pflowtts_pytorch
1.0.0
samples . LJSPEECH PRENTELIADO CKPT - LING MULTISPEAKER VCTK PRENTELIADO CKPT (1100 Epoch no VCTK) - HuggingfaceImplementação não oficial do documento P-FLOW: Um TTS de tiro zero rápido e eficiente em termos de dados através da fala da NVIDIA.
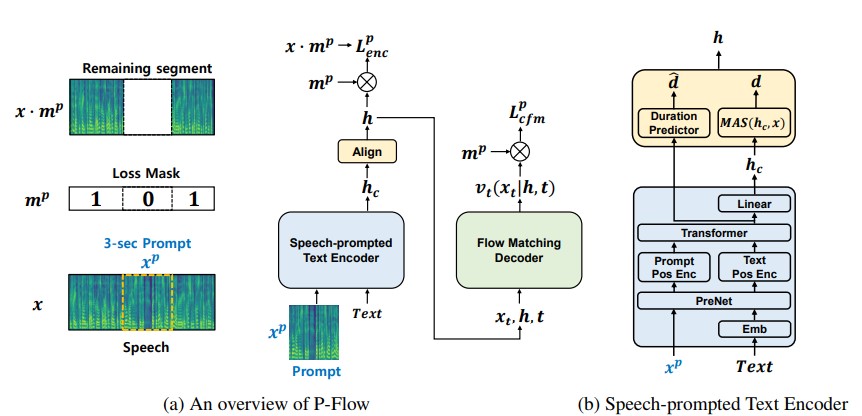
Embora os recentes modelos de idiomas de codec neural em larga escala tenham mostrado uma melhora significativa no TTS zero, treinando milhares de horas de dados, eles sofrem de desvantagens, como falta de robustez, velocidade de amostragem lenta semelhante aos métodos autorregressivos anteriores e dependência de representações de codec neural pré-treinadas. Nosso trabalho propõe o Flow P, um modelo TTS zero rápido e com eficiência de dados que usa avisos de fala para adaptação ao alto-falante. O Flow P compreende um codificador de texto promovido a fala para adaptação ao alto-falante e um decodificador generativo que corresponda ao fluxo para a síntese de alta qualidade e rápida da fala. Nosso codificador de texto promovido a fala usa prompts de fala e entrada de texto para gerar representação de texto condicional do alto-falante. O decodificador generativo de correspondência de fluxo usa a saída condicional do alto-falante para sintetizar discurso personalizado de alta qualidade significativamente mais rápido do que em tempo real. Ao contrário dos modelos de idiomas do codec neural, treinamos especificamente o conjunto de dados P-FLOW no Libritts usando uma representação