pflowtts_pytorch
1.0.0
samplesフォルダーをご覧ください。 ljspeech事前に処理されたckpt -gdriveリンクマルチスピーカーvctk事前に処理されたckpt(vctk上の1100エポック)-huggingfacePaper P-flowの非公式の実装:Nvidiaによる音声促進による高速でデータ効率の高いゼロショットTTS。
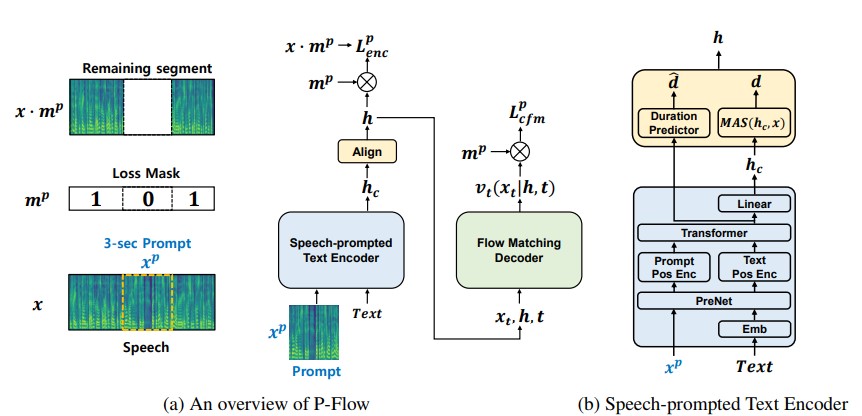
最近の大規模なニューラルコーデック言語モデルは、数千時間のデータをトレーニングすることでゼロショットTTSの大幅な改善を示していますが、堅牢性の欠如、以前の自己回帰TTS方法と同様の遅いサンプリング速度、および訓練されたニューラルコーデック表現への依存などの欠点に苦しんでいます。私たちの仕事は、スピーカーの適応に音声プロンプトを使用する高速でデータ効率の高いゼロショットTTSモデルであるP-Flowを提案しています。 P-flowは、スピーカーの適応のためのSpeechprompted Text Encoderと、高品質で高速の音声合成のためのフローに合う生成デコーダーを含む。スピーチがプロンプトしたテキストエンコーダーは、音声プロンプトとテキスト入力を使用して、スピーカーの条件付きテキスト表現を生成します。フローマッチング生成デコーダーは、スピーカーの条件付き出力を使用して、高品質のパーソナライズされた音声をリアルタイムよりも大幅に速く合成します。ニューラルコーデック言語モデルとは異なり、連続的なMEL表現を使用して、LibrittsデータセットでP-Flowを特にトレーニングします。連続音声プロンプトを使用したトレーニング方法を通じて、P-Flowは、2桁低いトレーニングデータを持つ大規模なゼロショットTTSモデルのスピーカーの類似性パフォーマンスと一致し、20倍以上のサンプリング速度を備えています。我々の結果は、P-flowがより良い発音を持ち、最近の最新のカウンターパートと人間の肖像とスピーカーの類似性で好まれていることを示しており、P-flowを魅力的で望ましい代替手段として定義しています。
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsルートディレクトリにとどまります(もちろん、最初にレポをクローンします!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceLJスピーチでトレーニングをしていると仮定しましょう
data/LJSpeech-1.1に抽出し、ファイルリストを準備して、nvidiaタコトロン2リポジトリのセットアップで項目5のような抽出されたデータを指すように準備します。 3a。 configs/data/ljspeech.yamlと変更に移動します
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b。ヘルパーコマンドは怠zyです
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574}これらの値をconfigs/data/ljspeech.yaml data_statisticsキーで更新します。
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101電車の道と検証フィルリストに。
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooksをご覧ください。 
samplesフォルダーをご覧ください。 (300Kステップで訓練されたLJSpeech)紙は800kステップを推奨しています。 min_sample_size (デフォルトは4秒)に最小WAVサンプルサイズ(秒単位)パラメーターが追加されました。prompt_sizeを追加しました。 TraningのWAVサンプルからプロンプトとして使用されるMELフレームの数です。 (デフォルトは〜3秒; 3*22050 // 256 = 258;構成で264に丸められています)dur_p_use_log構成(モデル/pflow.yaml)に追加して、損失計算に期間予測のログを使用するかどうかを制御しました。 (デフォルトは現在FALSEです)私の仮説は、ログの期間MSE損失がより長い一時停止などではうまく機能しないということです(ログ関数の性質のため)。したがって、損失を計算する前に、ログの持続時間に電力をeだけです。別の方法では、ログの代わりにreluを使用できます。transfer_ckpt_pathを追加して、転送学習に使用するCKPTのパスを制御しました。 (デフォルトはなし)なしで、モデルはゼロからトレーニングされます。いなくても、モデルはCKPTパスからロードされ、ステップ0からトレーニングされます。場合は、 ckpt_pathもありません。モデルはckpt_pathからロードされ、保存されたステップからトレーニングされます。 transfer_ckpt_path 、CKPTとモデルの間のレイヤーサイズの不一致を処理できます。 export.pyおよびinference.pyの引数を使用して、モデルをエクスポートしてテストします。 (Arguemntsは自明です) 

