pflowtts_pytorch
1.0.0
samples . LJSPEECH CKPT Pretraind - GDrive Link Multippeaker VCTK CKPT prétrainé (1100 Epoch sur VCTK) - HuggingFaceImplémentation non officielle du papier P-Flow: un TTS zéro-shot rapide et économe en données par le biais de la parole par NVIDIA.
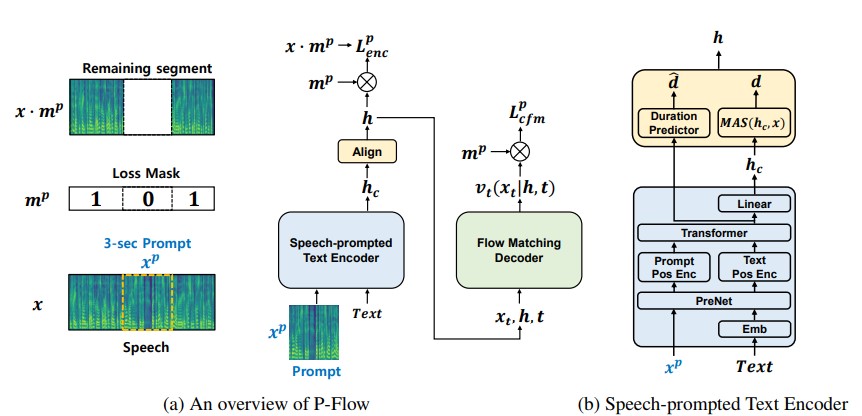
Bien que les récents modèles de langage de codec neural à grande échelle aient montré une amélioration significative des TTS zéro en s'entraînant sur des milliers de données, ils souffrent d'inconvénients tels que le manque de robustesse, la vitesse d'échantillonnage lente similaire aux méthodes TTS autorégressives précédentes et la dépendance à l'égard des représentations de codec neural pré-entraînées. Notre travail propose P-Flow, un modèle TTS zéro-shot rapide et économe en données qui utilise des invites de parole pour l'adaptation des haut-parleurs. P-Flow comprend un encodeur de texte composé de parole pour l'adaptation des locuteurs et un décodeur génératif correspondant à l'écoulement pour la synthèse de la parole de haute qualité et rapide. Notre encodeur de texte compliqué par la parole utilise des invites de parole et une entrée de texte pour générer une représentation de texte conditionnelle en haut-parleur. Le décodeur génératif correspondant à l'écoulement utilise la sortie conditionnelle du haut-parleur pour synthétiser la parole personnalisée de haute qualité nettement plus rapide qu'en temps réel. Contrairement aux modèles de langage de codec neural, nous formons spécifiquement le flux P sur les libritts en utilisant une représentation MEL continue. Grâce à notre méthode d'entraînement en utilisant des invites de parole continues, P-Flow correspond aux performances de similitude des haut-parleurs des modèles TTS à grande échelle avec deux ordres de données de magnitude et a plus de 20 × vitesse d'échantillonnage plus rapide. Nos résultats montrent que P-Flow a une meilleure prononciation et est préféré dans la ressemblance humaine et la similitude des orateurs avec ses récents homologues de pointe, définissant ainsi le P-Flow comme une alternative attrayante et souhaitable.