contínua de MEL. Através do nosso método de treinamento usando instruções contínuas de fala, o Flow P corresponde ao desempenho da similaridade do alto-falante dos modelos TTS zero tiro zero em larga escala com duas ordens de magnitude menos dados de treinamento e possui mais de 20 × velocidade de amostragem mais rápida. Nossos resultados mostram que o fluxo P tem melhor pronúncia e é preferido na semelhança humana e na semelhança do alto-falante com suas recentes contrapartes de ponta, definindo assim o fluxo P como uma alternativa atraente e desejável.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsFique no diretório raiz (é claro que clone o repo primeiro!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceVamos supor que estamos treinando com o discurso de LJ
data/LJSpeech-1.1 e prepare as listas de arquivos para apontar para os dados extraídos, como para o item 5 na configuração do repo NVIDIA Tacotron 2. 3a. Vá para configs/data/ljspeech.yaml e altere
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3b. Comandos auxiliares para os preguiçosos
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Atualize esses valores nas configs/data/ljspeech.yaml na tecla data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101para os caminhos dos seus filmes de trem e validação.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks para uma rápida execução a seco e testes de arquitetura do modelo. 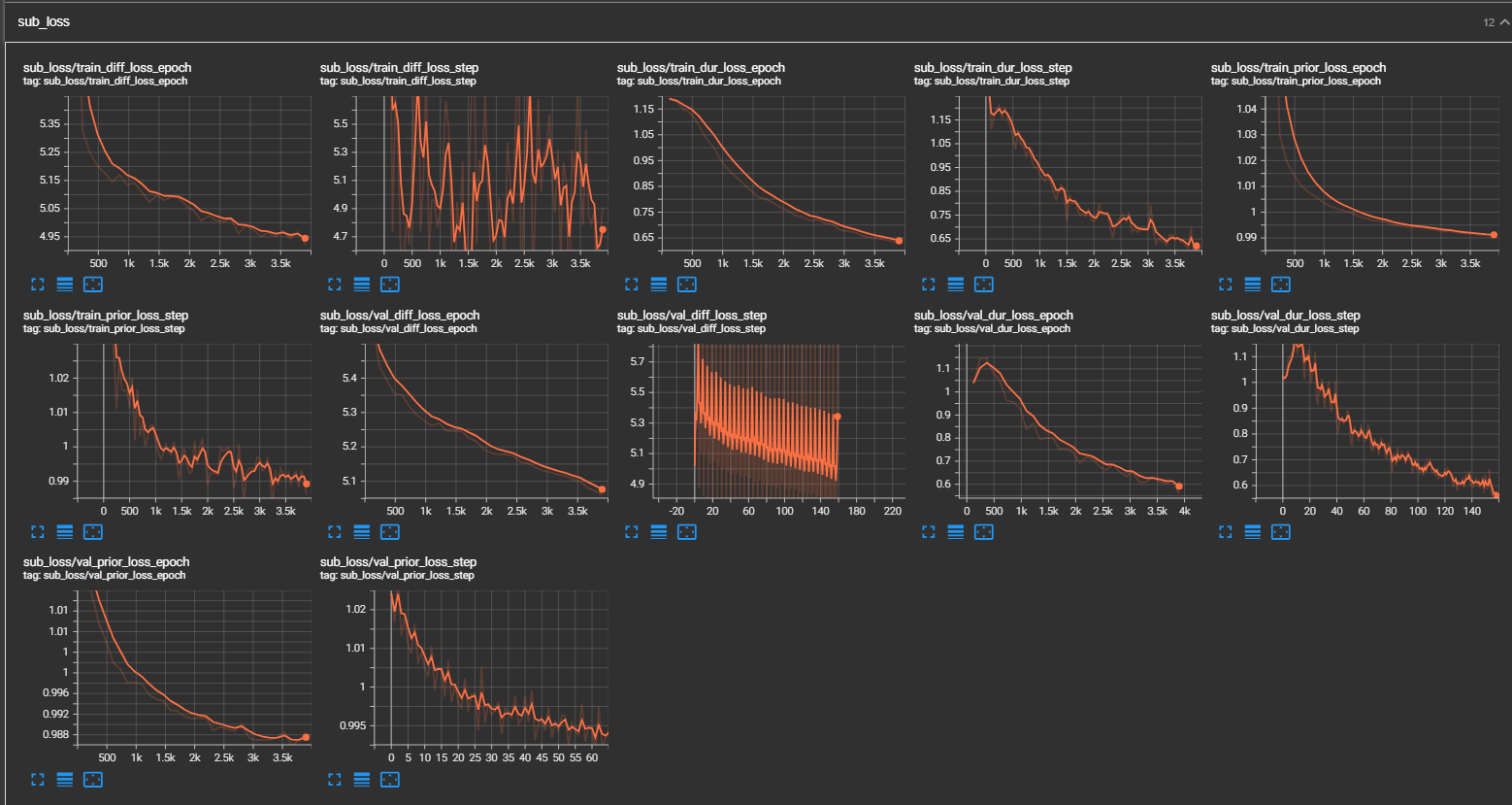
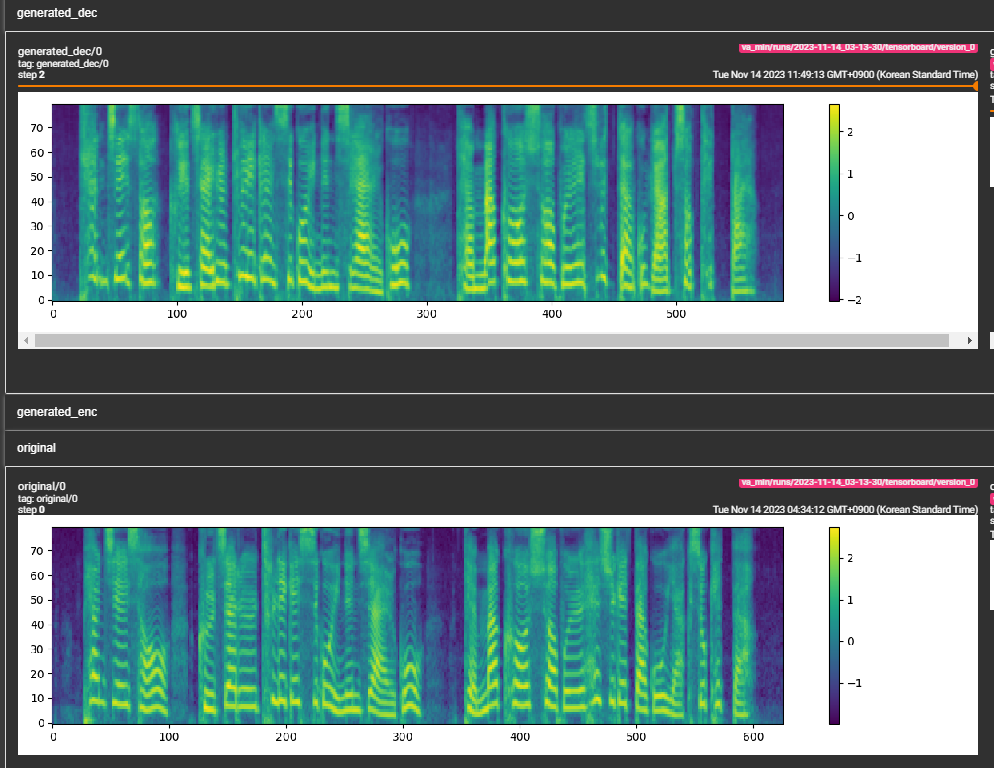
