pflowtts_pytorch
1.0.0
samples ljspeech pretrained ckpt - gdrive link multispeaker vctk pretrained ckpt (1100 Epoch on VCTK) - HuggingFaceการใช้งานอย่างไม่เป็นทางการของ Paper P-flow: TTS ที่รวดเร็วและประหยัดข้อมูลได้อย่างรวดเร็วผ่านการกระตุ้นด้วยคำพูดโดย Nvidia
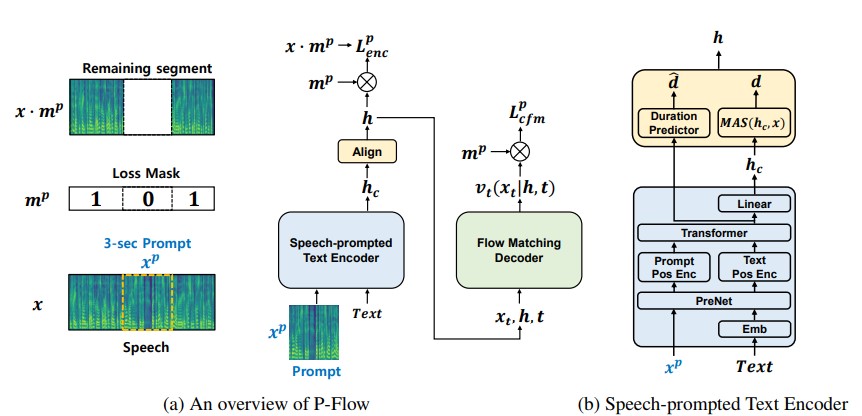
ในขณะที่โมเดลภาษาตัวแปลงสัญญาณประสาทขนาดใหญ่เมื่อเร็ว ๆ นี้ได้แสดงให้เห็นถึงการปรับปรุงอย่างมีนัยสำคัญใน TTS แบบศูนย์โดยการฝึกอบรมเกี่ยวกับข้อมูลหลายพันชั่วโมงพวกเขาประสบกับข้อเสียเช่นการขาดความทนทานความเร็วการสุ่มตัวอย่างช้าคล้ายกับวิธี TTS แบบอัตโนมัติก่อนหน้านี้ งานของเราเสนอ P-flow ซึ่งเป็นรุ่น TTS ที่รวดเร็วและประหยัดข้อมูลที่ใช้การแจ้งเตือนคำพูดสำหรับการปรับตัวลำโพง P-flow ประกอบด้วยตัวเข้ารหัสข้อความที่พูดได้สำหรับการปรับตัวของลำโพงและตัวถอดรหัสการจับคู่การไหลสำหรับการสังเคราะห์คุณภาพสูงและรวดเร็ว ตัวเข้ารหัสข้อความที่ใช้คำพูดของเราใช้พรอมต์คำพูดและอินพุตข้อความเพื่อสร้างการแสดงข้อความแบบลำโพง-เงื่อนไข ตัวถอดรหัสการจับคู่โฟลว์ใช้เอาท์พุทของลำโพง-เงื่อนไขเพื่อสังเคราะห์คำพูดส่วนบุคคลที่มีคุณภาพสูงเร็วกว่าในเวลาจริง ซึ่งแตกต่างจากโมเดลภาษาตัวแปลงสัญญาณประสาทเราฝึกอบรม P-flow บนชุดข้อมูล Libritts โดยเฉพาะโดยใช้การแสดงอย่างต่อเนื่อง ด้วยวิธีการฝึกอบรมของเราโดยใช้การแจ้งเตือนอย่างต่อเนื่อง P-flow ตรงกับประสิทธิภาพความคล้ายคลึงกันของลำโพงของรุ่น TTS Zero-shot ขนาดใหญ่ที่มีคำสั่งสองคำสั่งขนาดการฝึกอบรมน้อยลงและมีความเร็วในการสุ่มตัวอย่างเร็วกว่า 20 × ผลการศึกษาของเราแสดงให้เห็นว่า P-flow มีการออกเสียงที่ดีขึ้นและเป็นที่นิยมในภาพเหมือนของมนุษย์และความคล้ายคลึงกันของผู้พูดกับคู่หูที่ทันสมัยล่าสุดดังนั้นจึงกำหนด P-flow เป็นทางเลือกที่น่าดึงดูดและน่าพึงพอใจ
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsอยู่ในไดเรกทอรีราก (แน่นอนโคลน repo ก่อน!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceสมมติว่าเรากำลังฝึกด้วยคำพูด LJ