cd pflowtts_pytorch/notebooks import sys
sys . path . append ( '..' )
from pflow . models . pflow_tts import pflowTTS
import torch
from dataclasses import dataclass
@ dataclass
class DurationPredictorParams :
filter_channels_dp : int
kernel_size : int
p_dropout : float
@ dataclass
class EncoderParams :
n_feats : int
n_channels : int
filter_channels : int
filter_channels_dp : int
n_heads : int
n_layers : int
kernel_size : int
p_dropout : float
spk_emb_dim : int
n_spks : int
prenet : bool
@ dataclass
class CFMParams :
name : str
solver : str
sigma_min : float
# Example usage
duration_predictor_params = DurationPredictorParams (
filter_channels_dp = 256 ,
kernel_size = 3 ,
p_dropout = 0.1
)
encoder_params = EncoderParams (
n_feats = 80 ,
n_channels = 192 ,
filter_channels = 768 ,
filter_channels_dp = 256 ,
n_heads = 2 ,
n_layers = 6 ,
kernel_size = 3 ,
p_dropout = 0.1 ,
spk_emb_dim = 64 ,
n_spks = 1 ,
prenet = True
)
cfm_params = CFMParams (
name = 'CFM' ,
solver = 'euler' ,
sigma_min = 1e-4
)
@ dataclass
class EncoderOverallParams :
encoder_type : str
encoder_params : EncoderParams
duration_predictor_params : DurationPredictorParams
encoder_overall_params = EncoderOverallParams (
encoder_type = 'RoPE Encoder' ,
encoder_params = encoder_params ,
duration_predictor_params = duration_predictor_params
)
@ dataclass
class DecoderParams :
channels : tuple
dropout : float
attention_head_dim : int
n_blocks : int
num_mid_blocks : int
num_heads : int
act_fn : str
decoder_params = DecoderParams (
channels = ( 256 , 256 ),
dropout = 0.05 ,
attention_head_dim = 64 ,
n_blocks = 1 ,
num_mid_blocks = 2 ,
num_heads = 2 ,
act_fn = 'snakebeta' ,
)
model = pflowTTS (
n_vocab = 100 ,
n_feats = 80 ,
encoder = encoder_overall_params ,
decoder = decoder_params . __dict__ ,
cfm = cfm_params ,
data_statistics = None ,
)
x = torch . randint ( 0 , 100 , ( 4 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 4 ,))
y = torch . randn ( 4 , 80 , 500 )
y_lengths = torch . randint ( 300 , 500 , ( 4 ,))
dur_loss , prior_loss , diff_loss , attn = model ( x , x_lengths , y , y_lengths )
# backpropagate the loss
# now synthesises
x = torch . randint ( 0 , 100 , ( 1 , 20 ))
x_lengths = torch . randint ( 10 , 20 , ( 1 ,))
y_slice = torch . randn ( 1 , 80 , 264 )
model . synthesise ( x , x_lengths , y_slice , n_timesteps = 10 )conda create -n pflowtts python=3.10 -y
conda activate pflowttsRestez dans le répertoire racine (bien sûr cloner le repo d'abord!)
cd pflowtts_pytorch
pip install -r requirements.txt # Cython-version Monotonoic Alignment Search
python setup.py build_ext --inplaceSupposons que nous nous entraînons avec le discours LJ
data/LJSpeech-1.1 et préparez les listes de fichiers pour pointer des données extraites comme pour l'élément 5 dans la configuration du repo Nvidia Tacotron 2. 3A. Allez dans configs/data/ljspeech.yaml et modifiez
train_filelist_path : data/filelists/ljs_audio_text_train_filelist.txt
valid_filelist_path : data/filelists/ljs_audio_text_val_filelist.txt3B. Commandes d'assistance pour le paresseux
! mkdir -p /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_test_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_test_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_train_filelist.txt
! wget -O /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt https://raw.githubusercontent.com/NVIDIA/tacotron2/master/filelists/ljs_audio_text_val_filelist.txt
! sed -i -- ' s,DUMMY,/home/ubuntu/LJSpeech/LJSpeech-1.1/wavs,g ' /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ * .txt
! sed -i -- ' s,train_filelist_path: data/filelists/ljs_audio_text_train_filelist.txt,train_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_train_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml
! sed -i -- ' s,valid_filelist_path: data/filelists/ljs_audio_text_val_filelist.txt,valid_filelist_path: /home/ubuntu/LJSpeech/LJSpeech-1.1/filelists/ljs_audio_text_val_filelist.txt,g ' /home/ubuntu/LJSpeech/pflowtts_pytorch/configs/data/ljspeech.yaml cd pflowtts_pytorch/pflow/utils
python generate_data_statistics.py -i ljspeech.yaml
# Output:
#{ ' mel_mean ' : -5.53662231756592, ' mel_std ' : 2.1161014277038574} Mettez à jour ces valeurs dans configs/data/ljspeech.yaml sous la clé data_statistics .
