pflowtts_pytorch
1.0.0
samples文件夾。 LJSpeech預估計的CKPT -GDRIVE LINK MULTISPEAKER VCTK預告片預讀CKPT(VCTK上的1100個時代)-HuggingFace論文p-flow的非官方實施:通過NVIDIA的語音提示,快速且具有數據效率的零擊中。
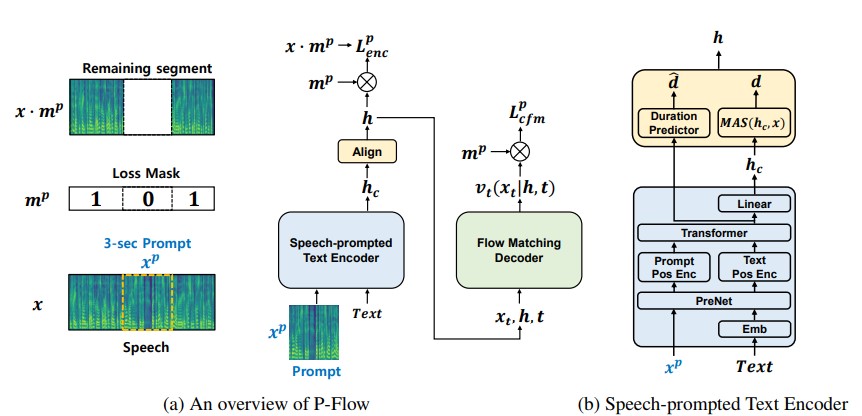
儘管最近大規模的神經編解碼器語言模型通過對數千個小時的數據進行培訓顯示了零拍的零TTS的顯著改善,但它們遭受了缺點,例如缺乏穩健性,與以前的自動回應TTS方法相似的緩慢採樣速度以及對預先培訓的神經編解碼器表示的依賴。我們的工作提出了P-Flow,這是一種快速且數據效率高的零攝像TTS模型,該模型使用語音提示進行演講者的適應性。 p-flow包含用於揚聲器適應的語音提示的文本編碼器,以及用於高質量和快速語音綜合的流量匹配生成解碼器。我們的語音啟示文本編碼器使用語音提示和文本輸入來生成揚聲器條件文本表示。流量匹配的生成解碼器使用揚聲器條件輸出來綜合高質量的個性化語音,明顯快得多。與神經編解碼器的語言模型不同,我們使用連續的MEL代理在Libritts數據集上專門訓練P-Flow。通過我們使用連續語音提示的訓練方法,p-flow匹配了大規模零擊中TTS模型的揚聲器相似性性能,其訓練數據較少,並且具有超過20倍的訓練速度。我們的結果表明,p-flow具有更好的發音,並且在人類的相似性和說話者的相似性中被優先於其最近的最新對應物,從而將p-flow定義為一種有吸引力且值得期望的替代方案。