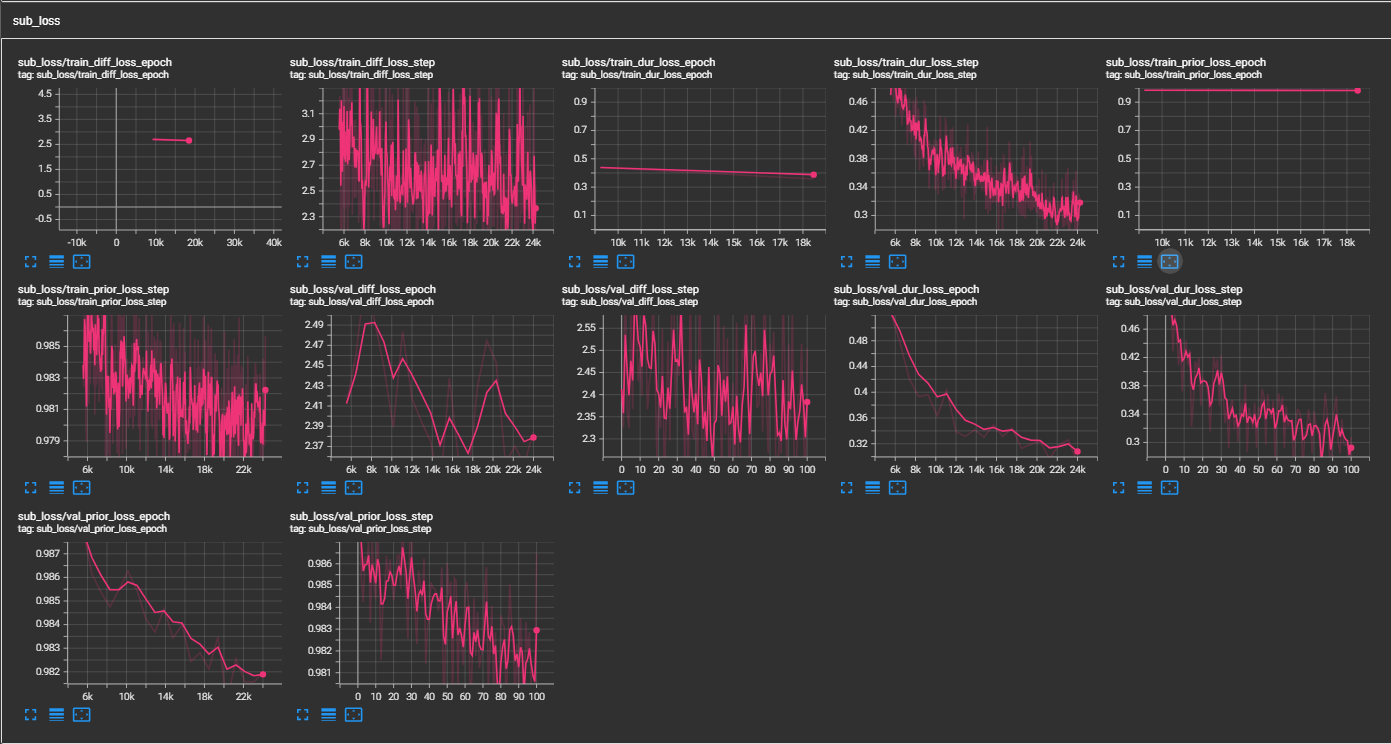
samples . (LJSpeech treinado para 300 mil etapas) O papel recomenda 800 mil etapas. min_sample_size (o padrão é 4s; de modo que o prompt é pelo menos 3s e a previsão é de pelo menos 1s)prompt_size nas configurações (modelos/pflow.yaml) para controlar o tamanho do prompt. É o número de quadros MEL a ser usado como prompt da amostra WAV em Traning. (o padrão é ~ 3s; 3*22050 // 256 = 258; arredondado para 264 em configurações)dur_p_use_log nas configurações (modelos/pflow.yaml) para controlar se o uso da previsão da duração ou não para o cálculo da perda. (O padrão é falso agora) Minha hipótese é que a perda de Durações de log não funciona bem para pausas mais longas etc (devido à natureza da função de log). Portanto, apenas e as durações do log antes de calcular a perda. A maneira alternativa pode estar usando relu em vez de log.transfer_ckpt_path nas configurações (trens.yaml) para controlar o caminho do CKPT a ser usado para o aprendizado de transferência. (o padrão é nenhum) Se não for nenhum, então o modelo é treinado do zero. Caso contrário, o modelo é carregado a partir do caminho CKPT e treinado na etapa 0. Caso ckpt_path também não é nenhum, o modelo é carregado de ckpt_path e treinado a partir da etapa em que foi salvo. transfer_ckpt_path pode lidar com as incompatibilidades do tamanho da camada entre o CKPT e o modelo. export.py e inference.py para exportar e testar o modelo. (Os argumentos são auto-explicativos) 