data_statistics: # Computed for ljspeech dataset
mel_mean: -5.536622
mel_std: 2.116101aux chemins de votre train et valites de validation.
python pflow/train.py experiment=ljspeechpython pflow/train.py experiment=ljspeech trainer.devices=[0,1]notebooks pour une course à sec et des tests d'architecture du modèle. 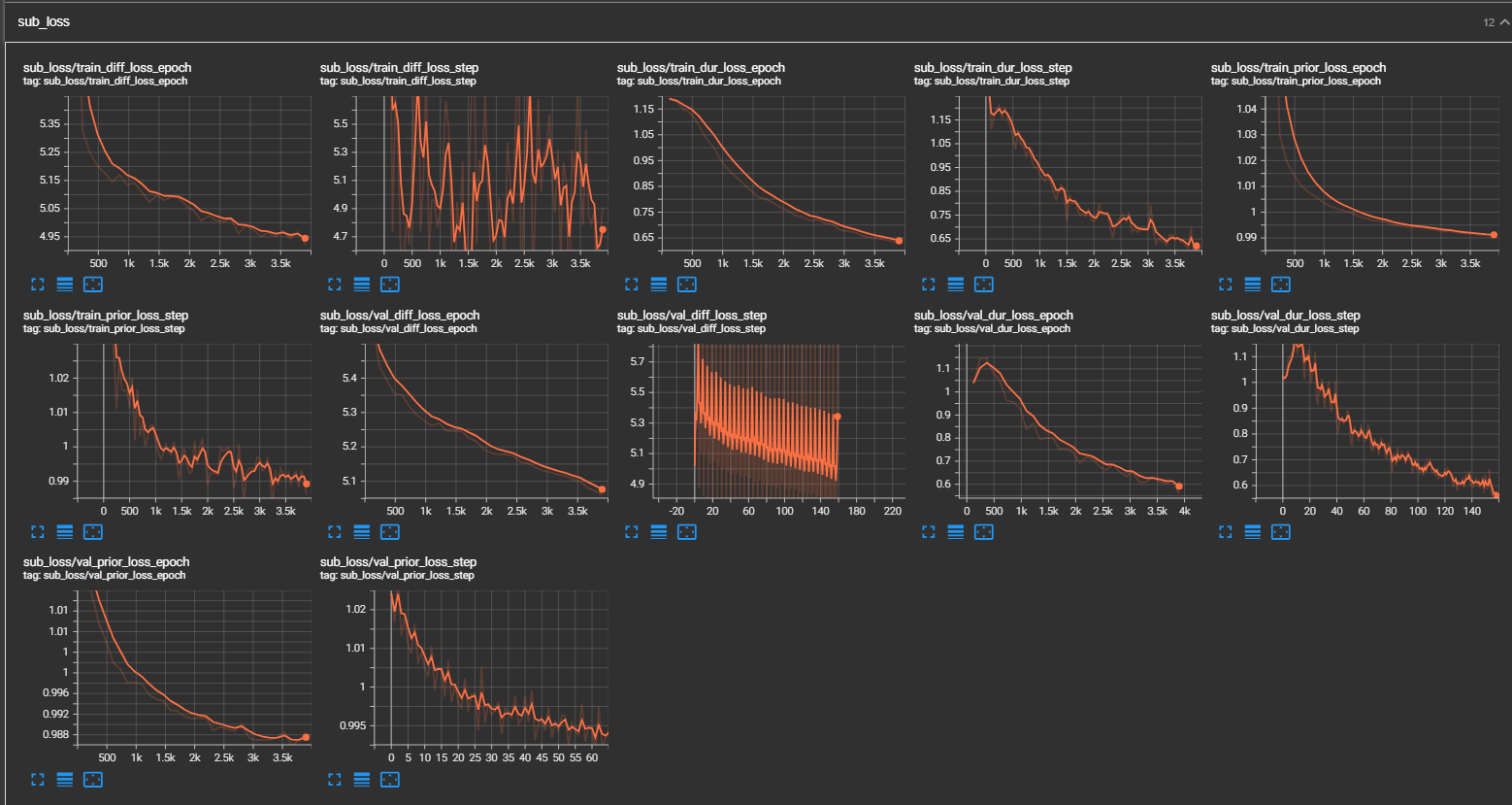
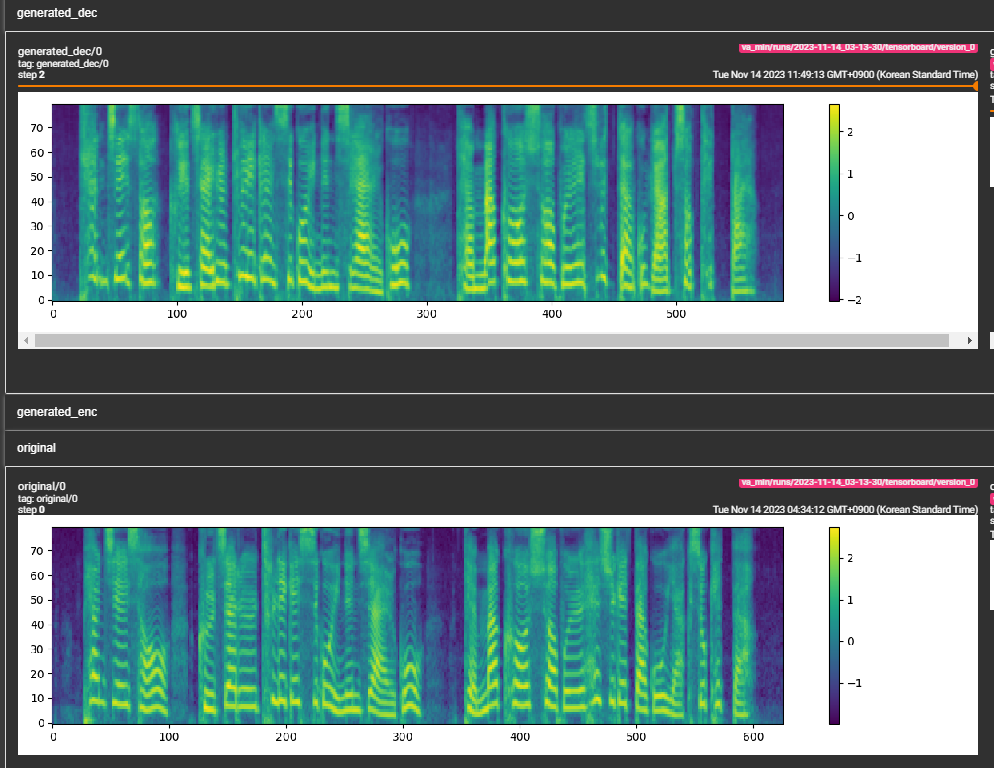
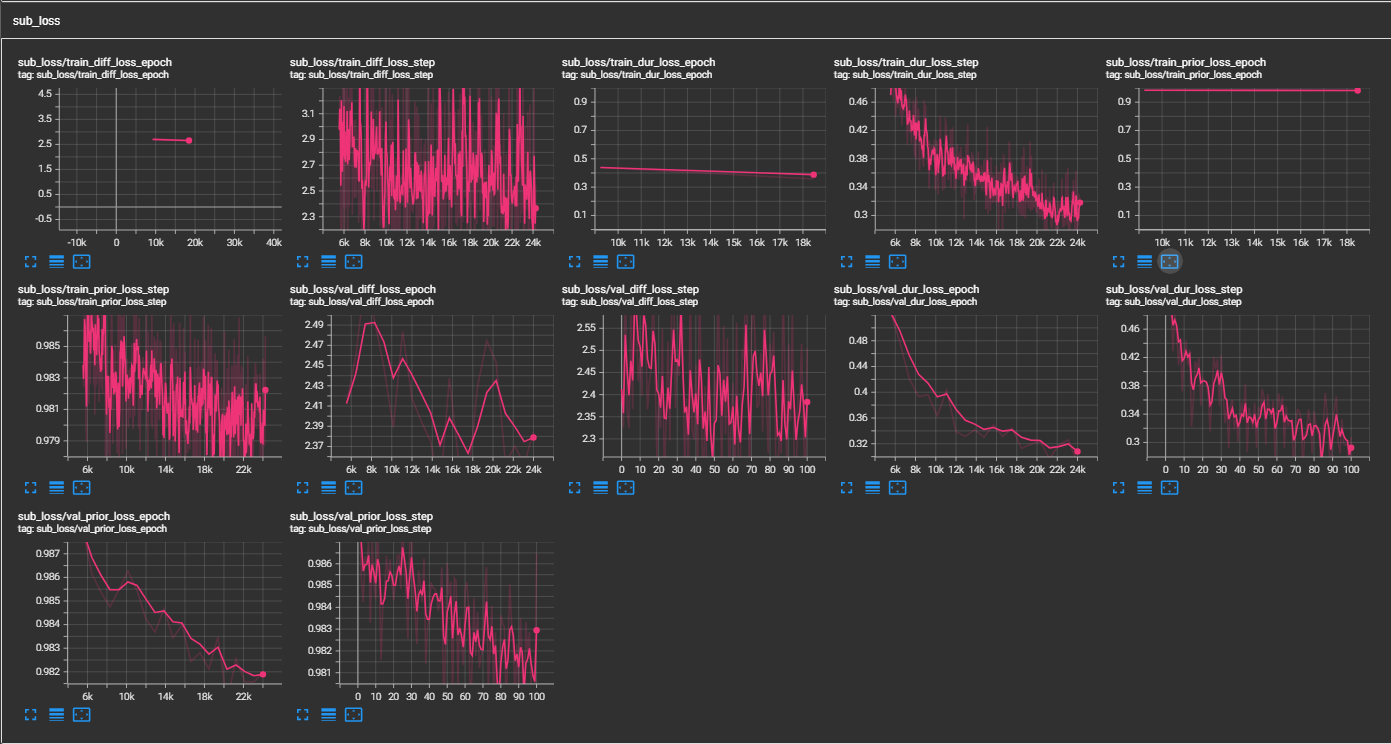
samples . (LJSPEECH formé pour 300 000 étapes) Le papier recommande 800 000 étapes. min_sample_size (par défaut est 4S; de sorte que l'invite est au moins 3s et la prédiction est au moins 1S)prompt_size dans les configurations (modèles / pflow.yaml) pour contrôler