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowtts留在根目錄中(當然,首先克隆回購!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplace假設我們正在接受LJ演講的培訓
data/LJSpeech-1.1 ,然後準備文件列表以指向提取的數據,例如NVIDIA TACOTRON 2 REPO的設置中的項目5。 3a。轉到configs/data/ljspeech.yaml並更改
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b。幫手命令懶惰
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574}在data_statistics密鑰下,在configs/data/ljspeech.yaml中更新這些值。
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101到您的火車和驗證材料的道路。
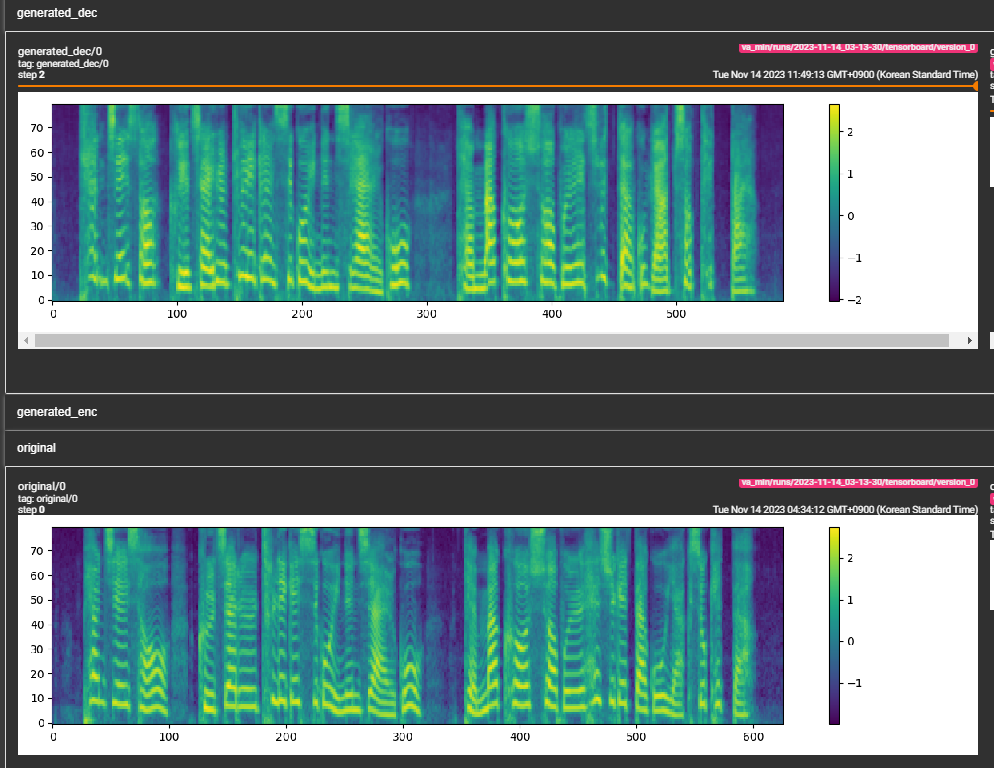
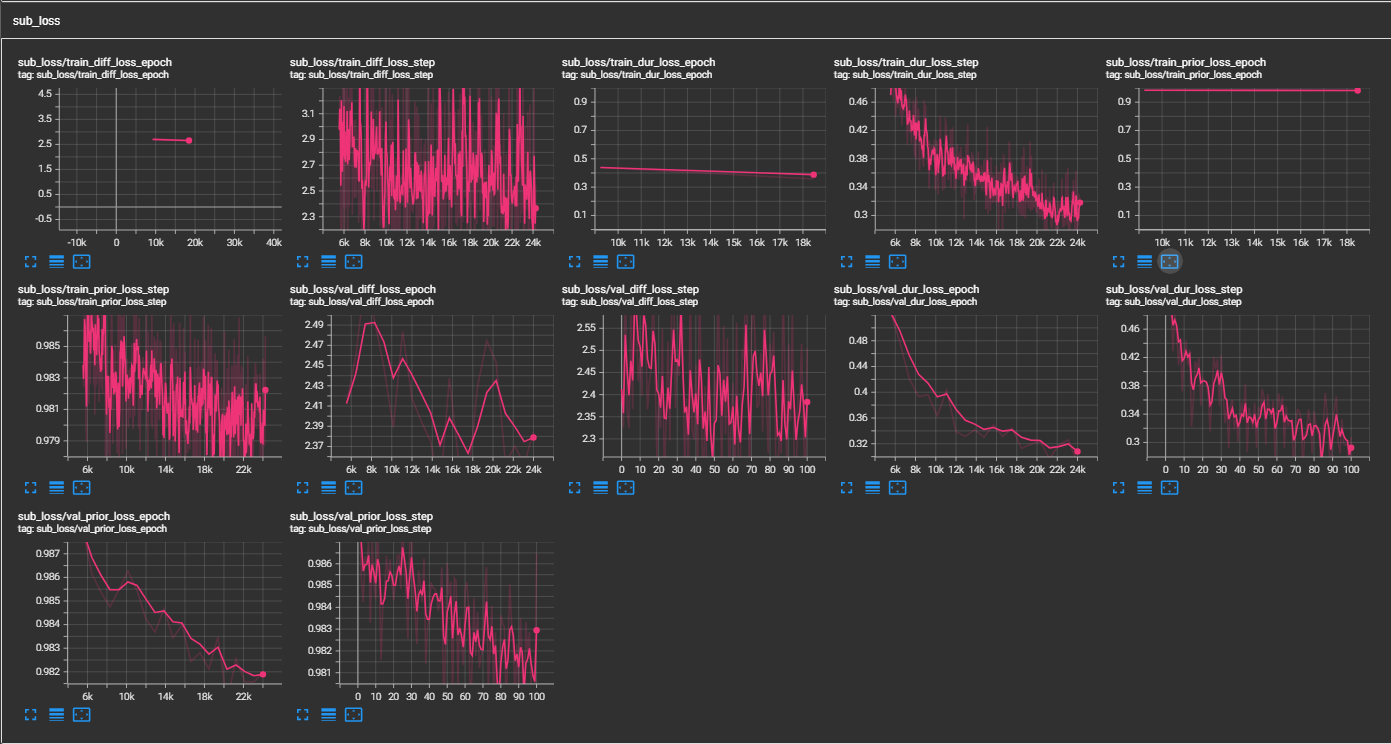
