自动视频配音系统从英语到阿拉伯语
该项目介绍了一项有关视频配音技术的全面研究和专门视频配音系统的开发。目的是用外语视频中的原始声音替换出演员的声音,同时确保唇部动作和被称为语音之间的同步。
自动视频配音的重要性
视频配音旨在使整个世界文化的视频内容不变。自动视频配音系统通常涉及三个子任务:
- 自动语音识别(ASR),将原始语音转录为源语言。
- 神经机器翻译(NMT),将源语言文本转换为目标语言。
- 文本到语音(TTS),将翻译的文本综合为目标语音。
视频配音可以增强多语言内容的可访问性,参与度和全球分布,同时保留跨文化交流的视觉完整性。
挑战
自动视频配音面临几个挑战:
- 嘴唇同步精度
- 称为声音的自然性
- 文化适应和本地化
- 多语言和多元文化的考虑
- 代码切换。
方法论
提出的方法涉及:
- 将音频和视频与源英文视频分开
- 使用语音翻译将英语音频翻译成阿拉伯语
- 保留原始视频帧
- 将翻译的阿拉伯语演讲与视频框架合并,以创建一个名为阿拉伯语的视频
为了改善结果,语音翻译器中使用了另外两个模型:
- 标点符号模型,以增加标点符号
- Tashkeel模型为阿拉伯文字添加了音调标记
| 配音视频的管道 | 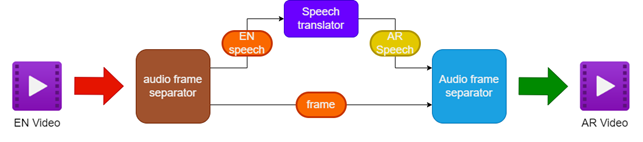 |
|---|
| 言语塔恩斯洛斯 | 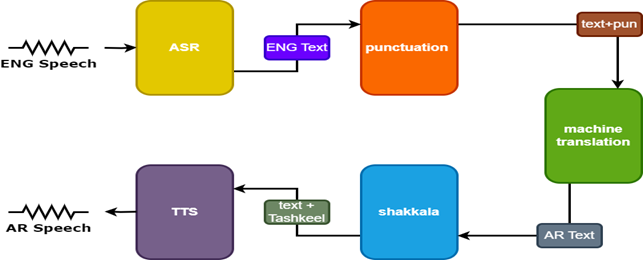 |
系统体系结构
该系统遵循一个模块化体系结构,该体系结构包括:
- 用户面对应用程序(Flutter App)
- 应用程序服务器(Localhost和Herouku)
- 数据库服务器(firebase)
- ASR,NMT,TTS的机器学习管道(Pytorch,TensorFlow和HuggingFace)
| 系统主组合 | 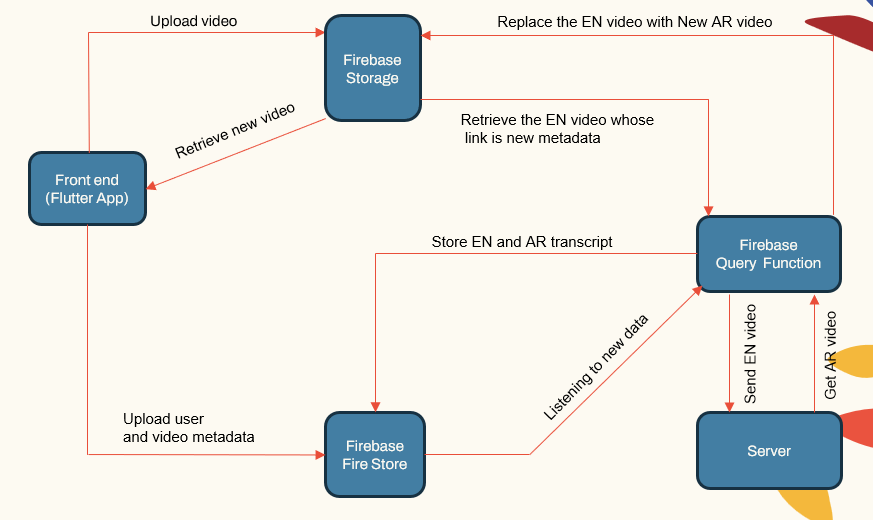 |
|---|
应用程序服务器处理用户管理,视频上传/下载以及与ML管道的接口。数据库存储用户数据,视频元数据,成绩单等。
语音识别
实验比较了Wave2VEC2.0和Google语音识别API。 Wave2Vec2.0通过在大型未标记的语音数据上进行预处理,然后在一个小标记的数据集上进行填充,从而给出了较低的单词错误率。 CTC损失函数用于训练声学模型,以将语音特征转换为字符概率。
| wave2vec2.0与CTC解码 | 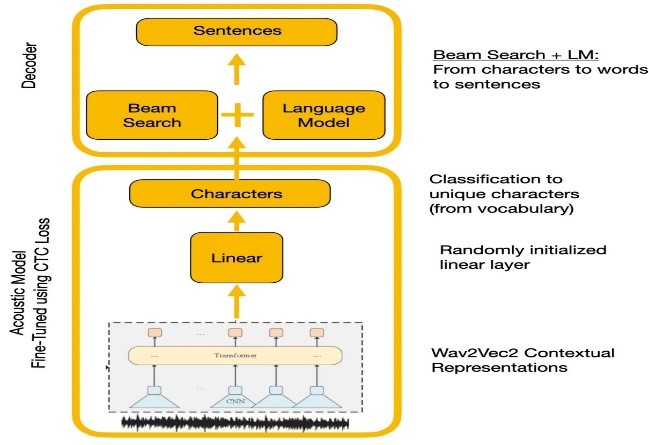 |
|---|
机器翻译
Google的NMT体系结构利用具有注意机制的LSTM层:
- 编码器LSTM将源文本转换为向量表示
- 注意模块将源表示与每个目标单词对齐
- 解码器LSTM根据上下文向量依次预测目标单词
关键优化包括:
- 字节对编码单词中的子词来处理稀有单词
- 堆叠LSTM层中的残留连接以改善梯度流量
- 梁搜索解码以减少错误并找到最佳翻译
| MT的编码器解码器 | 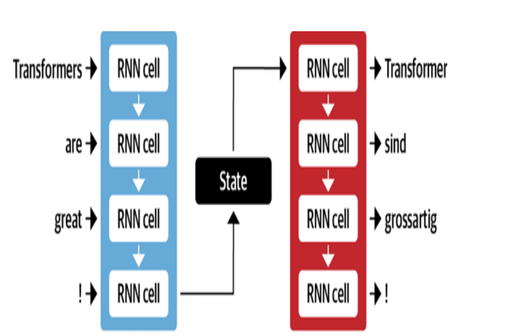 |
|---|
文字到语音
