링을 제공합니다. 추가 분산 예측 변수는 피치, 지속 시간 및 에너지 프로파일과 같은 음성 속성에 통합됩니다. 이것은 번영과 자연을 향상시킵니다.
요약하면, 주요 측면은 다음과 같습니다.
- 비 유포리 평행 합성
- 변압기 인코더 디코더
- 로컬 컨텍스트를위한 MLP 층
- 분산 예측 변수는 음성 프로파일을 캡처합니다
이를 통해 FastSpeech2는 자연스러운 번영과 음성 특성을 유지하면서 추론 중에 텍스트에서 고품질 멜 스피어 그램을 생성 할 수 있습니다.
| FastSpeech2 | 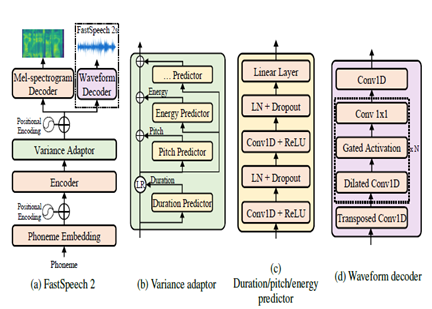 |
|---|
결과
테스트 프로세스의 일부로 수행 된 주관적 평가를 기반으로 번역 및 더빙 품질의 추가 개선을 위해 식별 된 주요 영역 중 일부는 다음과 같습니다.
- Lip Synchronization : Dubed Speech의 타이밍과 지속 시간을 미세하게 조정하는 데 필요한 작업이 더 나은 립 움직임을 더 잘 일치시킵니다.
- 표현 : 더빙 된 연설에서 적절한 억양과 번영을 통해 원래 연설에서 감정과 강조를 포착합니다.
- 유창성 : 문장의 유동성 측면에서 번역 된 아랍어 연설에서 발견 된 일부 부 자연성.
- 용어 : 도메인 별 어휘, 특히 기술 전문 용어가 문제를 일으켰습니다. 특수 도메인의 성능이 감소했습니다.
- 스피커 유사성 : 여러 스피커 모델이 생성되었지만 원래 스피커 음성을 더 잘 모방하려면 더 많은 개인화가 필요합니다.
- 배경 소음 : 배경 아티팩트 감소 및 더빙 된 연설의 오디오 선명도 개선.
- 문법 : 번역 중에 더 나은 문법 분석이 완벽하게 일관된 아랍어 문장을 생성하는 데 필요합니다.
- 변증법 : 비공식 언어, 방언 및 속어 처리.
참조
- Alexei Baevski, Hz-R. (2020). WAV2VEC 2.0 : 언어 표현에 대한 자체 감독 학습을위한 프레임 워크. 신경관. 메타.
- Anmol Gulati, JQ-C. (2020). 순응 자 : 음성 인식을위한 Convolution-Augmented Transformer. 신경관.
- Ashish Vaswani, NS (2017). 주의를 기울이기 만하면됩니다. 신경관.
- Chenxu Hu1, QT (2021). 신경 더버 : 스크립트에 따른 비디오 더빙. 신경관.
- Marcello Federico, Re-C. (2020). 연설 음성 변환에서 자동 더빙에 이르기까지. 말한 언어 번역에 관한 17 차 국제 회의 절차 (pp. 257–264). 계산 언어학 협회.
- Nigel G. Ward, JE (2022). 언어에서 대화가 다시 제정됩니다. UTEP-CS-22-108.
- Rong Ye, MW (2022). 언어 번역을위한 교차 모달 대조 학습. NaaCl.
- Wei-unning Hsu, BB-H. (2021). Hubert : 숨겨진 유닛의 가면을 쓴 예측에 의한 자기 감독 된 언어 표현 학습. 신경관 (p. 10). 메타.
- Yifan Peng, SD (2022). BranchOrmer : 음성 인식 및 이해를위한 지역 및 글로벌 컨텍스트를 캡처하기위한 병렬 MLP- 지분 아키텍처. ICML.
- Yihan Wu, JG (2023). VideoDubber : 비디오 더빙을위한 음성 인식 길이 제어 기능을 갖춘 기계 번역. AAAI.
- KLAAM 프로젝트
- NVIDIA의 NEMO 툴킷
- 포옹 페이스
- 그림 변압기 기사
- 주석이 달린 변압기
- 자기 훈련 및 사전 훈련, WAV2VEC 시리즈 이해
- Bert 설명 : NLP의 최신 언어 모델