la taille de l'invite. Il s'agit du nombre de trames MEL à utiliser comme invite à partir de l'échantillon WAV au transition. (la valeur par défaut est ~ 3s; 3 * 22050 // 256 = 258; arrondi à 264 en configs)dur_p_use_log dans les configts (modèles / pflow.yaml) pour contrôler s'il faut utiliser le journal de la prédiction de durée ou non pour le calcul de la perte. (la valeur par défaut est fausse maintenant) Mon hypothèse est que les durées de logarition ne fonctionnent pas bien pour des pauses plus longues, etc. (en raison de la nature de la fonction logarithmique). Donc, nous e simplement alimenté les durées de log avant de calculer la perte. Une manière alternative peut être d'utiliser relu au lieu du journal.transfer_ckpt_path dans les configts (train.yaml) pour contrôler le chemin du CKPT à utiliser pour l'apprentissage du transfert. (la valeur par défaut n'est pas) Si aucune, alors le modèle est entraîné à partir de zéro. Si ce n'est pas le cas, le modèle est chargé à partir du chemin CKPT et entraîné à partir de l'étape 0. Au cas où, ckpt_path n'est pas non plus nulle, alors le modèle est chargé à partir de ckpt_path et formé à partir de l'étape dans laquelle il a été enregistré. transfer_ckpt_path peut gérer les décalages de taille de couche entre le CKPT et le modèle. export.py et inference.py pour exporter et tester le modèle. (Les arguments sont explicites) 