FastSpeech2是一种非自动回归神经TTS模型,与推理期间的WaveNet这样的自回归模型相比,可以更快地合成。该模型将文本视为输入,并使用变压器编码器解码器体系结构来预测MEL-SPECTROGRAM声学特征。模型体系结构中使用了带有卷积处理的多层感知器(MLP),而不是扩张的卷积。这提供了本地功能建模。将其他方差预测变量纳入模型语音属性,例如音高,持续时间和能量曲线。这改善了韵律和自然。
总而言之,关键方面是:
- 非自动收益平行合成
- 变形金刚编码器
- 本地上下文的MLP层
- 差异预测因子捕获语音概况
这允许FastSpeech2在推理过程中并行从文本产生高质量的MEL光谱图,同时保持自然韵律和语音特征。
| FastSpeech2 | 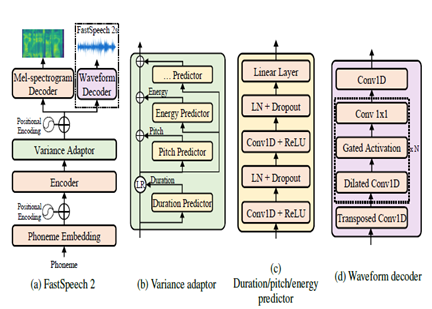 |
|---|
结果
根据作为测试过程的一部分进行的主观评估,确定的一些关键领域可进一步改善翻译和配音质量:
- 嘴唇同步:精心调整称为语音的时间和持续时间以更好地匹配唇部运动所需的更多工作。
- 表达:通过在被称为演讲中的适当语调和韵律来捕捉原始演讲中的情感和重点。
- 流利性:在句子的流动性方面,在翻译的阿拉伯语语音中检测到了一些不自然性。
- 术语:特定领域的词汇提出了挑战,尤其是技术术语。专用域的性能下降。
- 演讲者的相似性:虽然创建了多个扬声器模型,但需要更多个性化以更好地模仿原始扬声器的声音。
- 背景噪声:降低背景工件的量和改善声音的音频清晰度。
- 语法:在翻译过程中进行更好的语法分析,以产生完美的阿拉伯语句子。
- 辩证语音:处理非正式语言,方言和语。
参考
- Alexei Baevski,HZ-R。 (2020)。 WAV2VEC 2.0:一个自我监督语音表示学习的框架。神经。元。
- Anmol Gulati,JQ-C。 (2020)。构象体:卷卷动的变压器,以供语音识别。神经。
- Ashish Vaswani,NS(2017)。注意就是您所需要的。神经。
- Chenxu Hu1,QT(2021)。神经配音:根据脚本为视频配音。神经。
- Marcello Federico,Re-C。 (2020)。从语音到语音翻译到自动配音。第17届国际口语翻译会议论文集(第257-264页)。计算语言学协会。
- Nigel G. Ward,JE(2022)。跨语言重新制定对话。 UTEP-CS-22-108。
- MW(2022)。语音翻译的跨模式对比度学习。 Naacl。
- Wei-ning HSU,BB-H。 (2021)。休伯特:通过掩盖隐藏单位的掩盖预测,自我监督的语音表示学习。神经(第10页)。元。
- Yifan Peng,SD(2022)。分支机构:平行MLP注意体系结构,以捕获语音识别和理解的本地和全球环境。 ICML。
- Yihan Wu,JG(2023)。 VideoDubber:带有语音感知长度控制视频配音的机器翻译。 AAAI。
- 克拉姆项目
- NVIDIA的Nemo Toolkit
- 拥抱面
- 插图的变压器文章
- 带注释的变压器
- 自我训练和预训练,了解WAV2VEC系列
- 伯特解释了:NLP的最先进的语言模型