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks ,以便快速乾燥運行和模型的體系結構測試。 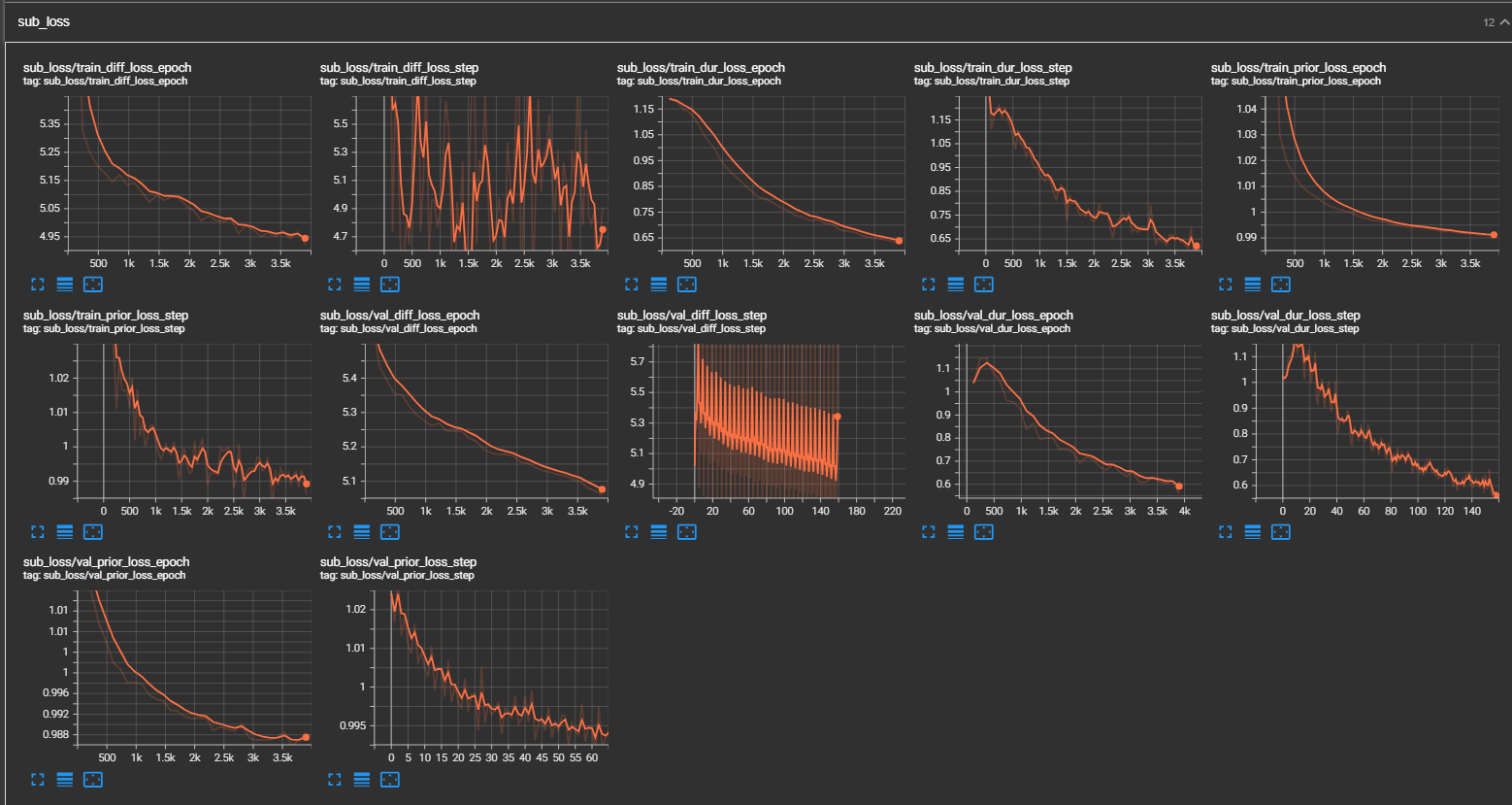
samples文件夾。 (經過30萬步的LJSpeech培訓)紙張建議800K步驟。 min_sample_size (默認為4s;因此,提示至少為3s,預測至少為1 s)prompt_size ,以控制提示的大小。它是在傳輸時用作WAV樣品的提示的MEL框架的數量。 (默認值為〜3s; 3*22050 // 256 = 258;在配置中舍入為264dur_p_use_log ,以控制是否使用持續時間預測的日誌進行損失計算。 (默認值是錯誤的)我的假設是,日誌持續時間MSE損失在更長的暫停等(由於日誌功能的性質)中無法正常工作。因此,在計算損失之前,我們只是e日誌持續時間供電。替代方法可以使用relu代替日誌。transfer_ckpt_path ,以控制用於傳輸學習的CKPT的路徑。 (默認值無)如果無,則該模型將從從頭開始訓練。如果不是,則該模型是從CKPT路徑加載並從步驟0進行訓練的。如果ckpt_path也不是沒有,則該模型是從ckpt_path加載的,並從保存的步驟中進行了訓練。 transfer_ckpt_path可以處理CKPT和模型之間的層大小不匹配。 export.py和inference.py中的參數進行導出和測試模型。 (Arguemnts是不言自明的) 