data/LJSpeech-1.1 และเตรียมรายการไฟล์เพื่อชี้ไปที่ข้อมูลที่แยกออกมาเช่นเดียวกับรายการ 5 ในการตั้งค่าของ Nvidia Tacotron 2 Repo 3a. ไปที่ configs/data/ljspeech.yaml และเปลี่ยน
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b. ผู้ช่วยคำสั่งสำหรับคนขี้เกียจ
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} อัปเดตค่าเหล่านี้ใน configs/data/ljspeech.yaml ภายใต้คีย์ data_statistics
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101ไปยังเส้นทางของรถไฟและผู้ตรวจสอบความถูกต้องของคุณ
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks เพื่อการทดสอบแบบแห้งอย่างรวดเร็วและการทดสอบสถาปัตยกรรมของรุ่น 
samples (LJSpeech ได้รับการฝึกฝนสำหรับขั้นตอน 300K) กระดาษแนะนำขั้นตอน 800K min_sample_size (ค่าเริ่มต้นคือ 4s; ดังนั้นพรอมต์นั้นอย่างน้อย 3s และการทำนายอย่างน้อย 1s)prompt_size ใน configs (models/pflow.yaml) เพื่อควบคุมขนาดของพรอมต์ เป็นจำนวนเฟรมเมลที่จะใช้เป็นพรอมต์จากตัวอย่าง WAV ที่ traning (ค่าเริ่มต้นคือ ~ 3s; 3*22050 // 256 = 258; ปัดเป็น 264 ในการกำหนดค่า)dur_p_use_log ใน configs (models/pflow.yaml) เพื่อควบคุมว่าจะใช้บันทึกการทำนายระยะเวลาหรือไม่สำหรับการคำนวณการสูญเสีย (ค่าเริ่มต้นเป็นเท็จในขณะนี้) สมมติฐานของฉันคือระยะเวลาบันทึกการสูญเสีย MSE ไม่ทำงานได้ดีสำหรับการหยุดพักที่ยาวนานขึ้น ฯลฯ (เนื่องจากลักษณะของฟังก์ชั่นบันทึก) ดังนั้นเราเพียงแค่ e พลังงานระยะเวลาบันทึกก่อนคำนวณการสูญเสีย วิธีทางเลือกสามารถใช้ Relu แทนบันทึกtransfer_ckpt_path ใน configs (train.yaml) เพื่อควบคุมเส้นทางของ CKPT ที่จะใช้สำหรับการเรียนรู้การถ่ายโอน (ค่าเริ่มต้นคือไม่มี) ถ้าไม่มีตัวแบบจะได้รับการฝึกฝนตั้งแต่เริ่มต้น หากไม่มีไม่มีโมเดลจะถูกโหลดจากเส้นทาง CKPT และฝึกอบรมจากขั้นตอนที่ 0 ในกรณีที่ ckpt_path ยังไม่มีเลยรุ่นนั้นจะถูกโหลดจาก ckpt_path และฝึกฝนจากขั้นตอนที่บันทึกไว้ transfer_ckpt_path สามารถจัดการขนาดเลเยอร์ไม่ตรงกันระหว่าง CKPT และโมเดล export.py และ inference.py เพื่อส่งออกและทดสอบโมเดล (arguemnts เป็นคำอธิบายตนเอง) 

