pflowtts_pytorch
1.0.0
samples . ljspeech pretrained CKPT - GDrive Link Multispeaker VCTK pretRained CKPT (1100 epoch on VCTK) - Huggingfaceالتنفيذ غير الرسمي للورقة P-flow: TTS سريع وفعال للبيانات من خلال الكلام الذي يطرحه NVIDIA.
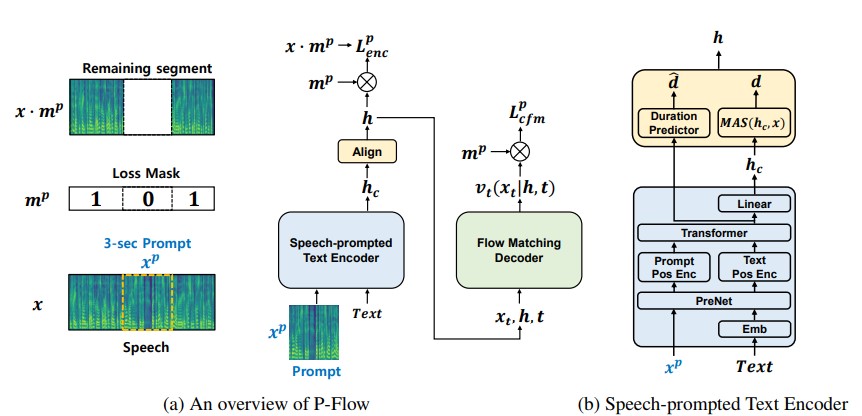
في حين أظهرت نماذج لغة الترميز العصبية على نطاق واسع على نطاق واسع تحسنًا كبيرًا في TTS صفرية من خلال التدريب على آلاف الساعات من البيانات ، فإنها تعاني من عيوب مثل عدم وجود متانة ، وسرعة أخذ العينات البطيئة مماثلة لطرق TTS التلقائية السابقة ، والاعتماد على تمثيلات الترميز العصبية قبل التدريب. يقترح عملنا P-flow ، وهو نموذج TTS سريعًا وفعالًا للبيانات ، يستخدم مطالبات الكلام لتكييف السماعة. يشتمل P-Flow على تشفير نص محترم لتكييف مكبر الصوت وفك ترميز توليدي مطابقة للتدفق لتوليف الكلام عالي الجودة والسريع. يستخدم تشفير النص الذي يحمله الكلام مطالبات الكلام ومدخلات النص لإنشاء تمثيل نص مكبر الصوت. يستخدم وحدة فك ترميز تدفق التدفق الناتج المشروط المتكبر لتوليف الكلام الشخصي عالي الجودة بشكل أسرع بكثير من الوقت الفعلي. على عكس نماذج لغة الترميز العصبية ، نقوم على وجه التحديد بتدريب P-flow على مجموعة بيانات Libritts باستخدام التمثيل المستمر. من خلال طريقة التدريب الخاصة بنا باستخدام مطالبات الكلام المستمرة ، يطابق P-Flow أداء تشابه السماعة لنماذج TTS ذات الطريق الصفر على نطاق واسع مع طلبين من بيانات تدريب أقل ويحتوي على أكثر من 20 × سرعة أخذ العينات. تظهر نتائجنا أن P-Flow لها نطق أفضل ويفضل في التشابه البشري وتشابه المتحدث مع نظيراتها الحديثة الحديثة ، وبالتالي تحديد التدفق P كبديل جذاب ومرغوب فيه.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsابق في دليل الجذر (بالطبع استنساخ الريبو أولاً!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceلنفترض أننا نتدرب مع خطاب LJ
data/LJSpeech-1.1 ، وإعداد قوائم الملف للإشارة إلى البيانات المستخرجة مثل للبند 5 في إعداد Nvidia Tacotron 2 repo. 3A. انتقل إلى configs/data/ljspeech.yaml وتغيير
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3 ب. أوامر المساعدة للكسل
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} قم بتحديث هذه القيم في configs/data/ljspeech.yaml ضمن مفتاح data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101إلى مسارات قطارك والتحقق من صحة.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks للحصول على اختبار سريع للعمارة واختبار الهندسة المعمارية للنموذج. 
samples . (LJSPEEDE المدربة على 300 كيلو خطوة) يوصي ورقة 800 كيلو خطوة. min_sample_size (الافتراضي هو 4S ؛ بحيث يكون المطالبة على الأقل 3s والتنبؤ هو 1S على الأقل)prompt_size في التكوينات (النماذج/pflow.yaml) للتحكم في حجم المطالبة. إنه عدد إطارات MEL ليتم استخدامه كمدرس من عينة WAV في Traning. (الافتراضي هو ~ 3S ؛ 3*22050 // 256 = 258 ؛ مستدير إلى 264 في التكوينات)dur_p_use_log في التكوينات (النماذج/pflow.yaml) للتحكم في استخدام سجل التنبؤ بالمدة أم لا لحساب الخسارة. (الافتراضي هو خطأ الآن) فرضيتي هي أن فترات السجل MSE لا تعمل بشكل جيد للتوقف لفترة أطول وما إلى ذلك (بسبب طبيعة وظيفة السجل). لذلك ، نحن فقط e تشغيل فترات السجل قبل حساب الخسارة. يمكن أن تستخدم طريقة بديلة RELU بدلاً من السجل.transfer_ckpt_path في التكوينات (Train.yaml) للتحكم في مسار CKPT لاستخدامه في التعلم النقل. (الافتراضي هو لا شيء) إذا لم يكن هناك أي شيء ، فسيتم تدريب النموذج من الصفر. إذا لم يكن أي شيء ، فسيتم تحميل النموذج من مسار CKPT وتدريبه من الخطوة 0. في حال ، ليس ckpt_path أيضًا لا شيء ، ثم يتم تحميل النموذج من ckpt_path وتدريبه من الخطوة التي تم حفظها في. يمكن transfer_ckpt_path التعامل مع عدم تطابق حجم الطبقة بين CKPT والنموذج. export.py و inference.py لتصدير واختبار النموذج. (الجثثون تفسخ ذاتيا) 

